
Che cos'è la regressione lineare in R?
La regressione lineare è l'algoritmo più popolare e ampiamente utilizzato nel campo della statistica e dell'apprendimento automatico. La regressione lineare è una tecnica di modellazione per comprendere la relazione tra le variabili di input e output. Qui le variabili devono essere numeriche. La regressione lineare deriva dal fatto che la variabile di output è una combinazione lineare di variabili di input. L'output è generalmente rappresentato da "y", mentre input è rappresentato da "x".
La regressione lineare in R può essere classificata in due modi
-
Si mple Regressione lineare
Questa è la regressione in cui la variabile di output è una funzione di una singola variabile di input. Rappresentazione della regressione lineare semplice:
y = c0 + c1 * x1
-
Regressione lineare multipla
Questa è la regressione in cui la variabile di output è una funzione di una variabile a input multiplo.
y = c0 + c1 * x1 + c2 * x2
In entrambi i casi precedenti c0, c1, c2 sono i coefficienti che rappresentano i pesi di regressione.
Regressione lineare in R
R è uno strumento statistico molto potente. Vediamo quindi come è possibile eseguire la regressione lineare in R e come interpretare i suoi valori di output.
Prepariamo un set di dati, per eseguire e comprendere subito la regressione lineare.
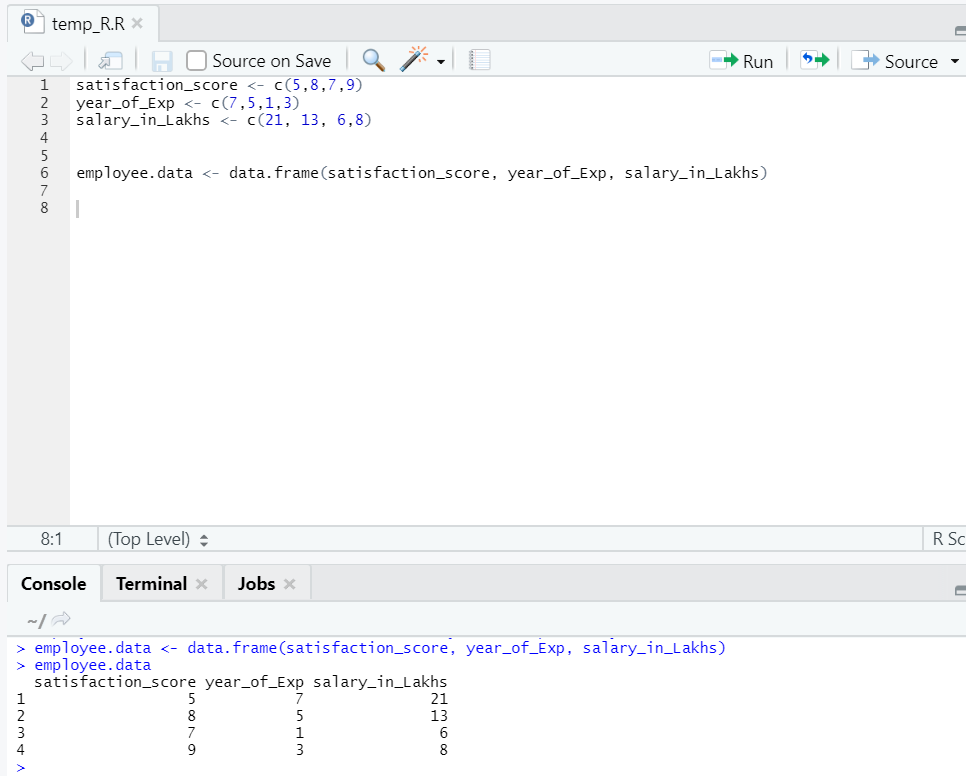
Ora abbiamo un set di dati, in cui "soddisfazione_sconto" e "anno_di_Exp" sono la variabile indipendente. "Salary_in_lakhs" è la variabile di output.
Facendo riferimento al set di dati di cui sopra, il problema che vogliamo affrontare qui attraverso la regressione lineare è:
Stima del salario di un dipendente, in base al suo anno di esperienza e al punteggio di soddisfazione nella sua azienda.
