
Introduzione ai file CSV R
I file CSV sono ampiamente utilizzati per archiviare le informazioni in formato tabulare in ciascuna riga del record di dati. Per leggere, scrivere o manipolare i dati in R, dobbiamo avere alcuni dati disponibili con noi. I dati possono essere trovati su Internet o possono essere raccolti da varie fonti come i sondaggi. Usando R si possono leggere, scrivere e modificare i dati che sono memorizzati in un ambiente esterno. R può leggere e scrivere dati da vari formati come XML, CSV ed Excel. In questo articolo vedremo come R può essere utilizzato per leggere, scrivere ed eseguire diverse operazioni sui file CSV.
Creazione del file CSV in R
In questa sezione, vedremo come è possibile creare ed esportare un frame di dati nel file CSV in R. Nel primo, creeremo un frame di dati che consiste di variabili dipendente e relativo stipendio.
> df <- data.frame(Employee = c('Jonny', 'Grey', 'Mouni'),
+ Salary = c(23000, 41000, 32344))
> print (df)
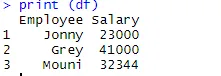
Una volta creato il frame di dati, è il momento di utilizzare la funzione di esportazione di R per creare il file CSV in R. Al fine di esportare il frame di dati in CSV, è possibile utilizzare il codice seguente.
> write.csv(df, 'C:\\Users\\Pantar User\\Desktop\\Employee.csv', row.names = FALSE)
Nella riga di codice sopra, abbiamo fornito una directory di percorso per la nostra fama di dati e memorizzato il frame di dati in formato CSV. Nel caso precedente, il file CSV è stato salvato sul mio desktop personale. Questo particolare file verrà utilizzato nel nostro tutorial per eseguire più operazioni.
Lettura dei file CSV in R
Durante l'esecuzione dell'analisi utilizzando R, in molti casi è necessario leggere i dati dal file CSV. R è molto affidabile durante la lettura di file CSV. Nell'esempio sopra, abbiamo creato il file, che useremo per leggere usando il comando read.csv. Di seguito è riportato l'esempio per farlo in R.
> df <- read.csv(file="C:\\Users\\Pantar User\\Desktop\\Employee.csv", header=TRUE,
sep=", ")
> df

Il comando sopra legge il file Employee.csv che è disponibile sul desktop e lo visualizza in R studio. Il comando di intestazione implica che l'intestazione è resa disponibile per il set di dati e il comando sep implica che i dati sono separati da virgole.
Scrivi file CSV in R
La scrittura su file CSV è una delle funzionalità più utili disponibili in R per un analista di dati. Questo può essere usato per scrivere un file CSV modificato in un nuovo file CSV per analizzare i dati. Il comando Write.csv viene utilizzato per scrivere il file in CSV.
Nel seguente codice df nel frame di dati in cui sono disponibili i nostri dati, append viene utilizzato per specificare che il nuovo file viene creato anziché aggiungere o sovrascrivere nel vecchio file. Aggiungi false suggerisce che viene creato un nuovo file CSV. Sep rappresenta il campo separato da una virgola.
# Writing CSV file in R
write.csv(df, 'C:\\Users\\Pantar User\\Desktop\\Employee.csv' append = FALSE, sep = “, ”)
Operazioni CSV
Le operazioni CSV sono necessarie per ispezionare i dati una volta caricati nel sistema. R ha diverse funzionalità integrate per verificare e ispezionare i dati. Queste operazioni forniscono informazioni complete sull'insieme di dati.
Uno dei comandi più comunemente usati è un riepilogo.
> summary(df)
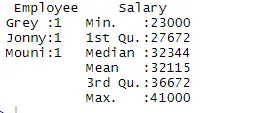
Il comando di riepilogo ci fornisce statistiche basate sulle colonne. La variabile numerica è descritta in modo statistico che include risultati statistici come media, min, mediana e max. Nell'esempio precedente, due variabili che sono Dipendente e Stipendio sono separate e vengono mostrate le statistiche per la variabile numerica che è Salario.
Il comando Visualizza () viene utilizzato per aprire il set di dati in un'altra scheda e verificarlo manualmente.
> View(df)

La funzione Str fornirà agli utenti maggiori dettagli sulla colonna del set di dati. Nell'esempio seguente possiamo vedere che la variabile Employee ha Factor come tipo di dati e che la variabile Salary ha int (numero intero) come tipo di dati.
> str(df)

