
Introduzione alla pipeline di dati AWS
I dati crescono esponenzialmente di giorno in giorno e diventano difficili da gestire rispetto al passato. Abbiamo bisogno di strumenti e servizi per gestire i nostri dati in modo efficiente ea un costo inferiore, qui viene in mente la pipeline di dati AWS. Non si tratta solo di archiviare i dati, ma è necessario analizzare, elaborare, trasformare i dati nella forma desiderata nello stesso posto, tutto ciò può essere ottenuto con AWS Data Pipeline.
Necessità di pipeline di dati
Proviamo a capire la necessità di una pipeline di dati con l'esempio:
Esempio 1
Abbiamo un sito Web che visualizza immagini e gif sulla base di ricerche o filtri degli utenti. Il nostro obiettivo principale è servire i contenuti. Ci sono alcuni obiettivi da raggiungere che sono i seguenti: -
- Migliorare la consegna dei contenuti: servire ciò che gli utenti desiderano in modo efficiente e abbastanza veloce.
- Gestire l'applicazione in modo efficiente: memorizzazione dei dati dell'utente e dei registri dei siti Web per scopi analitici successivi.
- Migliorare il business: l' utilizzo dei dati e delle analisi archiviati prende la decisione di migliorare il business a un costo inferiore.
Esempio n. 2
Ci sono alcuni colli di bottiglia da gestire per il raggiungimento degli obiettivi:
- L'enorme quantità di dati in diversi formati e in luoghi diversi che rende complessa l'elaborazione, l'archiviazione e la migrazione dei dati.
Diversi componenti di archiviazione dei dati per diversi tipi di dati:
- Possibili dati in tempo reale per gli utenti registrati: Dynamo DB .
- Registri di server Web per potenziali utenti: Amazon S3 .
- Dati demografici e credenziali di accesso: Amazon RDS.
- Dati del sensore e set di dati di terze parti: Amazon S3.
soluzioni
- Soluzione fattibile: possiamo vedere che abbiamo a che fare con diversi tipi di strumenti per convertire i dati da non strutturati a strutturati per l'analisi. Qui dobbiamo usare diversi strumenti per archiviare i dati e di nuovo per convertire, analizzare e archiviare i dati elaborati. Non è una soluzione economica.
- Soluzione ottimale: utilizzare una pipeline di dati che gestisca l'elaborazione, la visualizzazione e la migrazione. La pipeline di dati può essere utile nella migrazione di dati da luoghi diversi, analizzando anche i dati e l'elaborazione nella stessa posizione per conto dell'utente.
Che cos'è la pipeline di dati AWS?
AWS Data Pipeline è fondamentalmente un servizio Web offerto da Amazon che ti aiuta a trasformare, elaborare e analizzare i tuoi dati in modo scalabile e affidabile, nonché a archiviare i dati elaborati in S3, DynamoDb o nel tuo database locale.
- Con AWS Data Pipeline puoi accedere facilmente ai dati da diverse fonti.
- Trasforma ed elabora i dati su larga scala.
- Trasferisci in modo efficiente i risultati ad altri servizi come S3, tabella DynamoDb o archivio dati locale.
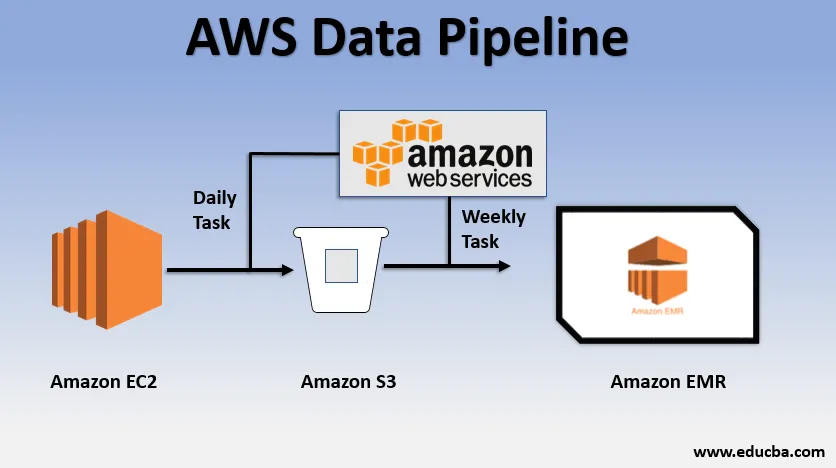
Esempio di utilizzo di base della pipeline di dati
- Potremmo avere un sito Web distribuito su EC2 che genera log ogni giorno.