Codice R di regressione lineare:
model <- lm(salary_in_Lakhs ~ satisfaction_score + year_of_Exp, data = employee.data)
summary(model)
L'output del codice sopra sarà:
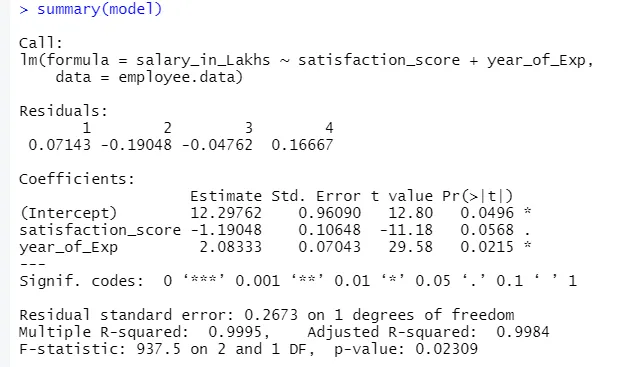
La formula della regressione diventa
Y = 12.29-1.19 * score_soddisfazione + 2.08 × 2 * anno_di_Exp
Nel caso, uno ha più input per il modello.
Quindi il codice R può essere:
modello <- lm (salary_in_Lakhs ~., data = employee.data)
Tuttavia, se qualcuno vuole selezionare una variabile tra più variabili di input, ci sono più tecniche come "Eliminazione all'indietro", "Selezione in avanti" ecc. Per farlo.
Interpretazione della regressione lineare in R
Di seguito sono riportate alcune interpretazioni della regressione lineare in r che sono le seguenti:
1.Residuals
Ciò si riferisce alla differenza tra la risposta effettiva e la risposta prevista del modello. Quindi per ogni punto, ci sarà una risposta effettiva e una risposta prevista. Quindi i residui saranno tanti quanto le osservazioni. Nel nostro caso abbiamo quattro osservazioni, quindi quattro residui.

2.Coefficients
Andando oltre, troveremo la sezione dei coefficienti, che raffigura l'intercetta e la pendenza. Se si desidera prevedere lo stipendio di un dipendente in base alla sua esperienza e al punteggio di soddisfazione, è necessario sviluppare una formula modello basata su pendenza e intercettazione. Questa formula ti aiuterà a prevedere lo stipendio. L'intercettazione e la pendenza aiutano un analista a elaborare il modello migliore che si adatta in modo appropriato ai punti dati.
Pendenza: descrive la pendenza della linea.
Intercetta: la posizione in cui la linea taglia l'asse.
Comprendiamo come si fa la formazione della formula in base alla pendenza e all'intercettazione.
Dire intercetta è 3 e la pendenza è 5.
Quindi, la formula è y = 3 + 5x . Ciò significa che se x viene aumentata di un'unità, y viene aumentata di 5.
a. Coefficiente - Stima
In questo, l'intercetta indica il valore medio della variabile di output, quando tutto l'input diventa zero. Quindi, nel nostro caso, lo stipendio in lakh sarà di 12.29 Lakh come media considerando il punteggio di soddisfazione e l'esperienza arriva a zero. Qui l'inclinazione rappresenta il cambiamento nella variabile di output con un cambio di unità nella variabile di input.
b.Coefficiente - Errore standard
L'errore standard è la stima dell'errore, che possiamo ottenere calcolando la differenza tra il valore effettivo e previsto della nostra variabile di risposta. A sua volta, questo parla della fiducia per il collegamento delle variabili di input e output.
c.Coefficiente - valore t
Questo valore dà la sicurezza di rifiutare l'ipotesi nulla. Maggiore è il valore lontano da zero, maggiore è la sicurezza di rifiutare l'ipotesi nulla e stabilire la relazione tra output e input input. Nel nostro caso anche il valore è diverso da zero.
d.Coefficiente - Pr (> t)
Questo acronimo descrive sostanzialmente il valore p. Più è vicino a zero, più facile possiamo rifiutare l'ipotesi nulla. La linea che vediamo nel nostro caso, questo valore è vicino allo zero, possiamo dire che esiste una relazione tra pacchetto retributivo, punteggio di soddisfazione e anno di esperienze.

