

Come installare Apache
Prima di entrare nel modo in cui installare la parte Apache, avremmo prima una panoramica generale di Apache e di come viene utilizzata nella scienza dei dati.
Che cos'è Apache?

Apache Web Server è un server HTTP che presenta siti Web ai visitatori che arrivano al tuo server. Quindi, se desideri distribuire un sito Web per un'azienda o per la tua organizzazione, molto probabilmente useresti Apache per questo.
Esistono altri server HTTP, come IIS, ma Apache è lo standard utilizzato dalla maggior parte delle persone, sia su Linux, Windows o Mac. Apache è il valore predefinito a cui la maggior parte delle persone si rivolge perché è ben noto, è molto affidabile ed è gratuito.
Tuttavia, una cosa da capire con Apache è che, poiché si tratta di un server HTTP, quindi se lo installi su Linux o Windows o Mac, tutto ciò che ti permetterebbe di fare è presentare siti Web statici ai visitatori che arrivano sul tuo server. Quindi, se si codifica un sito Web HTML senza altri linguaggi di programmazione diversi da JavaScript, è possibile utilizzarlo solo con un server Apache. È possibile collegare tutti i tag al server Apache e presentarli ai visitatori.
In che modo Apache utilizzava Data Science?
Data Science è il campo di studio più richiesto nel mondo moderno. Data Scientist è considerato il lavoro più sexy del 21 ° secolo con professionisti di varie discipline che vogliono imparare e diventare un Data Scientist. Apache svolge un ruolo cruciale in ogni appassionato di scienza dei dati, poiché ha bisogno di una conoscenza sufficiente dell'ecosistema Apache Hadoop.
Apache Hadoop Ecosystem
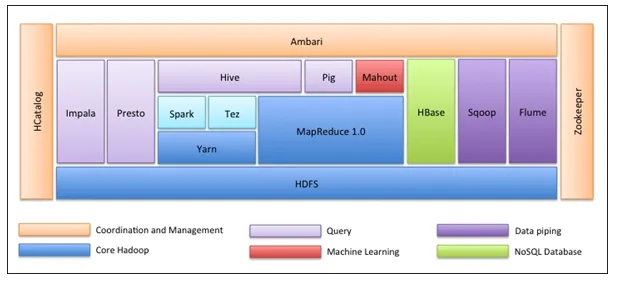
La prima cosa è che l'ecosistema Hadoop non è uno strumento. Non è un linguaggio di programmazione o un singolo framework. È un gruppo di strumenti che vengono utilizzati insieme da varie società in diversi domini per molteplici attività. Analizzeremo ogni strumento uno per uno di seguito: -
- Apache HDFS (Hadoop Distributed File System) è l'unità di archiviazione di Hadoop in grado di memorizzare dati strutturati, semi-strutturati e non strutturati. HDFS ha metadati che mantengono il file di registro sui dati memorizzati. Ha due componenti: NameNode e DataNode.
- Apache Yarn è il negoziatore di risorse che esegue tutte le attività di elaborazione come attività di pianificazione, allocazione di risorse, ecc. Ha due servizi: il primo è il Resource Manager che pianifica le applicazioni in esecuzione su Yarn. Il secondo è il Node Manager che controlla l'utilizzo delle risorse .
- Apache Map Reduce è il componente Elaborazione dati di Hadoop che elabora set di dati di grandi dimensioni utilizzando il calcolo distribuito e parallelo basato sulle funzioni Mappa, Ordinamento e Shuffle e Riduzione. La funzione Mappa filtra i dati, quindi l'ordinamento e il riordino vengono eseguiti e alla fine Riduci gli aggregati di funzioni e riepiloga il risultato.
- Apache Pig usato principalmente in ETL. Ha due parti: Pig Latin e il runtime di Pig. Pig Latin è la lingua utilizzata per l'elaborazione dei dati mediante una query, mentre il runtime di Pig è l'ambiente di esecuzione. Una riga di Pig Latin è quasi uguale a 100 righe di codice Map Reduce. Il processo prevede prima di caricare i dati e quindi raggrupparli, ordinarli, filtrarli e archiviarli in HDFS.
- Apache Hive utilizza una query simile a SQL per analizzare i dati in un ambiente distribuito. Ha due componenti: la riga di comando Hive e il server JDBC / ODBC e il linguaggio utilizzato si chiama HiveQL.
- Apache Mahout è la libreria di Machine Learning scritta in Java e utilizzata per creare applicazioni di machine learning come clustering, classificazione o regressione. Ha diversi algoritmi integrati per diversi casi d'uso.
- Apache HBase è un database NoSQL scritto in Java che funziona su Hadoop. È basato sulla BigTable di Google ed è in grado di gestire tutti i tipi di dati.
- Apache Sqoop è uno strumento di inserimento dati utilizzato per il trasferimento di dati strutturati in blocco tra RDBMS e Hadoop.
- Apache Flume è un altro strumento di inserimento dati utilizzato per il trasferimento di dati semi-strutturati e non strutturati tra Hadoop e altre fonti di dati.
- ZooKeeper è il coordinatore che assicura il coordinamento tra i vari strumenti nell'ecosistema Hadoop.
- Apache Ambari è un Cluster Manager che provvede, gestisce i cluster Hadoop e monitora anche la loro salute e il loro stato.
- Apache Tez è un nuovo strumento nell'ecosistema Hadoop che accelera l'elaborazione delle query di Hadoop.
- Apache Presto è un motore di query SQL distribuito open source che consente funzionalità di query multipiattaforma.
- Apache HCatalog è un sistema di gestione di metadati e tabelle per Hadoop che consente l'interoperabilità tra gli strumenti di elaborazione dei dati. Aiuta anche gli utenti a scegliere gli strumenti migliori per i loro ambienti.
- Apache Spark è il framework più utilizzato e popolare tra i Data Scientist. Si tratta di un sistema di elaborazione cluster ad alta velocità che ottimizza l'utilizzo delle risorse in caso di molte attività iterative. Offre flessibilità sia per l'elaborazione batch che per l'analisi dei dati in tempo reale.
Di seguito sono riportati i passaggi per installare Apache
Finora abbiamo appreso Apache e come è utile per chiunque desideri imparare Data Science o Big Data Analytics. Ora, ci immergeremo e installeremo apache su Windows in base ai passaggi seguenti.
- Vai su https://httpd.apache.org/ e fai clic sul collegamento Download nella sezione Apache httpd 2.4.38 Rilasciato.

