

Differenza tra Hadoop e Hive
Hadoop:
Hadoop è un Framework o un software che è stato inventato per gestire enormi quantità di dati o Big Data. Hadoop viene utilizzato per archiviare ed elaborare i grandi dati distribuiti su un cluster di server di prodotti.
Hadoop archivia i dati utilizzando il file system distribuito Hadoop e li elabora / interroga utilizzando il modello di programmazione Map Reduce.
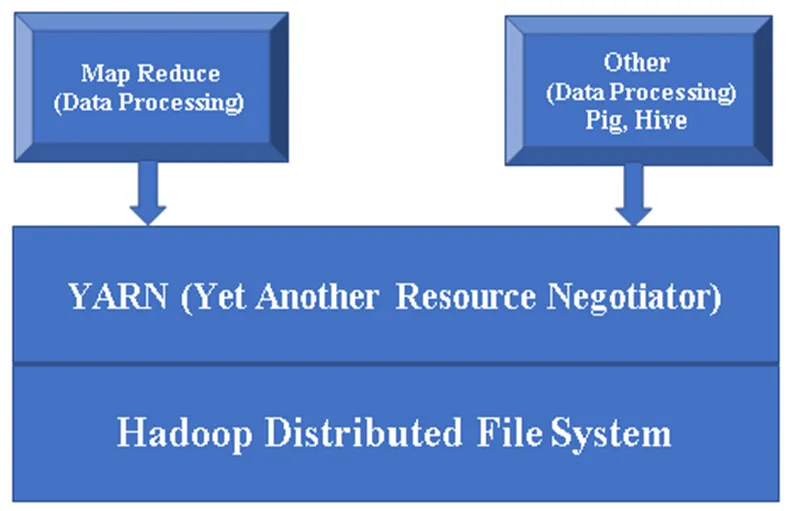
Figura 1, un'architettura di base di un componente Hadoop.
Principali componenti di Hadoop:
Hadoop Base / Common: Hadoop common ti fornirà una piattaforma per installare tutti i suoi componenti.
HDFS (Hadoop Distributed File System): HDFS è una parte importante del framework Hadoop che si occupa di tutti i dati in Hadoop Cluster. Funziona su Master / Slave Architecture e archivia i dati usando la replica.
Architettura e replica master / slave:
- Nodo principale / Nodo nome: il nodo nome memorizza i metadati di ciascun blocco / file archiviati in HDFS, HDFS può avere un solo nodo principale (in caso di HA un altro nodo principale funzionerà come nodo principale secondario).
- Nodo slave / Nodo dati: i nodi dati contengono file di dati effettivi in blocchi. HDFS può avere più nodi di dati.
- Replica: HDFS archivia i suoi dati dividendoli in blocchi. La dimensione del blocco predefinita è 64 MB. A causa della replica, i dati vengono archiviati in 3 (fattore di replica predefinito, può essere aumentato in base ai requisiti) diversi nodi di dati, quindi esiste la minima possibilità di perdere i dati in caso di guasto del nodo.
YARN (Yet Another Resource Negotiator): viene utilizzato principalmente per la gestione delle risorse di Hadoop e svolge un ruolo importante nella pianificazione dell'applicazione degli utenti.
MR (Map Reduce): questo è il modello di programmazione di base di Hadoop. Viene utilizzato per elaborare / interrogare i dati all'interno del framework Hadoop.
Alveare:
Hive è un'applicazione che funziona su framework Hadoop e fornisce un'interfaccia simile a SQL per l'elaborazione / query dei dati. Hive è progettato e sviluppato da Facebook prima di entrare a far parte del progetto Apache-Hadoop.
Hive esegue la sua query utilizzando HQL (linguaggio di query Hive). Hive ha la stessa struttura di RDBMS e quasi gli stessi comandi possono essere usati in Hive.
Hive può archiviare i dati in tabelle esterne, quindi non è obbligatorio utilizzare HDFS, ma supporta anche formati di file come ORC, file Avro, file di sequenza e file di testo, ecc.