In molti casi, dovremo vedere il numero totale di righe disponibili nel caso del set di dati grande, per il quale possiamo usare il comando nrow (). Si prega di vedere l'esempio di seguito.
> # to show the total number of rows in the dataset
> nrow(df)

In modo simile per visualizzare il numero totale di colonne, possiamo usare il comando ncol ()
> ncol(df)

R ci consente di visualizzare il numero desiderato di righe con l'aiuto del comando seguente. Quando il loro n numero di righe è disponibile nel set di dati, possiamo specificare l'intervallo di righe da visualizzare.
> # to display first 2 rows of the data
> df(1:2, )

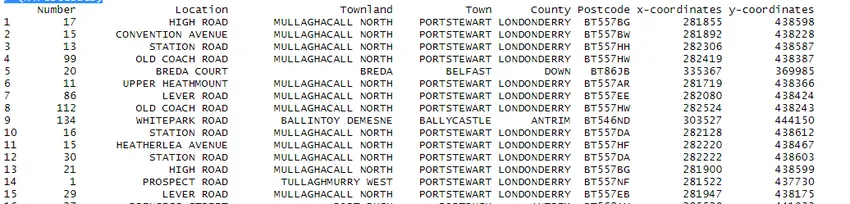
L'operazione di dati viene eseguita sul set di dati di grandi dimensioni. Ad esempio, ho scaricato il set di dati open source del codice postale NI da Internet.
> NiPostCode <- read.csv("NIPostcodes.csv", na.strings="", header=FALSE)
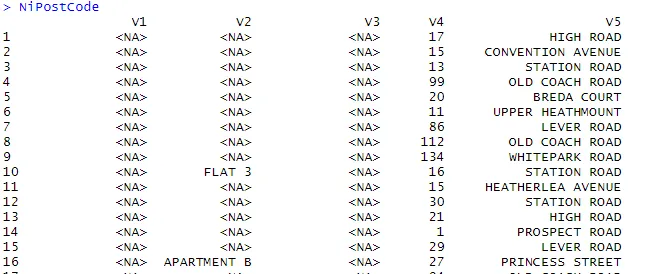
Nel set di dati sopra riportato, possiamo vedere che mancano i nomi delle intestazioni e sono presenti molti valori null. Il set di dati deve essere pulito per essere pronto per l'analisi. Nel passaggio successivo, le intestazioni verranno nominate di conseguenza.
> # adding headers/title
> names(NiPostCode)(1) <-"OrganisationName"
> names(NiPostCode)(2) <-"Sub-buildingName"
> names(NiPostCode)(3) <-"BuildingName"
> names(NiPostCode)(4) <-"Number"
> names(NiPostCode)(5) <-"Location"
> names(NiPostCode)(6) <-"Alt Thorfare"
> names(NiPostCode)(7) <-"Secondary Thorfare"
> names(NiPostCode)(8) <-"Locality"
> names(NiPostCode)(9) <-"Townland"
> names(NiPostCode)(10) <-"Town"
> names(NiPostCode)(11) <-"County"
> names(NiPostCode)(12) <-"Postcode"
> names(NiPostCode)(13) <-"x-coordinates"
> names(NiPostCode)(14) <-"y-coordinates"
> names(NiPostCode)(15) <-"Primary Key"

Ora contiamo il numero di valori mancanti nel frame di dati e quindi rimuoviamoli di conseguenza.
> # count of all missing values
> table(is.na (NiPostCode))

Dal comando sopra, possiamo vedere il numero totale di spazi vuoti o NA nel frame di dati vicino a 5445148. La rimozione di tutti i valori null comporterà la perdita dell'enorme quantità di dati, quindi è saggio rimuovere le colonne dove più della metà del 50% dei dati è mancante.
> # delete columns with more than 50% missing values
> NiPostcodes 0.5)) > (NiPostcodes)
Conclusione
In questo tutorial, abbiamo visto come è possibile creare, leggere e aggiungere file CSV usando le operazioni in R. Abbiamo imparato come creare un nuovo set di dati in R e quindi importarlo in formato CSV. Abbiamo inoltre visto più operazioni come rinominare l'intestazione e contare il numero di righe e colonne.
Articoli consigliati
Questa è una guida ai file R CSV. Qui discutiamo della creazione, lettura e scrittura di file CSV in R con le Operazioni CSV. Puoi anche leggere il seguente articolo per saperne di più -
- JSON vs CSV
- Processo di data mining
- Carriere nell'analisi dei dati
- Excel vs CSV