

Introduzione alla tecnica di apprendimento profondo
La tecnica di apprendimento profondo si basa su reti neurali artificiali che agiscono come un cervello umano. Imita il modo in cui il cervello umano pensa e si esibisce. In questo modello, il sistema apprende ed esegue la classificazione da immagini, testo o suono. I modelli di apprendimento profondo sono formati da grandi dati etichettati e multistrato per ottenere un'elevata precisione nel risultato anche più del livello umano. L'auto senza conducente applica questa tecnologia per identificare segnali di stop, pedoni, ecc. Nella locomozione. I gadget elettronici come cellulari, altoparlanti, TV, computer, ecc. Hanno una funzione di controllo vocale grazie al Deep Learning. Questa tecnica è nuova ed efficiente per i consumatori e le organizzazioni.
Funzionamento dell'apprendimento profondo
I metodi di apprendimento profondo utilizzano reti neurali. Pertanto, vengono spesso definiti reti neurali profonde. Le reti neurali profonde o nascoste hanno più livelli nascosti di reti profonde. Deep Learning forma l'IA per prevedere l'output con l'aiuto di determinati input o livelli di rete nascosti. Queste reti sono addestrate da set di dati di grandi dimensioni e apprendono le funzionalità dai dati stessi. Sia l'apprendimento supervisionato che quello non supervisionato funzionano nella formazione dei dati e nella generazione di funzionalità.
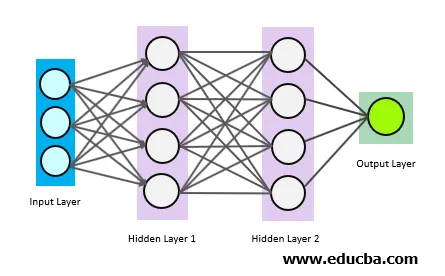
I cerchi sopra sono neuroni che sono interconnessi. Esistono 3 tipi di neuroni:
- Strato di input
- Strato / i nascosto / i
- Strato di output
Il livello di input ottiene i dati di input e passa l'input al primo livello nascosto. I calcoli matematici vengono eseguiti sui dati di input. Infine, lo strato di output fornisce i risultati.
La CNN o le reti neurali convenzionali, una delle reti neurali più popolari, comprende le funzionalità apprese dai dati di input e utilizza i livelli convoluzionali 2D per renderlo adatto all'elaborazione di dati 2D come le immagini. Pertanto, la CNN riduce l'uso dell'estrazione manuale delle funzionalità in questo caso. Estrae direttamente le caratteristiche richieste dalle immagini per la classificazione. Grazie a questa funzionalità di automazione, la CNN è un algoritmo per lo più accurato e affidabile in Machine Learning. Ogni CNN apprende le caratteristiche delle immagini dal livello nascosto e questi livelli nascosti aumentano la complessità delle immagini apprese.
L'importante è addestrare l'IA o le reti neurali. Per fare ciò, forniamo input dal set di dati e infine facciamo un confronto degli output con l'aiuto dell'output del set di dati. Se l'IA non è addestrato, l'output potrebbe essere errato.
Per scoprire quanto è sbagliato l'output dell'IA dall'output reale, abbiamo bisogno di una funzione per il calcolo. La funzione si chiama funzione di costo. Se la funzione di costo è zero, sia l'output AI sia l'output reale sono uguali. Per ridurre il valore della funzione di costo, cambiamo i pesi tra i neuroni. Per un approccio conveniente, è possibile utilizzare una tecnica chiamata Discesa a gradiente. GD riduce il peso dei neuroni al minimo dopo ogni iterazione. Questo processo viene eseguito automaticamente.
Tecnica di apprendimento profondo
Gli algoritmi di Deep Learning attraversano diversi livelli dei livelli nascosti o delle reti neurali. Quindi, imparano a fondo le immagini per una previsione accurata. Ogni livello apprende e rileva funzionalità di basso livello come i bordi e, successivamente, il nuovo livello si fonde con le funzionalità del livello precedente per una migliore rappresentazione. Ad esempio, un livello intermedio potrebbe rilevare qualsiasi bordo dell'oggetto mentre il livello nascosto rileverà l'intero oggetto o immagine.