- Ti porterà alla pagina seguente, quindi fai clic su File per Microsoft Windows.
- Fai clic su Apache Lounge.

- Puoi scaricare 32-bit o 64-bit del file zip in base al tuo sistema operativo Windows. Scaricheremo la versione a 64 bit qui. Fare clic sul collegamento .zip corrispondente per il download.

- Ora richiede Visual Studio 2017 ridistribuibile C ++. Quindi lo scariceremo dal collegamento a 32 o 64 bit corrispondente

- Dopo che entrambi i file sono stati scaricati, andremo nel percorso scaricato e installeremo prima Visual Studio 2017 ridistribuibile C ++. Fare doppio clic sul file .exe.

- Seleziona "Accetto" e fai clic su Installa.

- L'installazione di Apache è in corso.
- Una volta completato, riceverai un messaggio come questo. Fai clic su Chiudi per terminare l'installazione.
- Ora vai alla cartella in cui scarichi il file zip di Apache. Fai clic destro su di esso e seleziona Estrai qui.
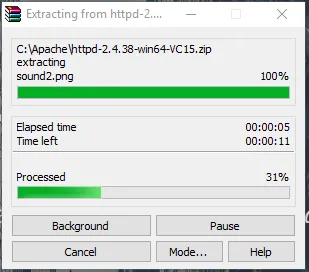
- Ora, avremo una cartella Apache24 creata. Copia questa cartella sull'unità C, quindi aggiungeremo un percorso alle variabili di ambiente di sistema.
Vai a Proprietà del sistema -> scheda Avanzate -> Fai clic sul pulsante Variabili d'ambiente di seguito.
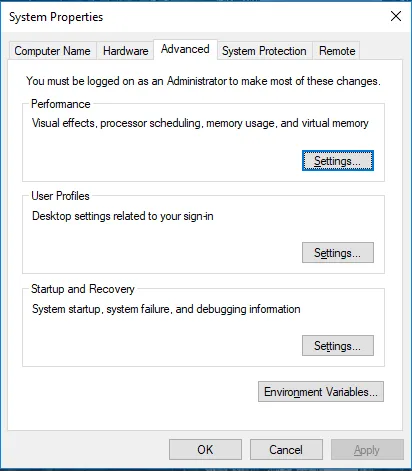
- In Variabili, trova Percorso e fai clic su Modifica.
