
Introduzione alla regressione di Poisson in R
La regressione di Poisson è un tipo di regressione che è simile alla regressione lineare multipla, tranne per il fatto che la risposta o la variabile dipendente (Y) è una variabile di conteggio. La variabile dipendente segue la distribuzione di Poisson. Il predittore o le variabili indipendenti possono essere di natura continua o categorica. In un certo senso, è simile alla regressione logistica che ha anche una variabile di risposta discreta. La comprensione preliminare della distribuzione di Poisson e della sua forma matematica è molto essenziale per sfruttarla per la previsione. In R, la regressione di Poisson può essere implementata in modo molto efficace. R offre una serie completa di funzionalità per la sua implementazione.
Implementazione della regressione di Poisson
Procederemo ora a capire come viene applicato il modello. La sezione seguente fornisce una procedura dettagliata per lo stesso. Per questa dimostrazione, stiamo prendendo in considerazione il set di dati "gala" dal pacchetto "lontano". Riguarda la diversità delle specie nelle Isole Galapagos. Nel set di dati sono presenti complessivamente 7 variabili. Useremo la regressione di Poisson per definire una relazione tra il numero di specie vegetali (specie) e altre variabili nel set di dati.
1. Caricare innanzitutto il pacchetto "lontano". Nel caso in cui il pacchetto non sia presente, scaricarlo utilizzando la funzione install.packages ().
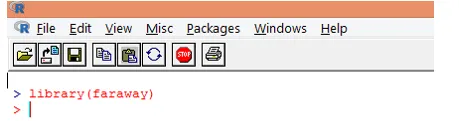
2. Una volta caricato il pacchetto, caricare il set di dati "gala" in R utilizzando la funzione data () come mostrato di seguito.
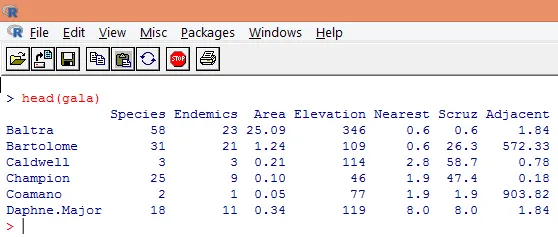
3. I dati caricati devono essere visualizzati per studiare la variabile e verificare se vi sono discrepanze. Possiamo visualizzare i dati interi o solo le prime poche righe usando la funzione head () come mostrato nello screenshot qui sotto.
4. Per ottenere maggiori informazioni sul set di dati, possiamo utilizzare la funzionalità di aiuto in R come di seguito. Genera la documentazione R come mostrato nello screenshot successivo allo screenshot seguente.


5. Se studiamo il set di dati come indicato nei passaggi precedenti, possiamo scoprire che Species è una variabile di risposta. Ora studieremo un riepilogo di base delle variabili predittive.
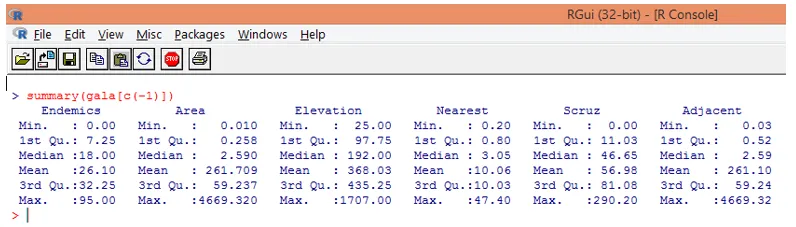
Nota, come si può vedere sopra, abbiamo escluso la variabile Specie. La funzione di riepilogo ci fornisce approfondimenti di base. Basta osservare i valori mediani per ciascuna di queste variabili e possiamo scoprire che esiste una differenza enorme, in termini di intervallo di valori, tra la prima metà e la seconda metà, ad esempio per il valore mediano della variabile Area è 2, 59, ma il massimo il valore è 4669.320.
6. Ora che abbiamo finito con l'analisi di base, genereremo un istogramma per le specie al fine di verificare se la variabile segue la distribuzione di Poisson. Questo è illustrato di seguito.