Questa tecnica è efficiente con dati grandi e complessi. Se i dati sono piccoli o incompleti, DL diventa incapace di lavorare con nuovi dati.
Esistono alcune reti di apprendimento profondo come segue:
- Rete pre-addestrata senza supervisione : è un modello base con 3 livelli: livello input, nascosto e output. La rete viene addestrata per ricostruire l'input e quindi i livelli nascosti imparano dagli input per raccogliere informazioni e, infine, le funzionalità vengono estratte dall'immagine.
- Rete neurale convenzionale : come rete neurale standard, ha una convoluzione interna per il rilevamento dei bordi e il riconoscimento accurato degli oggetti.
- Rete neurale ricorrente : in questa tecnica, l'output dello stadio precedente viene utilizzato come input per lo stadio successivo o corrente. RNN memorizza le informazioni nei nodi di contesto per apprendere i dati di input e produrre l'output. Ad esempio, per completare una frase abbiamo bisogno di parole. cioè per predire la parola successiva, sono necessarie parole precedenti che devono essere ricordate. RNN sostanzialmente risolve questo tipo di problema.
- Reti neurali ricorsive : è un modello gerarchico in cui l'input è una struttura ad albero. Questo tipo di rete viene creata applicando lo stesso set di pesi sull'assemblaggio di input.
Il Deep Learning ha una varietà di applicazioni in campi finanziari, visione artificiale, riconoscimento audio e vocale, analisi di immagini mediche, tecniche di progettazione di farmaci, ecc.
Come creare modelli di apprendimento profondo?
Gli algoritmi di deep learning sono realizzati collegando i livelli tra di loro. Il primo passaggio sopra è il livello di input seguito dai livelli nascosti e dal livello di output. Ogni strato è composto da neuroni interconnessi. La rete consuma una grande quantità di dati di input per gestirli attraverso più livelli.
Per creare un modello di apprendimento profondo, sono necessari i seguenti passaggi:
- Comprensione del problema
- Identificare i dati
- Seleziona l'algoritmo
- Allena il modello
- Prova il modello
L'apprendimento avviene in due fasi
- Applicare una trasformazione non lineare dei dati di input e creare un modello statistico come output.
- Il modello è stato migliorato con un metodo derivato.
Queste due fasi operative sono note come iterazione. Le reti neurali ripetono i due passaggi fino a quando non vengono generati l'output e la precisione desiderati.
1. Formazione delle reti: per formare una rete di dati, raccogliamo un gran numero di dati e progettiamo un modello che apprenderà le funzionalità. Ma il processo è più lento in caso di un numero molto elevato di dati.
2. Transfer Learning: Transfer Learning sostanzialmente modifica un modello pre-addestrato e successivamente viene eseguita una nuova attività. In questo processo, il tempo di calcolo diminuisce.
3. Estrazione delle caratteristiche: dopo che tutti i livelli sono stati addestrati sulle caratteristiche dell'oggetto, le caratteristiche vengono estratte da esso e l'output è previsto con precisione.
Conclusione
Il deep learning è un sottoinsieme di ML e ML è un sottoinsieme di AI. Tutte e tre le tecnologie e i modelli hanno un impatto enorme sulla vita reale. Entità aziendali, giganti commerciali stanno implementando modelli di apprendimento profondo per risultati superiori e comparabili per l'automazione che si ispira al cervello umano.
Articoli consigliati
Questa è una guida alla tecnica di apprendimento profondo. Qui discutiamo come creare modelli di apprendimento profondo insieme alle due fasi operative. Puoi anche consultare i seguenti articoli per saperne di più -
- Che cos'è l'apprendimento profondo
- Carriere negli apprendimenti profondi
- 13 domande e risposte utili di intervista di apprendimento profondo
- Apprendimento automatico iperparametro