
Introduzione agli Autoencoder
È il caso della rete neurale artificiale utilizzata per scoprire una codifica dei dati efficace in modo incustodito. L'obiettivo di Autoencoder viene utilizzato per apprendere la presentazione di un gruppo di dati, in particolare per la riduzione dimensionale della dimensionalità. Gli autocodificatori hanno una caratteristica unica in cui il loro input è uguale al suo output formando reti di feedforwarding. Il codificatore automatico trasforma l'ingresso in dati compressi per formare un codice a bassa dimensione e quindi ripercorre nuovamente l'input per formare l'output desiderato. Il codice di input compresso è anche chiamato rappresentazione dello spazio latente. In parole semplici, l'obiettivo principale è ridurre la distorsione tra i circuiti.
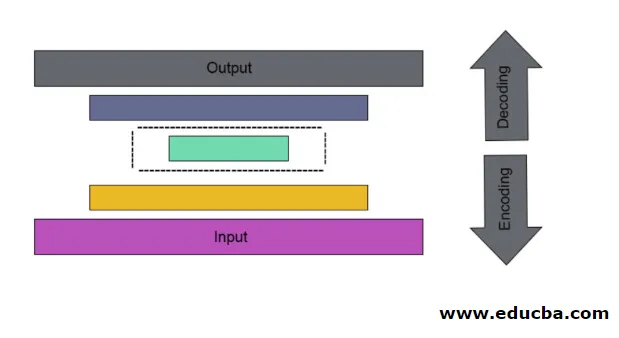
Ci sono tre componenti principali in Autoencoder. Sono Encoder, Decoder e Code. L'encoder e il decoder sono completamente collegati per formare una rete di inoltro di feed. Il codice agisce come un singolo livello che funge da dimensione propria. Per sviluppare un codificatore automatico, è necessario impostare un iperparametro, ovvero impostare il numero di nodi nel livello principale. In modo più dettagliato, la rete di uscita del decodificatore è un'immagine speculare dell'encoder di ingresso. Il decodificatore produce l'output desiderato solo con l'aiuto del livello di codice.
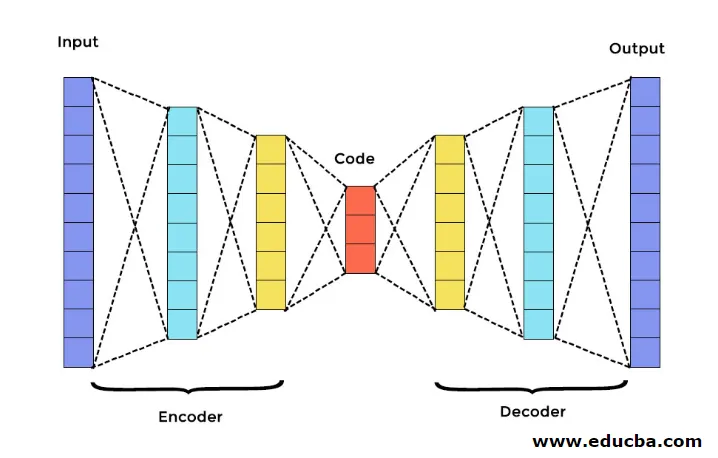
Assicurarsi che encoder e decoder abbiano gli stessi valori dimensionali. Il parametro importante per impostare il codificatore automatico è la dimensione del codice, il numero di livelli e il numero di nodi in ciascun livello.
La dimensione del codice è definita dalla quantità totale di nodi presenti nel livello intermedio. Per ottenere una compressione efficace, è consigliabile la dimensione ridotta di uno strato intermedio. Il numero di strati in autoencoder può essere profondo o superficiale a piacere. Il numero di nodi nell'autoencoder dovrebbe essere lo stesso sia nell'encoder che nel decoder. Lo strato di decoder ed encoder deve essere simmetrico.
Nel codificatore automatico impilato, hai un livello invisibile sia nel codificatore che nel decodificatore. Si compone di immagini scritte a mano con una dimensione di 28 * 28. Ora puoi sviluppare il codificatore automatico con 128 nodi nel livello invisibile con 32 come dimensione del codice. Per aggiungere molti numeri di livelli, utilizzare questa funzione
model.add(Dense(16, activation='relu'))
model.add(Dense(8, activation='relu'))
per conversione,
layer_1 = Dense(16, activation='relu')(input)
layer_2 = Dense(8, activation='relu')(layer_1)
Ora l'output di questo layer viene aggiunto come input al layer successivo. questo è il livello richiamabile in questo metodo denso. Il decodificatore svolge questa funzione. Utilizza il metodo sigmoid per ottenere un output compreso tra 0 e 1. Poiché l'ingresso è compreso tra 0 e 1

La ricostruzione dell'input da parte di un codificatore automatico in questo metodo viene eseguita per previsione. Viene eseguito il test dell'immagine individuale e l'output non è esattamente come input ma simile come input. Per superare queste difficoltà, è possibile rendere più efficiente il codificatore automatico aggiungendo molti livelli e aggiungendo più nodi ai livelli. Ma rendendolo più potente, si ottiene una copia dei dati simile all'input. Ma questo non è il risultato atteso.