Il codice sopra genera un istogramma per la variabile Specie insieme a una curva di densità sovrapposta su di essa.
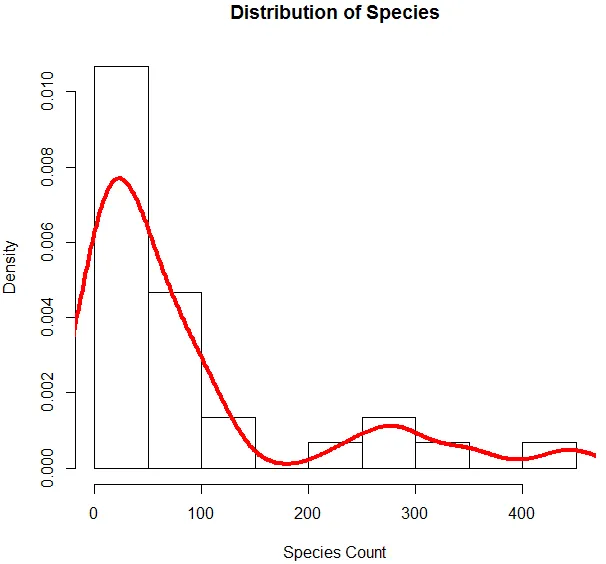
La visualizzazione sopra mostra che Species segue una distribuzione di Poisson, poiché i dati sono distorti. Possiamo anche generare un diagramma a scatole, per ottenere maggiori informazioni sul modello di distribuzione come mostrato di seguito.
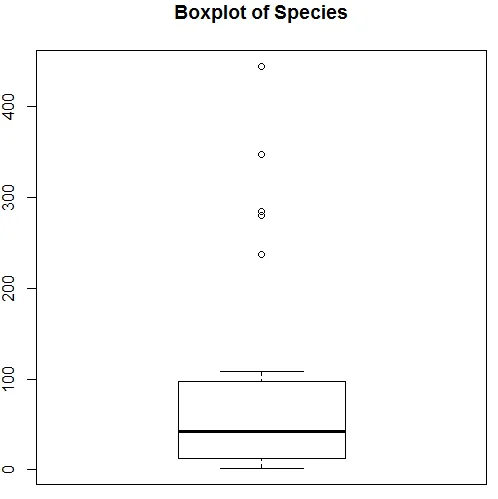
7. Avendo terminato l'analisi preliminare, applicheremo ora la regressione di Poisson come mostrato di seguito
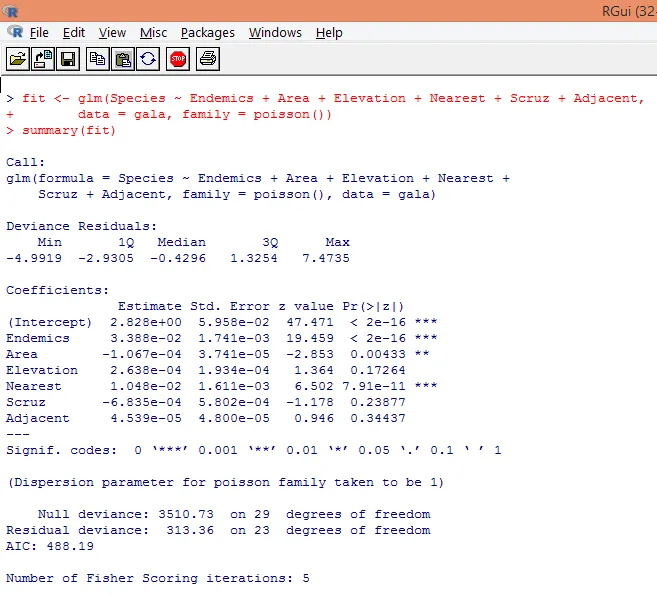
Sulla base dell'analisi di cui sopra, scopriamo che le variabili Endemica, Area e Più vicino sono significative e solo la loro inclusione è sufficiente per costruire il giusto modello di regressione di Poisson.