Errore standard residuo
Ciò descrive l'errore nella previsione della variabile di risposta. Più è basso, maggiore è l'accuratezza del modello.
R-quadrato multiplo, R-quadrato regolato
R-quadrato è una misura statistica molto importante per capire quanto vicini siano i dati inseriti nel modello. Quindi nel nostro caso quanto bene il nostro modello di regressione lineare rappresenti il set di dati.
Il valore R al quadrato si trova sempre tra 0 e 1. La formula è:

Più il valore è vicino a 1, migliore è il modello che descrive i set di dati e la sua varianza.
Tuttavia, quando viene visualizzata più di una variabile di input, viene preferito il valore R al quadrato regolato.
F Statistica
È una misura forte per determinare la relazione tra input e variabile di risposta. Maggiore è il valore di 1, maggiore è la fiducia nella relazione tra la variabile di input e output.
Nel nostro caso il suo "937, 5", che è relativamente più grande considerando la dimensione dei dati. Quindi il rifiuto dell'ipotesi nulla diventa più facile.
Se qualcuno vuole vedere l'intervallo di confidenza per i coefficienti del modello, ecco il modo per farlo: -
Visualizzazione della regressione
Codice R:
trama (salary_in_Lakhs ~ satisfaction_score + year_of_Exp, data = employee.data)
abline (modello)
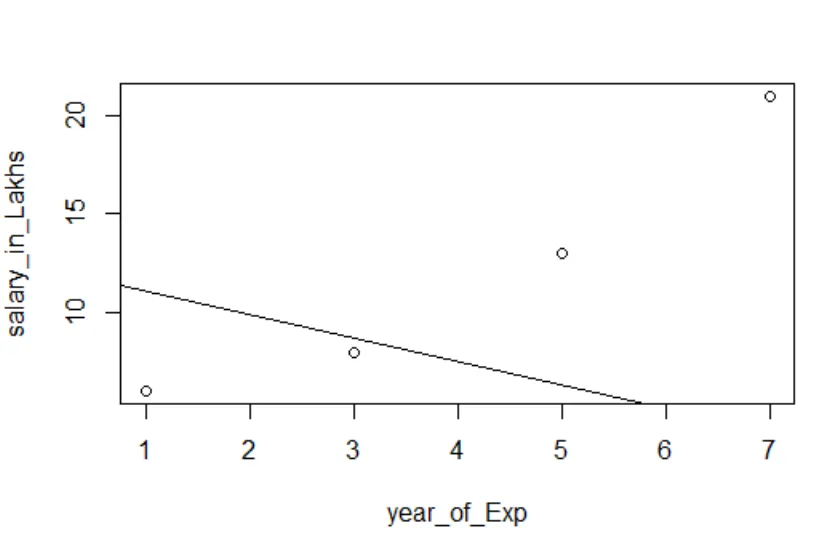
È sempre meglio raccogliere sempre più punti, prima di adattarsi a un modello.
Conclusione - Regressione lineare in R
La regressione lineare è un modello semplice, facile da adattare, facile da capire ma molto potente. Abbiamo visto come è possibile eseguire la regressione lineare su R. Abbiamo anche provato a interpretare i risultati, il che può aiutarti nell'ottimizzazione del modello. Una volta che ci si sente a proprio agio con una semplice regressione lineare, si dovrebbe provare una regressione lineare multipla. Insieme a questo, poiché la regressione lineare è sensibile ai valori anomali, è necessario esaminarla prima di saltare direttamente nel raccordo alla regressione lineare.
Articoli consigliati
Questa è una guida alla regressione lineare in R. Qui abbiamo discusso di cosa sia la regressione lineare in R? categorizzazione, visualizzazione e interpretazione di R. Puoi anche consultare i nostri altri articoli suggeriti per saperne di più -
- Modellazione predittiva
- Regressione logistica in R
- Albero decisionale in R
- R Domande di intervista
- Principali differenze di regressione rispetto alla classificazione
- Guida all'albero decisionale nell'apprendimento automatico
- Regressione lineare vs regressione logistica | Differenze principali