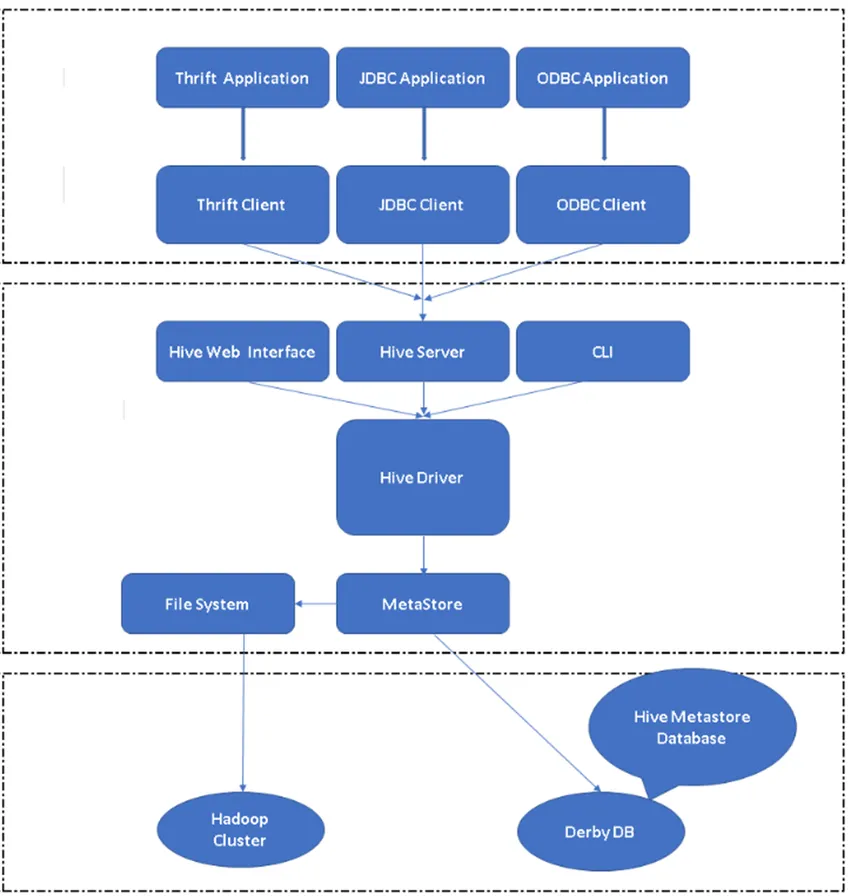
Figura 2, Architettura di Hive e componenti principali.
Componente principale di Hive:
Client Hive: non solo SQL, Hive supporta anche linguaggi di programmazione come Java, C, Python utilizzando vari driver come ODBC, JDBC e Thrift. È possibile scrivere qualsiasi applicazione client hive in altre lingue e può essere eseguita in Hive utilizzando questi client.
Servizi di alveari: in Servizi di alveari, ha luogo l'esecuzione di comandi e query. L'interfaccia web di Hive ha cinque sottocomponenti.
- CLI: interfaccia della riga di comando predefinita fornita da Hive per l'esecuzione di query / comandi Hive.
- Hive Web Interfaces: è una semplice interfaccia utente grafica. È un'alternativa alla riga di comando di Hive e viene utilizzato per eseguire query e comandi nell'applicazione Hive.
- Hive Server: viene anche chiamato Apache Thrift. È responsabile di prendere i comandi da diverse interfacce della riga di comando e inviare tutti i comandi / query a Hive, inoltre recupera il risultato finale.
- Apache Hive Driver: è responsabile di prendere gli input dalla CLI, l'interfaccia utente Web, ODBC, JDBC o le interfacce Thrift da un client e passare le informazioni al metastore in cui sono archiviate tutte le informazioni sul file.
- Metastore: Metastore è un repository per archiviare tutte le informazioni sui metadati di Hive. I metadati di Hive memorizzano le informazioni come la struttura di tabelle, partizioni e tipo di colonna ecc …
Hive Storage: è la posizione in cui viene eseguita l'attività effettiva. Tutte le query eseguite da Hive hanno eseguito l'azione all'interno di Hive Storage.
Confronto testa a testa tra Hadoop vs Hive (infografica)
Di seguito è la 8 differenza principale tra Hadoop vs Hive
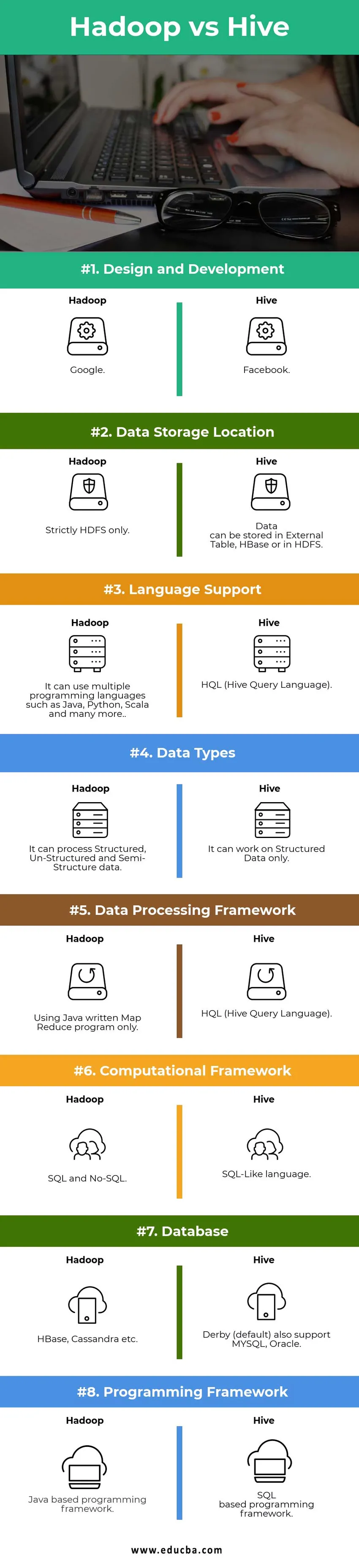
Differenze chiave tra Hadoop vs Hive:
Di seguito sono riportati gli elenchi di punti, descrivono le differenze chiave tra Hadoop e Hive:
1) Hadoop è un framework per elaborare / interrogare i Big Data mentre Hive è uno strumento basato su SQL che si basa su Hadoop per elaborare i dati.