8. Costruiremo un modello di regressione di Poisson modificato prendendo in considerazione solo tre variabili, vale a dire. Endemici, area e più vicini. Vediamo quali risultati otteniamo.
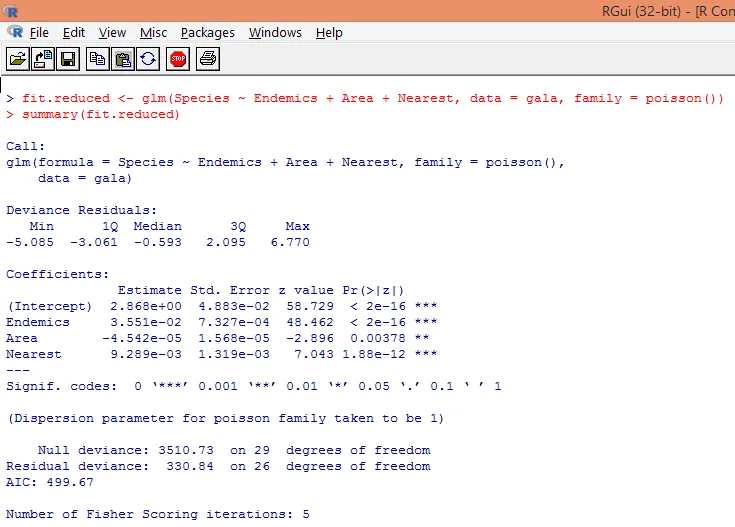
L'output produce deviazioni, parametri di regressione ed errori standard. Possiamo vedere che ciascuno dei parametri è significativo a livello p <0, 05.
9. Il prossimo passo è interpretare i parametri del modello. I coefficienti del modello possono essere ottenuti esaminando i coefficienti nell'output sopra o usando la funzione coef ().
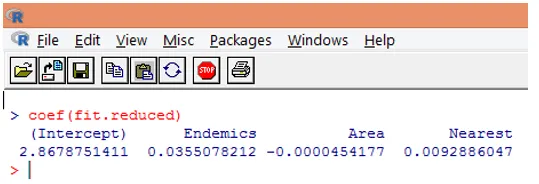
Nella regressione di Poisson, la variabile dipendente è modellata come log del loge medio condizionale (l). Il parametro di regressione di 0, 0355 per Endemici indica che un aumento di una unità nella variabile è associato ad un aumento di 0, 04 nel numero medio di log delle Specie, mantenendo costanti le altre variabili. L'intercettazione è un numero medio di registro di specie quando ciascuno dei predittori è uguale a zero.
10. Tuttavia, è molto più semplice interpretare i coefficienti di regressione nella scala originale della variabile dipendente (numero di specie, anziché numero di registro delle specie). L'esponenziazione dei coefficienti consentirà una facile interpretazione. Questo è fatto come segue.
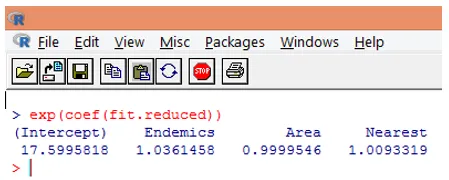
Dai risultati di cui sopra, possiamo dire che un aumento di unità in Area moltiplica il numero previsto di specie per 0, 9999 e un aumento di unità nel numero di specie endemiche rappresentate da Endemici moltiplica il numero di specie per 1, 0361. L'aspetto più importante della regressione di Poisson è che i parametri esponenziali hanno un effetto moltiplicativo anziché additivo sulla variabile di risposta.
11. Usando i passaggi precedenti, abbiamo ottenuto un modello di regressione di Poisson per prevedere il numero di specie vegetali nelle Isole Galapagos. Tuttavia, è molto importante verificare la presenza di sovradispersione. Nella regressione di Poisson, la varianza e i mezzi sono uguali.
La sovradispersione si verifica quando la varianza osservata della variabile di risposta è maggiore di quanto previsto dalla distribuzione di Poisson. L'analisi della sovradispersione diventa importante in quanto è comune con i dati di conteggio e può avere un impatto negativo sui risultati finali. In R, la sovradispersione può essere analizzata usando il pacchetto "qcc". L'analisi è illustrata di seguito.