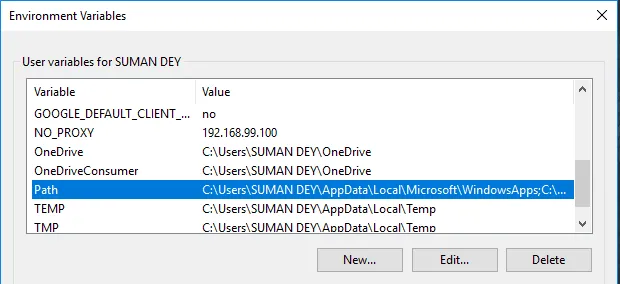
- Fare clic su Sfoglia -> Vai alla cartella Apache24 dell'unità C -> Seleziona cartella bin -> Fare clic su OK.
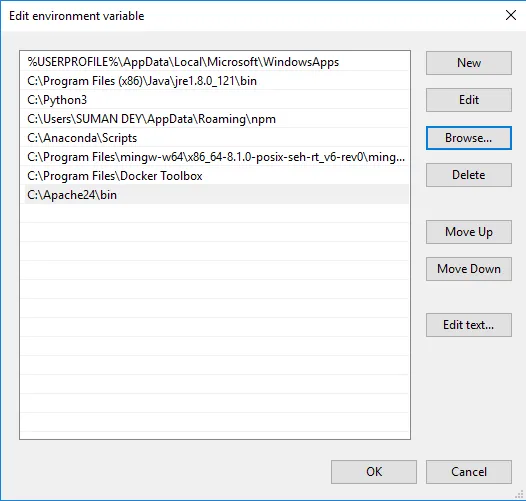
- Installeremo Apache come servizio di Windows. Esegui il prompt dei comandi come amministratore. Digita httpd –k install e premi invio.
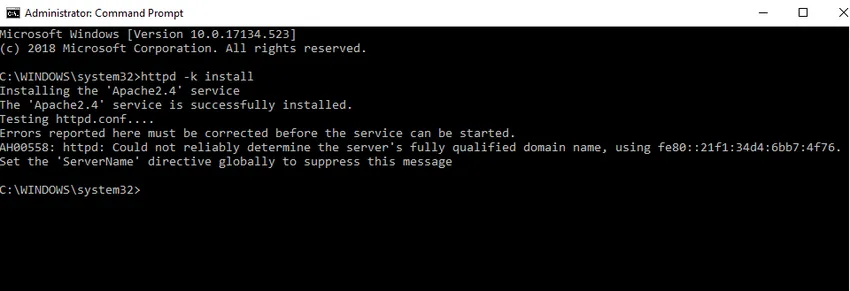
- Controlleremo il servizio di installazione di Apache. Fare clic sull'icona di Windows e digitare servizi. Fai clic sull'app Servizi e trova il servizio con il nome Apache24.

- Per avviare il server Apache, fai clic destro su di esso e fai clic su Avvia. Lo stato cambierà in "In esecuzione".
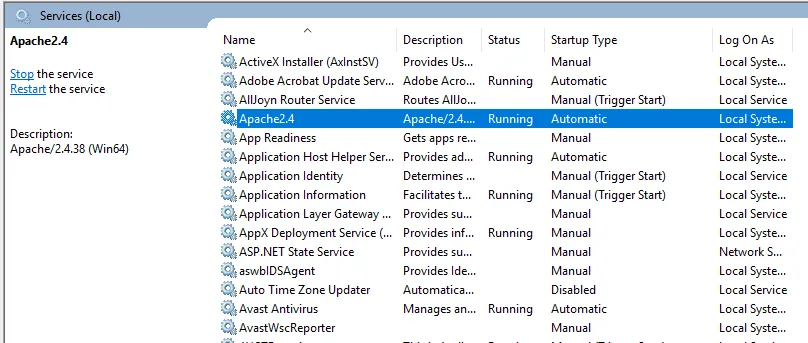
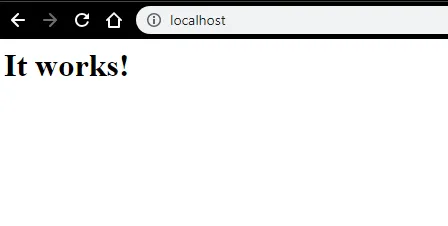
- Possiamo testare con un browser. Apri un browser e vai a http: // localhost e premi invio. Un messaggio che dice "Funziona!" apparirà per confermare la corretta installazione di Apache.
Articoli consigliati
Questa è stata una guida su Come installare Apache. Qui abbiamo discusso le istruzioni e i diversi passaggi per installare Apache. Puoi anche leggere il seguente articolo per saperne di più -
- Domande di intervista di Apache
- Apache Spark vs Apache Flink
- Apache Hadoop vs Apache Spark
- Apache Kafka vs Flume
- Kafka vs Kinesis | Differenze principali