

Introduzione ai metodi di data mining
I dati aumentano ogni giorno su una scala enorme. Ma tutti i dati raccolti o raccolti non sono utili. I dati significativi devono essere separati dai dati rumorosi (dati insignificanti). Questo processo di separazione viene eseguito dal data mining.
Che cos'è il data mining?
Il data mining è un processo di estrazione di informazioni o conoscenze utili da un'enorme quantità di dati (o big data). Il divario tra dati e informazioni è stato ridotto utilizzando vari strumenti di data mining. Il data mining può anche essere definito rilevamento della conoscenza dai dati o KDD .
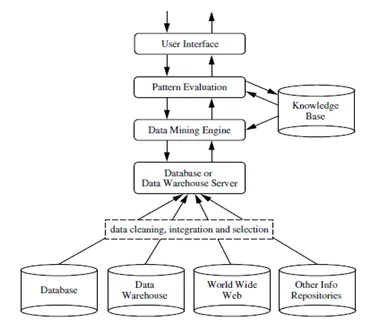
Fonti: - www.ques10.com
Il data mining può essere eseguito su vari tipi di database e repository di informazioni come database relazionali, data warehouse, database transazionali, flussi di dati e molti altri.
Diversi metodi di data mining:
Esistono molti metodi utilizzati per l'estrazione dei dati, ma il passaggio cruciale è selezionare il metodo appropriato tra loro in base al business o alla dichiarazione del problema. Questi metodi di data mining aiutano a prevedere il futuro e quindi a prendere decisioni di conseguenza. Questi aiutano anche ad analizzare l'andamento del mercato e ad aumentare i ricavi dell'azienda.
Alcuni metodi di data mining sono:
- Associazione
- Classificazione
- Analisi del clustering
- Predizione
- Pattern sequenziali o tracciamento dei pattern
- Alberi decisionali
- Analisi anomale o analisi di anomalie
- Rete neurale
Cerchiamo di comprendere tutti i metodi di data mining uno per uno.
1. Associazione:
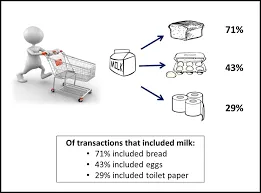
È un metodo utilizzato per trovare una correlazione tra due o più elementi identificando il modello nascosto nel set di dati e quindi chiamato anche come analisi delle relazioni . Questo metodo viene utilizzato nell'analisi del paniere di mercato per prevedere il comportamento del cliente.
Supponiamo che il responsabile marketing di un supermercato voglia determinare quali prodotti vengono frequentemente acquistati insieme.
Come esempio,
Acquista (x, "birra") -> acquista (x, "patatine") (supporto = 1%, confidenza = 50%)
- Qui x rappresenta un cliente che acquista birra e patatine insieme.
- La fiducia dimostra la certezza che se un cliente acquista una birra, c'è una probabilità del 50% che comprerà anche le patatine.
- Supporto significa che l'1% di tutte le transazioni in analisi ha dimostrato che birra e patatine sono state acquistate insieme.
Molti esempi simili come pane e burro o computer e software possono essere considerati.
Esistono due tipi di regole di associazione:
- Regola di associazione monodimensionale: queste regole contengono un singolo attributo che viene ripetuto.
- Regola di associazione multidimensionale: queste regole contengono più attributi che si ripetono.
https://bit.ly/2N61gzR
2. Classificazione:
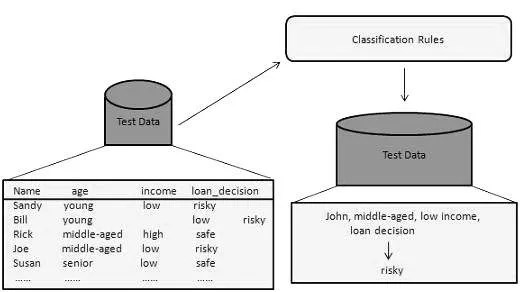
Questo metodo di data mining viene utilizzato per distinguere gli elementi nei set di dati in classi o gruppi. Aiuta a prevedere con precisione il comportamento degli oggetti all'interno del gruppo. È un processo in due fasi:
- Fase di apprendimento (fase di allenamento): in questo, un algoritmo di classificazione crea il classificatore analizzando un set di addestramento.
- Fase di classificazione: i dati di test vengono utilizzati per stimare l'accuratezza o la precisione delle regole di classificazione.
Ad esempio, una società bancaria utilizza per identificare i richiedenti prestiti a rischio di credito basso, medio o alto. Allo stesso modo, un ricercatore medico analizza i dati sul cancro per prevedere quale medicinale prescrivere al paziente.
Fonti: - www.tutorialspoint.com
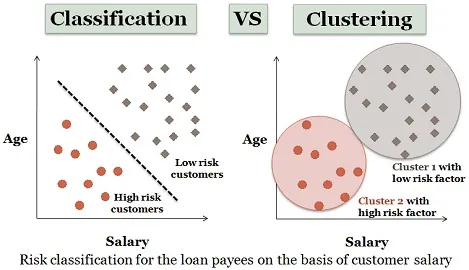
3. Analisi del clustering:
Il clustering è quasi simile alla classificazione, ma in questo i cluster vengono creati in base alle somiglianze degli elementi di dati. Cluster diversi hanno oggetti diversi o non correlati. Viene anche chiamato come segmentazione dei dati in quanto suddivide enormi set di dati in cluster in base alle somiglianze.
