
Differenza tra alveare e HBase
Apache Hive e HBase sono tecnologie di big data basate su Hadoop. Entrambi hanno usato per interrogare i dati. Hive e HBase funzionano su Hadoop e si differenziano per la loro funzionalità. Hive è un dialetto SQL basato sulla riduzione della mappa, mentre HBase supporta solo MapReduce. HBase memorizza i dati sotto forma di coppie chiave / valore o famiglia di colonne mentre Hive non memorizza i dati.
Differenze testa a testa tra Hive vs HBase (infografica)
Di seguito è la 8 differenza principale tra Hive vs HBase
Differenze chiave tra Hive e HBase
- Hbase è compatibile ACID mentre Hive no.
- Hive supporta il partizionamento e i criteri di filtro in base al formato della data, mentre HBase supporta il partizionamento automatico.
- Hive non supporta le dichiarazioni di aggiornamento mentre HBase le supporta.
- Hbase è più veloce rispetto a Hive nel recupero dei dati.
- Hive viene utilizzato per elaborare dati strutturati mentre HBase, essendo privo di schemi, può elaborare qualsiasi tipo di dati.
- Hbase è altamente (orizzontalmente) scalabile rispetto a Hive.
- Hive analizza i dati su HDFS con il supporto di query SQL e quindi li converte in una mappa e riduce i lavori mentre in Hbase poiché è in tempo reale lo streaming esegue direttamente le sue operazioni sul database partizionando in tabelle e famiglie di colonne.
- quando si arriva alla query di dati hive utilizza una shell nota come shell Hive per emettere i comandi mentre HBase dal momento che è database useremo un comando per elaborare i dati in HBase.
- Per andare alla shell Hive useremo il comando hive. Dopo averlo dato, apparirà come hive>. In HBase, diamo semplicemente come Use HBase.
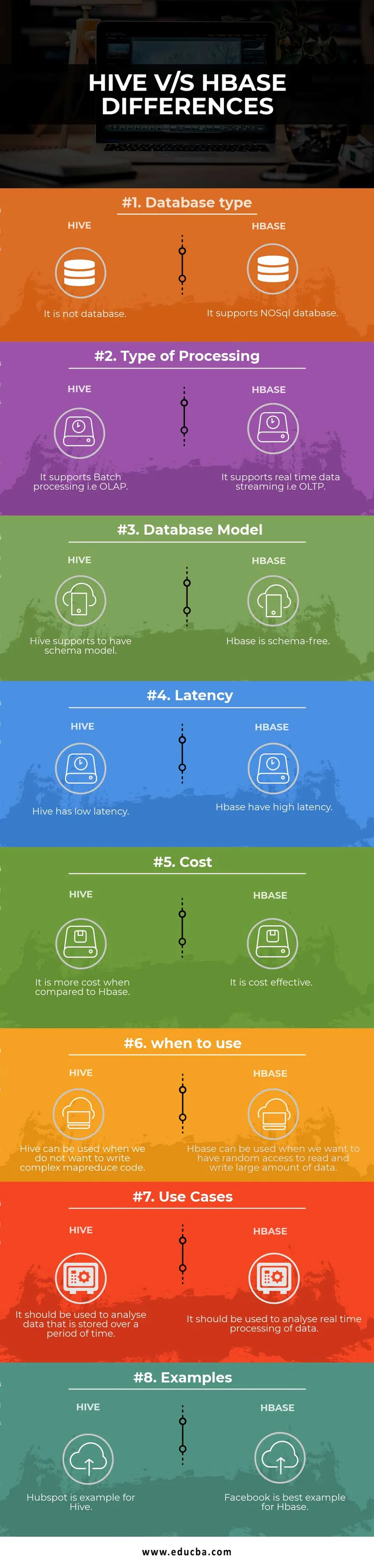
Tabella comparativa Hive vs HBase
| Base per il confronto | Alveare | HBase |
| Tipo di database | Non è un database | Supporta il database NoSQL |
| Tipo di elaborazione | Supporta l'elaborazione batch ovvero OLAP | Supporta lo streaming di dati in tempo reale, ad es. OLTP |
| Modello di database | Hive supporta il modello di schema | Hbase è privo di schemi |
| Latenza | L'alveare ha una bassa latenza | Hbase ha un'alta latenza |
| Costo | È più costoso rispetto a HBase | È conveniente |
| quando usare | Hive può essere usato quando non vogliamo scrivere codice MapReduce complesso | HBase può essere usato quando vogliamo avere accesso casuale per leggere e scrivere una grande quantità di dati |
| Casi d'uso | Dovrebbe essere usato per analizzare i dati che vengono memorizzati per un periodo di tempo | Dovrebbe essere usato per analizzare l'elaborazione dei dati in tempo reale. |
| Esempi | Hubspot è un esempio di Hive | Facebook è il miglior esempio di Hbase |
Differenze nella codifica tra Hive e HBase
Parliamo ora delle differenze di base tra Hive e HBase nella codifica.
