

Differenza tra MapReduce e Spark
Map Reduce è un framework open source per la scrittura di dati in HDFS e l'elaborazione di dati strutturati e non strutturati presenti in HDFS. Map Reduce è limitato all'elaborazione batch e su altri Spark è in grado di eseguire qualsiasi tipo di elaborazione. SPARK è un motore di elaborazione indipendente per l'elaborazione in tempo reale che può essere installato su qualsiasi file system distribuito come Hadoop. SPARK offre prestazioni 10 volte più veloci di Map Reduce su disco e 100 volte più veloci di Map Reduce su una rete in memoria.
Need For SPARK
- Analisi iterativa: la riduzione della mappa non è efficiente come SPARK per risolvere i problemi che richiedono un'analisi iterativa in quanto deve andare su disco per ogni iterazione.
- Interactive Analytics: la riduzione della mappa viene spesso utilizzata per eseguire query ad hoc per le quali è necessario accedere alla memoria su disco, che di nuovo non è efficiente come SPARK perché quest'ultima si riferisce alla memoria più veloce.
- Non adatto per OLTP: poiché funziona sul framework orientato al batch, non è adatto per un gran numero di transazioni brevi.
- Non adatto per il grafico: la libreria Grafico di Apache elabora il grafico che aggiunge più complessità a Map Reduce.
- Non adatto per operazioni banali: per operazioni come un filtro e join potrebbe essere necessario riscrivere i lavori, il che diventa più complesso a causa del modello di valori-chiave.
Confronto testa a testa tra MapReduce vs Spark (infografica)
Di seguito sono elencate le prime 15 differenze tra MapReduce e Spark

Differenze chiave tra MapReduce e Spark
Di seguito sono elencati gli elenchi di punti, descrivono le principali differenze tra MapReduce e Spark:
- Spark è adatto per il real-time in quanto elabora in memoria mentre MapReduce è limitato all'elaborazione batch.
- Spark ha RDD (Resilient Distributed Dataset) che ci offre operatori di alto livello ma in Map Reduce dobbiamo codificare ogni singola operazione rendendola relativamente difficile.
- Spark può elaborare grafici e supporta lo strumento di apprendimento automatico.
- Di seguito è la differenza tra l'ecosistema MapReduce vs Spark.
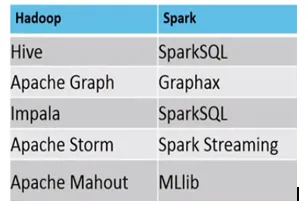
Esempio, dove MapReduce vs Spark sono adatti, sono i seguenti
Spark: rilevamento di frodi con carta di credito
MapReduce: creazione di report regolari che richiedono processi decisionali.
Tabella di confronto MapReduce vs Spark
| Base di confronto | Riduci mappa | Scintilla |
| Struttura | Un framework open source per la scrittura di dati in HDFS e l'elaborazione di dati strutturati e non strutturati presenti in HDFS. | Un framework open source per l'elaborazione dei dati più rapida e generica |
| Velocità | Map-Reduce elabora i dati (legge e scrive) dal disco in modo che il seep sia lento rispetto a Spark. | Spark è almeno 10 volte più veloce su disco e 100 volte più veloce in memoria come quello di Map Reduce. |
| Difficoltà | Dobbiamo codificare / gestire ogni processo. | Con la disponibilità di RDD (Resilient Distributed Dataset), è facile da programmare. |
| Tempo reale | Non adatto per la transazione OLTP solo per la modalità batch | Può gestire l'elaborazione in tempo reale. Utilizzo di SPARK Streaming. |
| Latenza | Framework di calcolo della latenza di alto livello | Framework di elaborazione della latenza di basso livello. |
| Tolleranza ai guasti | I demoni master controllano il battito cardiaco dei demoni slave e, nel caso in cui i demoni slave falliscano, i demoni master riprogrammano tutte le operazioni in sospeso e in corso su un altro slave. | Gli RDD offrono tolleranza di errore a SPARK. Si riferiscono al set di dati presente nella memoria esterna come (HDFS, HBase) e funzionano in parallelo. |
| Scheduler | In Map Reduce utilizziamo uno scheduler esterno come Oozie. | Mentre SPARK lavora con il computing in memoria, funge da proprio scheduler. |
| Costo | Map Reduce è relativamente più economico rispetto a SPARK. | Poiché funziona in memoria, richiede molta RAM, rendendolo relativamente più costoso. |
| Piattaforma sviluppata su | Map Reduce è stato sviluppato utilizzando Java. | SPARK è stato sviluppato utilizzando Scala. |
| Lingua supportata | Map Reduce fondamentalmente supporta C, C ++, Ruby, Groovy, Perl, Python. | Spark supporta Scala, Java, Python, R, SQL. |
| Supporto SQL | Map Reduce esegue query utilizzando Hive Query Language. | Spark ha il suo linguaggio di query noto come Spark SQL. |
| scalabilità | In Map Reduce possiamo aggiungere fino a n numero di nodi. Il più grande cluster Hadoop ha 14000 nodi. | In Spark possiamo anche aggiungere n numero di nodi. Il cluster Spark più grande ha 8000 nodi. |
| Apprendimento automatico | Map Reduce supporta lo strumento Apache Mahout per l'apprendimento automatico. | Spark supporta lo strumento MLlib per l'apprendimento automatico. |
| caching | La riduzione della mappa non è in grado di memorizzare nella cache i dati della memoria, quindi non è così veloce rispetto a Spark. | Spark memorizza nella cache i dati in memoria per ulteriori iterazioni, quindi è molto veloce rispetto a Map Reduce. |
| Sicurezza | Map Reduce supporta più progetti e funzionalità di sicurezza rispetto a Spark | La sicurezza Spark non è ancora maturata come quella di Map Reduce |
Conclusione - MapReduce vs Spark
Secondo la precedente differenza tra MapReduce e Spark, è abbastanza chiaro che SPARK è un motore di elaborazione molto più avanzato rispetto a Map Reduce. Spark è compatibile con qualsiasi tipo di formato di file e anche molto più veloce di Map Reduce. La scintilla inoltre ha anche capacità di elaborazione dei grafici e di apprendimento automatico.
Da un lato, Map Reduce è limitato all'elaborazione batch e dall'altro Spark è in grado di eseguire qualsiasi tipo di elaborazione (batch, interattiva, iterativa, streaming, grafico). A causa della grande compatibilità Spark è il preferito di Data Scientist e quindi sostituisce Map Reduce e cresce rapidamente. Tuttavia, dobbiamo ancora archiviare i dati in HDFS e in alcuni casi potrebbe essere necessario HBase. Quindi dobbiamo eseguire sia Spark che Hadoop per ottenere il meglio.
Articoli consigliati:
Questa è stata una guida a MapReduce vs Spark, il loro significato, confronto testa a testa, differenze chiave, tabella di confronto e conclusioni. Puoi anche consultare i seguenti articoli per saperne di più -
- 7 cose importanti su Apache Spark (Guida)
- Hadoop vs Apache Spark - Cose interessanti che devi sapere
- Apache Hadoop vs Apache Spark | I 10 migliori confronti che devi sapere!
- Come funziona MapReduce?
- Confluenza di tecnologia e analisi aziendale