

Introduzione a AWS EMR
AWS EMR offre molte funzionalità che ci facilitano le cose, alcune delle tecnologie sono:
- Amazon EC2
- Amazon RDS
- Amazon S3
- Amazon CloudFront
- Amazon Auto Scaling
- Amazon Lambda
- Amazon Redshift
- Amazon Elastic MapReduce (EMR)
Uno dei principali servizi forniti da AWS EMR e di cui ci occuperemo è Amazon EMR.
L'EMR, comunemente chiamato Elastic Map Reduce, offre un modo semplice e accessibile per gestire l'elaborazione di grandi quantità di dati. Immagina uno scenario di big data in cui abbiamo una grande quantità di dati e stiamo eseguendo una serie di operazioni su di essi, diciamo che è in esecuzione un processo di riduzione della mappa, uno dei principali problemi che l'applicazione Bigdata deve affrontare è l'ottimizzazione del programma, noi spesso è difficile mettere a punto il nostro programma in modo tale che tutte le risorse allocate vengano consumate correttamente. A causa di questo fattore di ottimizzazione, il tempo impiegato per l'elaborazione aumenta gradualmente. Mappa elastica Ridurre il servizio di Amazon, è un servizio Web che fornisce un framework che gestisce tutte queste funzionalità necessarie per l'elaborazione dei Big Data in modo economico, veloce e sicuro. Dalla creazione del cluster alla distribuzione dei dati su varie istanze, tutte queste cose sono facilmente gestibili con Amazon EMR. I servizi qui disponibili su richiesta consentono di controllare i numeri in base ai dati in nostro possesso che rendono se efficienti in termini di costi e scalabili.
Motivi per l'utilizzo di AWS EMR
Quindi perché usare l'AMR che lo rende migliore dagli altri. Spesso incontriamo un problema di base in cui non siamo in grado di allocare tutte le risorse disponibili sul cluster a qualsiasi applicazione, AMAZON EMR che si occupa di questi problemi e in base alla dimensione dei dati e alla domanda dell'applicazione che alloca le risorse necessarie. Inoltre, essendo di natura elastica, possiamo cambiarlo di conseguenza. EMR ha un enorme supporto applicativo sia Hadoop, Spark, HBase che semplifica l'elaborazione dei dati. Supporta varie operazioni ETL in modo rapido ed economico. Può essere utilizzato anche per MLIB in Spark. Possiamo eseguire vari algoritmi di apprendimento automatico al suo interno. Che si tratti di dati batch o streaming in tempo reale dei dati EMR è in grado di organizzare ed elaborare entrambi i tipi di dati.
Funzionamento di AWS EMR
Ora vediamo questo diagramma del cluster Amazon EMR e cercheremo di capire come funziona effettivamente:
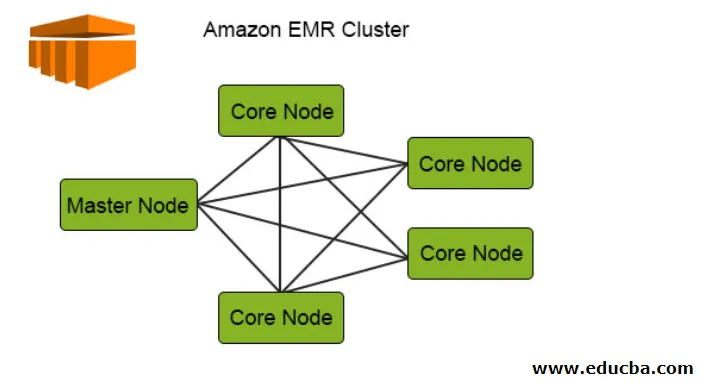
Il diagramma seguente mostra la distribuzione dei cluster all'interno di EMR. Controlliamo questo dettaglio:
1. I cluster sono il componente centrale dell'architettura Amazon EMR. Sono una raccolta di istanze EC2 chiamate nodi. Ogni nodo ha i suoi ruoli specifici all'interno del cluster definito come tipo di nodo e in base ai loro ruoli possiamo classificarli in 3 tipi:
- Nodo principale
- Nodo principale
- Nodo attività
2. Il nodo principale come suggerisce il nome è il principale responsabile della gestione del cluster, dell'esecuzione dei componenti e della distribuzione dei dati sui nodi per l'elaborazione. Tiene traccia se tutto è correttamente gestito e funziona correttamente e funziona in caso di errore.
3. Il nodo principale ha la responsabilità di eseguire l'attività e archiviare i dati in HDFS nel cluster. Tutte le parti di elaborazione sono gestite dal Nodo principale e i dati dopo tale elaborazione vengono collocati nella posizione HDFS desiderata.
4. Il nodo attività, essendo facoltativo, ha solo il compito di eseguire l'attività che non memorizza i dati in HDFS.
5. Ogni volta che dopo aver inviato un lavoro, abbiamo diversi metodi per scegliere come completare i lavori. Essendo dalla fine del cluster dopo il completamento del lavoro a un cluster di lunga durata che utilizza la console EMR e l'interfaccia della riga di comando per inviare i passaggi, abbiamo tutti i privilegi per farlo.
6. È possibile eseguire direttamente il processo sull'EMR collegandolo al nodo principale attraverso le interfacce e gli strumenti disponibili che eseguono i processi direttamente sul cluster.
7. Possiamo anche eseguire i nostri dati in vari passaggi con l'aiuto di EMR, tutto ciò che dobbiamo fare è inviare uno o più passaggi ordinati nel cluster EMR. I dati vengono archiviati come file e vengono elaborati in modo sequenziale. Iniziando da "Stato in sospeso a stato Completato" possiamo tracciare le fasi di elaborazione e trovare gli errori, anche se si tratta di "Impossibile annullare", tutti questi passaggi possono essere facilmente ricondotti a questo.