| Base per il confronto | Alveare | HBase |
| Per creare un database | CREA DATABASE (SE NON ESISTE) DATABASE-NAME; | Poiché Hbase è un database, non è necessario creare un database specifico |
| Per eliminare un database | DROP DATABASE (SE ESISTE) DATABASE-NAME (RESTRICT O CASCADE); | N / A |
| Per creare una tabella | CREA TABELLA (TEMPORANEO O ESTERNO) (SE NON ESISTE) TABELLA-NOME ((tipo-colonna-nome-dati (commento-colonna-commento), ….)) (commento tabella_commenti) (formato riga FORMATO FILA) (memorizzato come formato file) | CREARE '', '' |
| Modificare una tabella | ALTER TABLE name RENAME TO new-name
ALTER TABLE nome DROP (COLUMN) nome-colonna ALTER TABLE nome AGGIUNGI COLONNE (col-spec (, col-spec ..)) ALTER TABLE nome CAMBIA nome-colonna nuovo-nome nuovo-tipo Nome ALTER TABLE SOSTITUIRE COLONNE (col-spec (, col-spec ..)) | ALTER 'TABLE-NAME', NAME => 'COLUMN-NAME', VERSIONS => |
| Disabilitare una tabella | N / A | disabilita 'TABLE-NAME' -> per disabilitare il nome tabella specificato
disable_all 'r *' -> per disabilitare tutte le tabelle che corrispondono all'espressione regolare |
| Abilitazione di una tabella | N / A | abilita 'TABLE-NAME' |
| Rilasciare un tavolo | DROP TABLE SE ESISTE nome-tabella | Se vogliamo eliminare una tabella, prima dobbiamo disabilitarla
disabilita 'nome-tabella' rilascia 'table-name' Allo stesso modo, possiamo usare disable_all e drop_all per eliminare le tabelle che corrispondono all'espressione regolare specificata. |
| Per elencare i database | mostra database; | N / A |
| Per elencare le tabelle nel database | mostra tabelle; | elenco |
| Descrivere lo schema di una tabella | descrivere il nome della tabella; | descrivere 'nome-tabella' |
Integrazione di Hive vs HBase
- Installa e configura Hive.
- Installa e configura HBase.
- Per l'integrazione di Hive e HBase, utilizziamo HANDLER DI STORAGE in Hive.
- I gestori di archiviazione sono una combinazione di SERDE, InputFormat, OutputFormat che accetta qualsiasi entità esterna come tabella in Hive.
- Quindi questa funzione aiuta un utente a inviare query SQL, sia nella tabella presente in Hadoop che nel database basato su NOSQL come HBase, MongoDB, Cassandra, Amazon DynamoDB.
- Ora esamineremo un esempio per connettere Hive con HBase usando HiveStorageHandler:
- Innanzitutto, dobbiamo creare una tabella Hbase usando il comando
creare "Studente", "personalinfo", "informazioni di reparto"
-> Personalinfo e dept info creano due diverse famiglie di colonne nella tabella Student.
- Dobbiamo inserire alcuni dati nella tabella Student, ad esempio, come indicato di seguito.
metti "studente", "sid01", "personalinfo: nome", "Ram"
metti "studente", "sid01", "personalinfo: mailid", " "
metti 'studente', 'sid01 ′, ' deptinfo: deptname ', ' Java '
metti 'Student', 'sid01 ′, ' deptinfo: joinyear ', ' 1994 ′
-> Allo stesso modo, possiamo creare dati per sid02, sid03 …
- Ora dobbiamo creare una tabella Hive che punta alla tabella HBase.
- Per ogni colonna in Hbase, creeremo una tabella particolare per quella colonna in Hive. In questo caso, creeremo 2 tabelle in Hive
create external table student_hbase(sid String, name String, mailid String)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler with serdeproperties("hbase.columns.mapping"=":key, personalinfo:name, personalinfo:mailid")
tblproperties("hbase.table.name"="student");
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
-> Allo stesso modo, dobbiamo creare una tabella dei dettagli delle informazioni di reparto in hive.
- Ora possiamo scrivere query SQL in un alveare come indicato di seguito.
select * from student_hbase;
In questo modo, possiamo integrare Hive con HBase.
Conclusione - Hive vs HBase
Come discusso, entrambi sono tecnologie diverse che forniscono funzionalità diverse in cui Hive funziona utilizzando il linguaggio SQL e può anche essere chiamato come HQL e HBase utilizzano coppie chiave-valore per analizzare i dati. Hive e HBase funzionano meglio se combinati perché Hive ha una bassa latenza e può elaborare un'enorme quantità di dati ma non è in grado di conservare i dati aggiornati e HBase non supporta l'analisi dei dati ma supporta gli aggiornamenti a livello di riga su una grande quantità di dati.
Articolo raccomandato
Questa è stata una guida a Hive vs HBase, il loro significato, confronto testa a testa, differenze chiave, tabella di confronto e conclusioni. Puoi anche consultare i seguenti articoli per saperne di più -
- Apache Pig vs Apache Hive - Le 12 principali differenze utili
- Scopri le 7 migliori differenze tra Hadoop e HBase
- I 12 migliori confronti tra Apache Hive e Apache HBase (infografica)
- Hadoop vs Hive - Scopri le migliori differenze