2) Hive elabora / interroga tutti i dati usando HQL (Hive Query Language) è un linguaggio simile a SQL mentre Hadoop può comprendere solo Map Reduce.
3) Map Reduce è parte integrante di Hadoop, la query di Hive viene prima convertita in Map Reduce rispetto a quella elaborata da Hadoop per eseguire la query dei dati.
4) Hive funziona su query SQL Like mentre Hadoop lo capisce usando solo Map Reduce basato su Java.
5) In Hive, i comandi "Relational Database's" tradizionali usati in precedenza possono anche essere usati per interrogare i big data mentre in Hadoop, devono scrivere programmi Map Reduce complessi usando Java che non è simile alla tradizione Java.
6) Hive può solo elaborare / interrogare i dati strutturati mentre Hadoop è pensato per tutti i tipi di dati, sia esso strutturato, non strutturato o semi-strutturato.
7) Utilizzando Hive, è possibile elaborare / interrogare i dati senza una programmazione complessa mentre nell'ecosistema Simple Hadoop, è necessario scrivere un programma Java complesso per gli stessi dati.
8) Un framework Hadoop su un lato ha bisogno di una linea 100s per preparare il programma MR basato su Java, un altro lato su Hadoop con Hive può interrogare gli stessi dati usando 8-10 linee di HQL.
9) In Hive, è molto difficile inserire l'output di una query come input di un'altra, mentre la stessa query può essere eseguita facilmente utilizzando Hadoop con MR.
10) Non è obbligatorio avere Metastore all'interno del cluster Hadoop Mentre Hadoop archivia tutti i suoi metadati all'interno di HDFS (Hadoop Distributed File System).
Tabella comparativa Hadoop vs Hive
| Punti di confronto | Alveare | Hadoop |
|
Design e sviluppo | ||
| Posizione di archiviazione dei dati |
I dati possono essere memorizzati in esterni Tavolo, HBase o in HDFS. | Solo rigorosamente HDFS. |
| Supporto linguistico | HQL (Hive Query Language) |
Può usare più linguaggi di programmazione come Java, Python, Scala e molti altri. |
| Tipi di dati | Può funzionare solo su dati strutturati. |
Può elaborare dati strutturati, non strutturati e semi-strutturati. |
| Framework di elaborazione dati |
HQL (Hive Query Language) | Utilizzando solo il programma Map Reduce scritto Java. |
|
Quadro computazionale | Linguaggio simile a SQL. | SQL e No-SQL. |
| Banca dati |
Derby (impostazione predefinita) supporta anche MYSQL, Oracle … | HBase, Cassandra ecc. |
| Framework di programmazione |
Framework di programmazione basato su SQL. | Framework di programmazione basato su Java. |
Conclusione - Hadoop vs Hive
Hadoop e Hive sono entrambi utilizzati per elaborare i Big data. Hadoop è un framework che fornisce piattaforma per altre applicazioni per interrogare / elaborare i Big Data mentre Hive è solo un'applicazione basata su SQL che elabora i dati utilizzando HQL (Hive Query Language)
Hadoop può essere usato senza Hive per elaborare i big data mentre non è facile usare Hive senza Hadoop.
In conclusione, non possiamo confrontare Hadoop e Hive in alcun modo e in nessun aspetto. Sia Hadoop che Hive sono completamente diversi. L'esecuzione congiunta di entrambe le tecnologie può rendere il processo di query di Big Data molto più semplice e comodo per gli utenti di Big Data.
Articoli consigliati:
Questa è stata una guida a Hadoop vs Hive, il loro significato, il confronto testa a testa, le differenze chiave, la tabella di confronto e le conclusioni. Puoi anche consultare i seguenti articoli per saperne di più -
- Hadoop vs Apache Spark - Cose interessanti che devi sapere
- HADOOP vs RDBMS | Conosci le 12 differenze utili
- Come i Big Data stanno cambiando il volto dell'assistenza sanitaria
- I 12 migliori confronti tra Apache Hive e Apache HBase (infografica)
- Guida straordinaria su Hadoop vs Spark