- Una semplice attività quotidiana può essere copiata dai file di registro di E2 e portarli nel bucket S3.
- Un'attività settimanale potrebbe essere quella di elaborare i dati e avviare l'analisi dei dati su Amazon EMR per generare report settimanali sulla base di tutti i dati raccolti.
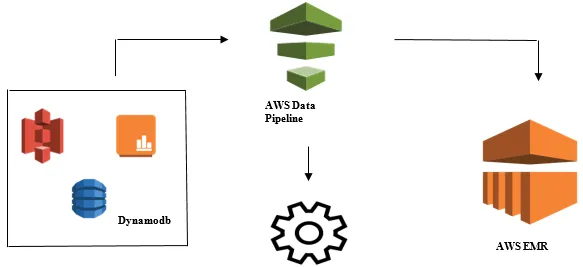
Avvio di Data Analysis con AWS Data Pipeline
- Raccolta dei dati da diverse origini dati come: S3, Dynamodb, locale, dati del sensore, ecc.
- Esecuzione di trasformazione, elaborazione e analisi su AWS EMR per generare report settimanali.
- Rapporto settimanale salvato in Redshift, S3 o database locale.
Vantaggi della pipeline di dati AWS
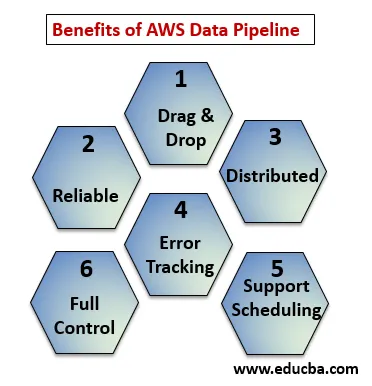
Di seguito i punti spiegano i vantaggi di AWS Data Pipeline:
- Trascina e rilascia console che è facile da capire e usare.
- Infrastruttura distribuita e affidabile: le pipeline di dati vengono eseguite su servizi scalabili e sono affidabili in caso di errori o attività non riuscite, pertanto è possibile riprovare.
- Supporta la pianificazione e il monitoraggio degli errori: puoi pianificare le tue attività e monitorarle in caso di errori e successo.
- Distribuito: può essere eseguito in parallelo su più macchine o in modo lineare.
- Pieno controllo su risorse computazionali come EC2, cluster EMR.
Componenti della pipeline di dati AWS
Di seguito sono riportati i componenti della pipeline di dati AWS:
1. Definizione della pipeline
Converti la tua logica di business nella pipeline di dati AWS.
- Nodi dati : contiene il nome, la posizione, il formato dell'origine dati che potrebbe essere (S3, dynamodb, locale)
- Attività : spostare, trasformare o eseguire query sui dati.
- Programma : programma le tue attività quotidiane o settimanali.
- Pre-condizione : condizioni come l'avvio dello scheduler verificano la disponibilità dei dati alla fonte.
- Risorse : risorse di calcolo EC2, EMR.
- Azioni : aggiornamento su pipeline di dati, invio di notifiche, attivazione di allarmi.
2. Condutture
Qui è possibile pianificare ed eseguire le attività per eseguire attività definite.
- Componenti della pipeline C. I componenti della pipeline sono gli stessi dei componenti della definizione della pipeline.
- Istanze: durante l'esecuzione delle attività AWS compila tutti i componenti per creare determinate istanze utilizzabili. Tali istanze hanno tutte le informazioni su compiti specifici.
- Tentativi: abbiamo già discusso dell'affidabilità della pipeline di dati con i suoi meccanismi di tentativo. Qui si imposta quante volte si desidera riprovare l'attività in caso di errore.