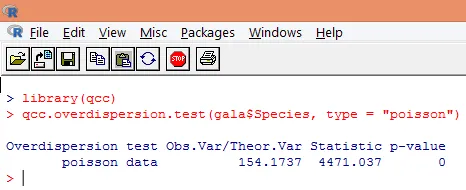
Il test significativo sopra riportato mostra che il valore p è inferiore a 0, 05, il che suggerisce fortemente la presenza di sovradispersione. Proveremo ad adattare un modello usando la funzione glm (), sostituendo family = "Poisson" con family = "quasipoisson". Questo è illustrato di seguito.
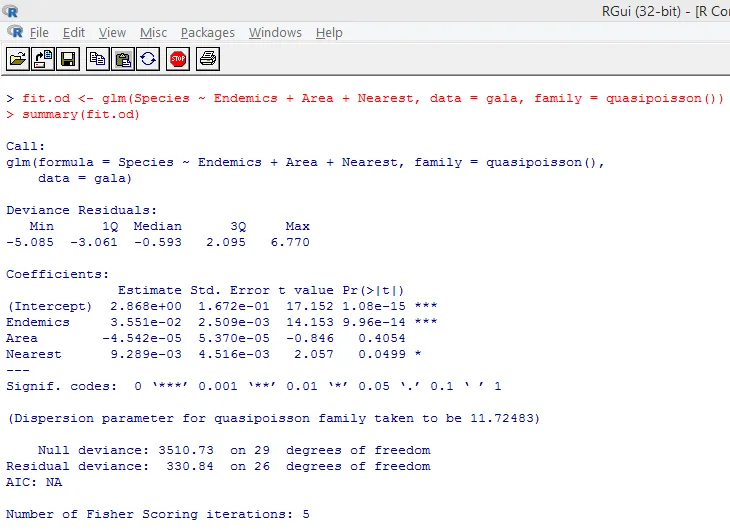
Studiando da vicino l'output di cui sopra, possiamo vedere che le stime dei parametri nell'approccio quasi-Poisson sono identiche a quelle prodotte dall'approccio Poisson, sebbene gli errori standard siano diversi per entrambi gli approcci. Inoltre, in questo caso, per Area, il valore p è maggiore di 0, 05, a causa di un errore standard maggiore.
Importanza della regressione di Poisson
- La regressione di Poisson in R è utile per le previsioni corrette della variabile discreta / conteggio.
- Ci aiuta a identificare quelle variabili esplicative che hanno un effetto statisticamente significativo sulla variabile di risposta.
- La regressione di Poisson in R è più adatta per eventi di natura "rara" in quanto tendono a seguire una distribuzione di Poisson rispetto a eventi comuni che di solito seguono una distribuzione normale.
- È adatto per l'applicazione nei casi in cui la variabile di risposta è un numero intero piccolo.
- Ha ampie applicazioni, poiché la previsione di variabili discrete è cruciale in molte situazioni. In medicina, può essere utilizzato per prevedere l'impatto del farmaco sulla salute. È ampiamente utilizzato nell'analisi di sopravvivenza come la morte di organismi biologici, guasti di sistemi meccanici, ecc.
Conclusione
La regressione di Poisson si basa sul concetto di distribuzione di Poisson. È un'altra categoria appartenente all'insieme delle tecniche di regressione che combina le proprietà delle regressioni sia lineari che logistiche. Tuttavia, a differenza della regressione logistica che genera solo output binario, viene utilizzato per prevedere una variabile discreta.
Articoli consigliati
Questa è una guida alla regressione di Poisson in R. Qui discutiamo dell'introduzione della regressione di Poisson e dell'importanza della regressione di Poisson. Puoi anche consultare i nostri altri articoli suggeriti per saperne di più–
- GLM in R
- Generatore di numeri casuali in R
- Formula di regressione
- Regressione logistica in R
- Regressione lineare vs regressione logistica | Differenze principali