

Introduzione a Join in Spark SQL
Come sappiamo, i join in SQL vengono utilizzati per combinare dati o righe da due o più tabelle basate su un campo comune tra di loro. In questo argomento, approfondiremo la sezione Partecipa a Spark SQL Partecipa a Spark SQL.
In Spark SQL, Dataframe o Dataset sono una struttura tabulare in memoria con righe e colonne che sono distribuite su più nodi. Come le normali tabelle SQL, possiamo anche eseguire operazioni di join su Dataframe o Dataset presenti in Spark SQL sulla base di un campo comune tra loro.
Esistono diversi tipi di operazioni di join disponibili in SQL. A seconda del caso d'uso aziendale, facciamo la scelta dell'operazione Partecipa. Nella sezione seguente, mostreremo ogni tipo di join con un esempio.
Tipi di join in Spark SQL
Di seguito sono riportati i diversi tipi di join disponibili in Spark SQL:
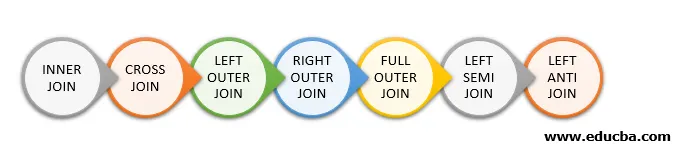
- UNIONE INTERNA
- CROSS JOIN
- SINISTRA ESTERNO UNISCITI
- ISCRIVITI ESTERNO GIUSTO
- UNISCITI ESTERNI COMPLETI
- SEMI SINISTRA ISCRIVITI
- SINISTRA ANTI JOIN
Esempio di creazione di dati
Utilizzeremo i seguenti dati per dimostrare i diversi tipi di join:
Set di dati del libro:
case class Book(book_name: String, cost: Int, writer_id:Int)
val bookDS = Seq(
Book("Scala", 400, 1),
Book("Spark", 500, 2),
Book("Kafka", 300, 3),
Book("Java", 350, 5)
).toDS()
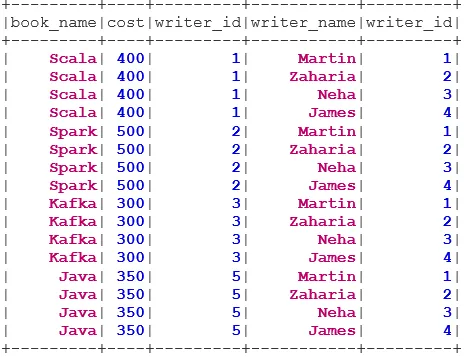
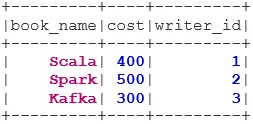
bookDS.show()

Set di dati di Writer:
case class Writer(writer_name: String, writer_id:Int)
val writerDS = Seq(
Writer("Martin", 1),
Writer("Zaharia " 2),
Writer("Neha", 3),
Writer("James", 4)
).toDS()
writerDS.show()

Tipi di join
Di seguito sono indicati 7 diversi tipi di join:
1. UNIONE INTERNA
INNER JOIN restituisce il set di dati che ha le righe che hanno valori corrispondenti in entrambi i set di dati, ovvero il valore del campo comune sarà lo stesso.
val BookWriterInner = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "inner")
BookWriterInner.show()

2. CROSS JOIN
CROSS JOIN restituisce il set di dati che è il numero di righe nel primo set di dati moltiplicato per il numero di righe nel secondo set di dati. Tale tipo di risultato è chiamato Prodotto cartesiano.
Prerequisito: per utilizzare un cross join, spark.sql.crossJoin.enabled deve essere impostato su true. Altrimenti, verrà generata l'eccezione.
spark.conf.set("spark.sql.crossJoin.enabled", true)
val BookWriterCross = bookDS.join(writerDS)
BookWriterCross.show()
3. ISCRIVITI ESTERNO SINISTRA
LEFT OUTER JOIN restituisce il set di dati che ha tutte le righe dal set di dati sinistro e le righe corrispondenti dal set di dati destro.
val BookWriterLeft = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftouter")
BookWriterLeft.show()

4. ISCRIVITI ESTERNO GIUSTO
RIGHT OUTER JOIN restituisce il set di dati che contiene tutte le righe dal set di dati destro e le righe corrispondenti dal set di dati sinistro.
val BookWriterRight = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "rightouter")
BookWriterRight.show()

5. UNISCITI ESTERNI COMPLETI
FULL OUTER JOIN restituisce il set di dati che ha tutte le righe quando c'è una corrispondenza nel set di dati sinistro o destro.
val BookWriterFull = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "fullouter")
BookWriterFull.show()

6. SINISTRA SEMI ISCRIVITI
LEFT SEMI JOIN restituisce il set di dati che ha tutte le righe del set di dati di sinistra che hanno la loro corrispondenza nel set di dati di destra. A differenza di LEFT OUTER JOIN, il set di dati restituito in LEFT SEMI JOIN contiene solo le colonne del set di dati sinistro.
val BookWriterLeftSemi = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftsemi")
BookWriterLeftSemi.show()
7. SINISTRA ANTI JOIN
ANTI SEMI JOIN restituisce il set di dati che ha tutte le righe del set di dati di sinistra che non hanno la loro corrispondenza nel set di dati di destra. Contiene inoltre solo le colonne del set di dati di sinistra.
val BookWriterLeftAnti = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftanti")
BookWriterLeftAnti.show()

Conclusione - Partecipa a Spark SQL
Unire i dati è una delle operazioni più comuni e importanti per soddisfare il nostro caso d'uso aziendale. Spark SQL supporta tutti i tipi fondamentali di join. Durante l'adesione, dobbiamo anche considerare le prestazioni in quanto potrebbero richiedere trasferimenti di rete di grandi dimensioni o persino creare set di dati oltre la nostra capacità di gestione. Per migliorare le prestazioni, Spark utilizza l'ottimizzatore SQL per riordinare o spingere verso il basso i filtri. Spark limita anche il pericoloso join i. e CROSS JOIN. Per utilizzare un cross join, spark.sql.crossJoin.enabled deve essere impostato su true in modo esplicito.
Articoli consigliati
Questa è una guida per partecipare a Spark SQL. Qui discutiamo i diversi tipi di join disponibili in Spark SQL con l'esempio. Puoi anche consultare il seguente articolo.
- Tipi di join in SQL
- Tabella in SQL
- Query di inserimento SQL
- Transazioni in SQL
- Filtri PHP | Come convalidare l'input dell'utente usando vari filtri?