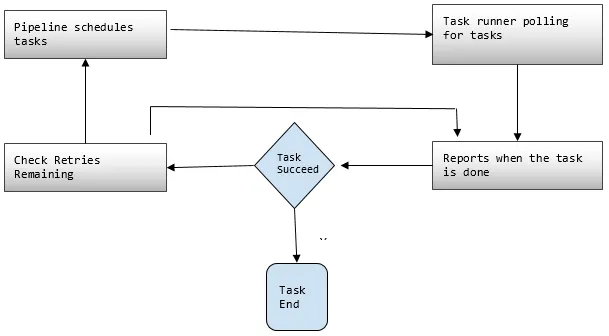
3. Task Runner
Chiede o esegue il polling delle attività dalla pipeline di dati AWS e quindi esegue tali attività.
Prezzi della pipeline di dati AWS
Di seguito i punti spiegano i prezzi della pipeline dei dati AWS:
1. Livello gratuito
Puoi iniziare a utilizzare AWS Data Pipeline gratuitamente come parte del livello di utilizzo gratuito di AWS. I nuovi clienti registrati ottengono ogni mese alcuni vantaggi gratuiti per un anno:
- 3 Presupposti per la bassa frequenza in esecuzione su AWS senza alcun addebito.
- 5 Attività di bassa frequenza in esecuzione su AWS senza alcun costo.
2. Bassa frequenza
La bassa frequenza è pensata per essere eseguita una volta al giorno o meno. La pipeline di dati segue la stessa strategia di fatturazione degli altri servizi Web AWS, ovvero fatturata in base al tuo utilizzo. Viene fatturata sulla frequenza con cui le attività, le attività e le condizioni preliminari vengono eseguite ogni giorno e dove vengono eseguite (AWS o locale). Le attività ad alta frequenza sono programmate per essere eseguite più di una volta al giorno.
Esempio: possiamo pianificare un'attività da eseguire ogni ora ed elaborare i registri del sito Web o potrebbe essere ogni 12 ore. Considerando che, le attività a bassa frequenza sono quelle che si svolgono una volta al giorno o meno se non sono soddisfatte le condizioni preliminari. Le pipeline inattive hanno gli stati INATTIVO, IN ATTESA e FINITO.
3. Prezzi della pipeline di dati AWS illustrati in base alla regione
Regione n. 1: Stati Uniti orientali (Nord Virginia), Stati Uniti occidentali (Oregon), Asia Pacifico (Sydney), UE (Irlanda)
| Alta frequenza | Bassa frequenza | |
| Attività o condizioni preliminari in esecuzione su AWS | $ 1, 00 al mese | $ 0, 06 al mese |
| Attività o condizioni preliminari in esecuzione in locale | $ 2, 50 al mese | $ 1, 50 al mese |
| Pipeline inattive: $ 1, 00 al mese |
Regione n. 2: Asia Pacifico (Tokyo)
| Alta frequenza | Bassa frequenza | |
| Attività o condizioni preliminari in esecuzione su AWS | $ 0, 9524 al mese | $ 0, 5715 al mese |
| Attività o condizioni preliminari in esecuzione in locale | $ 2, 338 al mese | $ 1, 4286 al mese |
| Pipeline inattive: $ 0, 9524 al mese |
La pipeline secondo cui un lavoro quotidiano, ovvero un'attività a bassa frequenza su AWS per spostare i dati dalla tabella DynamoDB ad Amazon S3, costerebbe $ 0, 60 al mese. Se aggiungiamo EC2 per produrre un report basato sui dati di Amazon S3, il costo totale della pipeline sarebbe di $ 1, 20 al mese. Se eseguiamo questa attività ogni 6 ore, costerebbe $ 2, 00 al mese, perché sarebbe un'attività ad alta frequenza.
Conclusione
AWS Data Pipeline è una soluzione molto utile per gestire i dati in crescita esponenziale a un costo inferiore. È molto affidabile e scalabile in base al tuo utilizzo. Per qualsiasi esigenza aziendale in cui si tratti di una grande quantità di dati, AWS Data Pipeline è un'ottima scelta per raggiungere tutti i nostri obiettivi aziendali.
Articoli consigliati
Questa è una guida alla pipeline di dati AWS. Qui discutiamo le esigenze della pipeline di dati, cos'è la pipeline di dati AWS, i suoi componenti e i dettagli dei prezzi. Puoi anche consultare i nostri altri articoli correlati per saperne di più -
- AWS EBS
- Database AWS
- Che cos'è AWS EC2?
- Vantaggi della visualizzazione dei dati
- I 7 principali concorrenti di AWS con funzionalità
- Scopri l'elenco delle funzionalità dei servizi Web di Amazon