Esistono vari metodi di clustering utilizzati:
- Metodi agglomerativi gerarchici
- Metodi basati su griglia
- Metodi di partizionamento
- Metodi basati sul modello
- Metodi basati sulla densità
Un esempio simile di richiedenti un prestito può essere considerato anche qui. Ci sono alcune differenze che sono rappresentate nella figura seguente.
https://bit.ly/2N6aZpP
4. Previsione:
Questo metodo viene utilizzato per prevedere il futuro in base alle tendenze o al set di dati passati e presenti. La previsione viene utilizzata principalmente con la combinazione di altri metodi di data mining come classificazione, corrispondenza dei modelli, analisi delle tendenze e relazione.
Ad esempio, se il responsabile delle vendite di un supermercato desidera prevedere l'importo delle entrate che ciascun articolo genererebbe sulla base dei dati di vendita passati. Modella la funzione a valore continuo che prevede valori di dati numerici mancanti.

Fonti: - data-mining.philippe-fournier
L'analisi di regressione è la scelta migliore per eseguire la previsione. Può essere utilizzato per impostare una relazione tra variabili indipendenti e variabili dipendenti.
5. Pattern sequenziali o tracciamento dei pattern:
Questo metodo di data mining viene utilizzato per identificare modelli che si verificano frequentemente in un determinato periodo di tempo.
Ad esempio, il direttore delle vendite della società di abbigliamento vede che le vendite di giacche sembrano aumentare poco prima della stagione invernale o che le vendite in pasticceria aumentano durante il periodo di Natale o di Capodanno.
Vediamo un esempio con un grafico
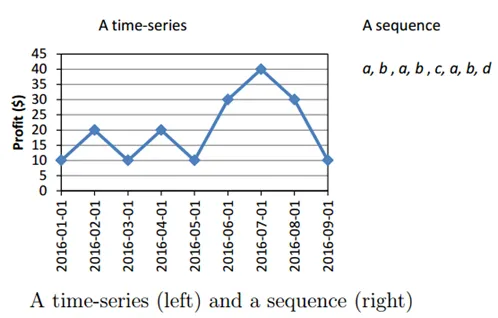
Fonti: - data-mining.philippe-fournier-viger
6. Alberi di decisione:
Un albero decisionale è una struttura ad albero (come suggerisce il nome), dove
- Ogni nodo interno rappresenta un test sull'attributo.
- Branch indica il risultato del test.
- I nodi terminali contengono l'etichetta della classe.
- Il nodo più in alto è il nodo principale che ha la semplice domanda che ha due o più risposte. Di conseguenza, l'albero cresce e viene generato un diagramma di flusso come la struttura.
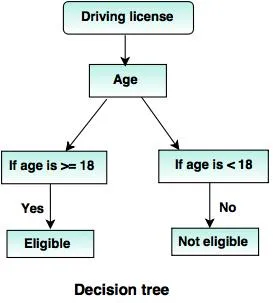
Fonti: - www.tutorialride.com
In questa decisione, il governo degli alberi classifica i cittadini di età inferiore ai 18 anni o superiore ai 18 anni. Ciò li aiuterebbe a decidere se una licenza deve essere rilasciata a un determinato cittadino o meno.
7.Analisi esterna o Analisi dell'anomalia:
Questo metodo di data mining viene utilizzato per identificare gli elementi di dati che non sono conformi al modello previsto o al comportamento previsto. Questi elementi di dati imprevisti sono considerati come valori anomali o rumore. Sono utili in molti settori come il rilevamento di frodi con carta di credito, il rilevamento di intrusioni, il rilevamento di errori, ecc. Questo è anche chiamato estrazione di dati anomali .
Ad esempio, supponiamo che il grafico seguente sia tracciato utilizzando alcuni set di dati nel nostro database.
Quindi viene disegnata la linea più adatta. I punti vicini alla linea mostrano il comportamento previsto mentre il punto lontano dalla linea è un valore anomalo.
Ciò contribuirebbe a rilevare le anomalie e ad adottare le possibili azioni di conseguenza.
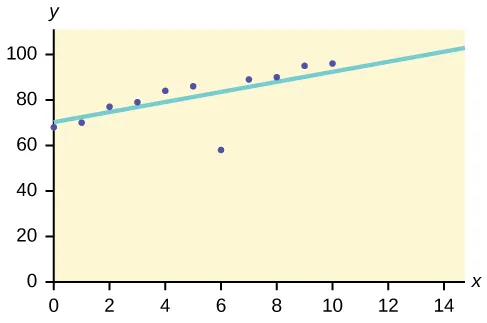
https://bit.ly/2GrgjDP
8. Rete neurale:
Questo metodo o modello di data mining si basa su reti neurali biologiche. È una raccolta di neuroni come unità di elaborazione con connessioni ponderate tra loro. Sono usati per modellare la relazione tra input e output. È utilizzato per classificazione, analisi di regressione, elaborazione dei dati ecc. Questa tecnica funziona su tre pilastri:
- Modello
- Algoritmo di apprendimento (supervisionato o non supervisionato)
- Funzione di attivazione
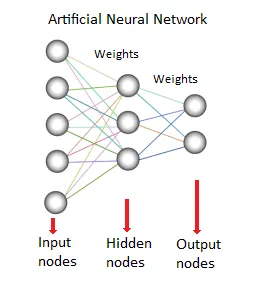
Fonti: - www.saedsayad.com
Articoli consigliati
Questa è stata una guida ai metodi di data mining Qui abbiamo discusso dell'esempio di Data Mining e dei diversi tipi di metodo di Data Mining. Puoi anche consultare i seguenti articoli per saperne di più -
- Software di analisi dei Big Data
- Domande di intervista sulla struttura dei dati
- Importanti tecniche di data mining
- Architettura di data mining