8. Una volta terminata l'istanza, viene raggiunto lo stato completo per il cluster.
Architettura per AWS EMR
L'architettura di EMR si presenta a partire dalla parte di archiviazione alla parte Applicazione.
- Il primo livello viene fornito con il livello di archiviazione che include diversi file system utilizzati con il nostro cluster. Sia da HDFS a EMRFS al file system locale, questi sono tutti utilizzati per l'archiviazione dei dati sull'intera applicazione. La memorizzazione nella cache dei risultati intermedi durante l'elaborazione di MapReduce può essere ottenuta con l'aiuto di queste tecnologie fornite con EMR.
- Il secondo livello viene fornito con la gestione delle risorse per il cluster, questo livello è responsabile della gestione delle risorse per i cluster e i nodi sull'applicazione. Questo in sostanza aiuta come strumenti di gestione che aiutano a distribuire uniformemente i dati su cluster e una corretta gestione. Lo strumento di gestione delle risorse predefinito utilizzato da EMR è YARN che è stato introdotto in Apache Hadoop 2.0. Gestisce centralmente le risorse per più framework di elaborazione dati. Si occupa di tutte le informazioni necessarie per il buon funzionamento del cluster, dalla salute del nodo alla distribuzione delle risorse con la gestione della memoria.
- Il terzo livello viene fornito con il Framework di elaborazione dati, questo livello è responsabile dell'analisi e del trattamento dei dati. ci sono molti framework supportati da EMR che svolgono un ruolo importante nell'elaborazione dei dati parallela ed efficiente. Parte del framework che supporta e di cui siamo a conoscenza è APACHE HADOOP, SPARK, SPARK STREAMING, ecc.
- Il quarto livello viene fornito con l'applicazione e programmi come HIVE, PIG, libreria di streaming, algoritmi ML utili per l'elaborazione e la gestione di set di dati di grandi dimensioni.
Vantaggi di AWS EMR
Vediamo ora alcuni dei vantaggi dell'utilizzo di EMR:
- Alta velocità: poiché tutte le risorse sono utilizzate correttamente, il tempo di elaborazione della query è relativamente più veloce rispetto agli altri strumenti di elaborazione dei dati che hanno un quadro molto chiaro.
- Elaborazione di dati in blocco: maggiore della dimensione dei dati EMR ha la capacità di elaborare una grande quantità di dati in un ampio tempo.
- Minima perdita di dati: poiché i dati sono distribuiti sul cluster ed elaborati parallelamente sulla rete, vi è una minima possibilità di perdita di dati e bene, il tasso di accuratezza per i dati elaborati è migliore.
- Conveniente: essendo economico è più economico di qualsiasi altra alternativa disponibile che lo rende forte rispetto all'utilizzo del settore. Dato che i prezzi sono inferiori, siamo in grado di accogliere grandi quantità di dati e di elaborarli nel rispetto del budget.
- AWS integrato: è integrato con tutti i servizi di AWS che rende facile la disponibilità sotto un tetto in modo che la sicurezza, l'archiviazione, la rete tutto sia integrato in un unico posto.
- Sicurezza: viene fornito con un fantastico gruppo di sicurezza per controllare il traffico in entrata e in uscita, inoltre l'uso di IAM Roles lo rende più sicuro in quanto fornisce varie autorizzazioni che rendono sicuri i dati.
- Monitoraggio e distribuzione: disponiamo di strumenti di monitoraggio adeguati per tutte le applicazioni in esecuzione su cluster EMR che la rendono trasparente e semplice per la parte di analisi, inoltre è dotata di una funzione di distribuzione automatica in cui l'applicazione viene configurata e distribuita automaticamente.
Ci sono molti più vantaggi nell'avere EMR come scelta migliore per altri metodi di calcolo del cluster.
Prezzi AWS EMR
EMR ha un fantastico listino prezzi che attira gli sviluppatori o il mercato nei suoi confronti. Dal momento che viene fornito con una funzione di determinazione dei prezzi su richiesta, possiamo usarlo solo su base oraria e numero di nodi nel nostro cluster. Possiamo pagare una tariffa al secondo per ogni secondo che utilizziamo con almeno un minuto. Inoltre, possiamo scegliere le nostre istanze da utilizzare come istanze riservate o istanze Spot, con un notevole risparmio sui costi.
Possiamo calcolare la fattura totale tramite un semplice calcolatore mensile dal seguente link: -
https://calculator.s3.amazonaws.com/index.html#s=EMR
Per maggiori dettagli sugli esatti dettagli dei prezzi puoi fare riferimento al documento di seguito da Amazon: -
https://aws.amazon.com/emr/pricing/
Conclusione
Dall'articolo di cui sopra, abbiamo visto come EMR può essere utilizzato per il corretto trattamento dei big data con tutte le risorse utilizzate convenzionalmente.
Avere EMR risolve il nostro problema di base dell'elaborazione dei dati e riduce notevolmente i tempi di elaborazione di un buon numero, essendo economico è facile e conveniente da usare.
Articolo raccomandato
Questa è stata una guida per AWS EMR. Qui discutiamo un'introduzione a AWS EMR lungo il suo funzionamento e l'architettura, nonché i vantaggi. Puoi anche consultare i nostri altri articoli suggeriti per saperne di più -
- Alternative AWS
- Comandi AWS
- Servizi AWS
- Domande di intervista AWS
- Servizi di archiviazione AWS
- I 7 principali concorrenti di AWS
- Elenco delle funzionalità di Amazon Web Services