Architettura di Autoencoder
In questa architettura impilata, il livello di codice ha un valore dimensionale ridotto rispetto alle informazioni di input, in cui si dice che sia sotto il codificatore automatico.
1. Denoising Autoencoders
In questo metodo, non è possibile copiare il segnale di ingresso nel segnale di uscita per ottenere il risultato perfetto. Perché qui il segnale di input contiene rumore che deve essere sottratto prima di ottenere il risultato che è i dati sottostanti necessari. Questo processo è chiamato denoising autoencoder. La prima riga contiene immagini originali. Per renderli segnale di ingresso rumoroso vengono aggiunti alcuni dati rumorosi. Ora è possibile progettare il codificatore automatico per ottenere un'uscita priva di disturbi come segue
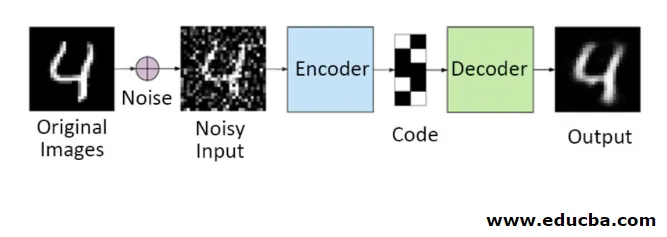
autoencoder.fit(x_train, x_train)
Un codificatore automatico modificato è il seguente,
autoencoder.fit(x_train_noisy, x_train)
Quindi è possibile ottenere facilmente un'uscita senza rumore.
L'autocodificatore a convoluzione viene utilizzato per gestire segnali complessi e ottenere anche un risultato migliore rispetto al normale processo
2. Autoencoders sparsi
Per utilizzare in modo efficace i codificatori automatici, è possibile seguire due passaggi.
Imposta una piccola dimensione del codice e l'altro sta denunciando il codificatore automatico.
Quindi un altro metodo efficace è la regolarizzazione. Per applicare questa regolarizzazione, è necessario regolarizzare i vincoli di sparsità. Per attivare alcune parti di nodi nel livello aggiungere alcuni termini extra alla funzione di perdita che spinge l'auto-codificatore per rendere ogni input come nodi più piccoli combinati e fa sì che l'encoder trovi alcune strutture uniche nei dati dati. È applicabile anche per un gran numero di dati perché è attivata solo una parte dei nodi.
Il valore del vincolo di scarsità è più vicino a zero
Per generare un livello di codice,
code = Dense(code_size, activation='relu')(input_img)
Per aggiungere valore di regolarizzazione,
code = Dense(code_size, activation='relu', activity_regularizer=l1(10e-6))(input_img)
In questo modello, solo 0, 01 è la perdita finale anche a causa del termine di regolarizzazione.
In questo modello sparso, un sacco di valori di codice è fedele al risultato atteso. Ma ha valori di varianza piuttosto bassi.
Gli autoencoder regolari hanno proprietà uniche come la robustezza degli input mancanti, la rappresentazione sparsa e il valore più vicino ai derivati nelle presentazioni. Per un uso efficace, mantenere la dimensione minima del codice e encoder e decoder poco profondi. Scoprono un'elevata capacità di input e non hanno bisogno di alcun termine di regolarizzazione aggiuntivo per rendere efficace la codifica. Sono addestrati per dare un effetto massimo anziché copiare e incollare.
3. Autoencoder variazionale
Viene utilizzato in casi complessi e trova le possibilità di distribuzione progettando i dati di input. Questo codificatore automatico variazionale utilizza un metodo di campionamento per ottenere il suo output effettivo. Segue la stessa architettura dei codificatori automatici regolarizzati
Conclusione
Quindi gli autoencoders vengono utilizzati per apprendere dati e immagini del mondo reale, coinvolti nelle classificazioni binarie e multiclasse. Il suo semplice processo di riduzione della dimensionalità. Viene applicato in una macchina Boltzmann limitata e svolge un ruolo vitale in essa. Viene anche utilizzato nell'industria biochimica per scoprire la parte non rivelata dell'apprendimento e utilizzato per identificare il modello di comportamento intelligente. Ogni componente dell'apprendimento automatico ha un carattere auto-organizzato, Autoencoder è uno di quelli che sta imparando con successo nell'intelligenza artificiale
Articoli consigliati
Questa è una guida per i codificatori automatici. Qui discutiamo i componenti principali in Autoencoder che sono un codificatore, decodificatore e codice e l'architettura di Autoencoder. Puoi anche dare un'occhiata ai seguenti articoli per saperne di più -
- Architettura dei big data
- Codifica vs decodifica
- Architettura di apprendimento automatico
- Tecnologie per i Big Data