
Strutture dati e algoritmi C ++
Strutture dati e algoritmi C ++: significa organizzare o organizzare gli elementi in un modo particolare. Quando diciamo che dobbiamo disporre gli elementi, tali elementi possono essere organizzati in diverse forme. Ad esempio, le calze possono essere organizzate in vari modi. Puoi semplicemente tenerlo nell'armadio tutto incasinato. Oppure puoi tenerlo ben piegato. Il modo migliore può essere piegare e disporre i colori in modo saggio. Quindi, per cercare un particolare paio di calzini, la terza disposizione è perfetta.
In un modo simile di organizzazione delle calze, i dati possono anche essere organizzati in diversi modi o forme. Questi diversi modi di organizzare i dati sono chiamati struttura dei dati. Vediamo una definizione formale di una struttura di dati e le basi di strutture e algoritmi di dati.
Strutture dati e algoritmi C ++:
Il modello logico o matematico di una particolare organizzazione di dati.
O
È un modo particolare di organizzare i dati in un computer in modo che possano essere utilizzati.
Allo stesso modo delle calze; diversa organizzazione delle strutture di dati elenco e algoritmi disponibili C ++ è -
- Vettore
- Lista collegata
- Pila
- Coda
- Albero
- Grafico
- Tabella hash
- Mucchio
- Records
- tabelle
Queste strutture di dati e algoritmi C ++ sono molto importanti durante la programmazione. Un buon programmatore dà sempre enfasi alla struttura dei dati piuttosto che al codice. Ogni linguaggio di programmazione funziona su varie strutture di dati e algoritmi in C ++. Le strutture di dati disponibili in C ++ sono le seguenti.
- Vettore
- Lista collegata
- Pila
- Coda
- Albero
- Grafico
- Tabella hash
- Mucchio
Discutiamolo uno per uno:
Matrice n. 1
L'array è un tipo più semplice di strutture dati e algoritmi C ++. L'array è definito come una raccolta sequenziale di dimensioni fisse di elementi di dati dello stesso tipo di dati. Ad esempio a0 = 12, a1 = 21, a2 = 14, a3 = 15…. Possiamo rappresentare un array monodimensionale come mostrato in figura:
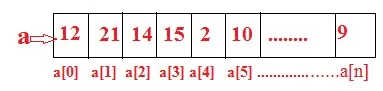
Dove
0, 1, 2, 3… ..n è chiamato indice o indice
a (1), a (2), … a (n) è chiamato variabile di indice
Può essere monodimensionale, bidimensionale, tridimensionale e così via multidimensionale.
Nell'array di memoria vengono archiviati in posizioni di memoria contigue.
L'indirizzo più basso corrisponde al primo elemento
L'indirizzo più alto corrisponde all'ultimo elemento
Possiamo dichiarare l'array 1-D (1-dimensionale) in C ++ come segue
dataType arrayName (arraySize);
Ad esempio int num (5);
Inizializzazione di array in C ++
num = (23, 10, 12, 3, 6);
Possiamo combinare la dichiarazione e l'inizializzazione in una singola istruzione come segue.
int num = (23, 10, 12, 3, 6);
Quando vogliamo allocare dinamicamente la dimensione di un array, dovremmo nuovo operatore come segue
int * a = new int (size);
Lo svantaggio dell'array è l'inserimento e l'eliminazione degli elementi è lenta come nell'array ordinato e nella sua memoria a dimensioni fisse.
# 2 Elenco collegato
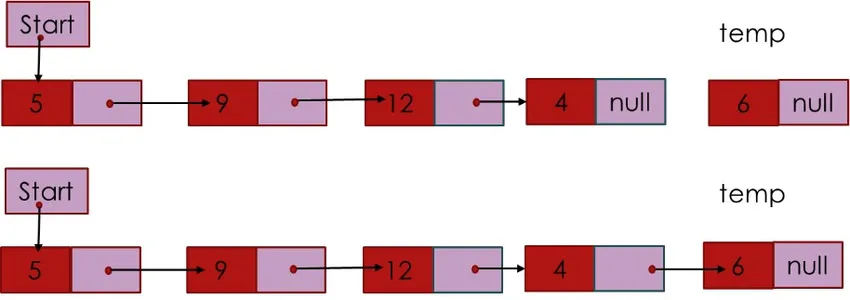
L'elenco fa riferimento a una raccolta lineare di elementi. Un elenco collegato è una serie di nodi collegati (elemento dati) come mostrato nella Figura 3. Il nodo di intestazione punta al primo nodo dell'elenco e l'ultimo nodo punta a NULL indicato daÆ. Poiché ogni nodo contiene almeno.
- Un pezzo di dati (qualsiasi tipo)
- Puntatore al nodo successivo nell'elenco
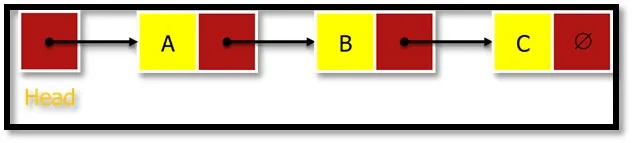
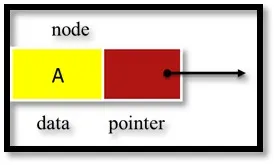
L'elenco collegato è rappresentato in memoria usando due array. Un array memorizza informazioni chiamate informazioni che sono dati da archiviare e altri memorizzano il campo del puntatore successivo chiamato LINK che è un indirizzo del nodo successivo.
Un vantaggio di un elenco collegato su un array:
Sia un array che un elenco collegato sono rappresentazioni di un elenco di elementi in memoria. La differenza importante è il modo in cui gli elementi sono collegati insieme. Il limite principale dell'array è l'inserimento degli elementi nell'array e la cancellazione degli elementi dall'array ordinato è difficile in quanto gli elementi di riposo devono essere spostati. L'inserimento e la cancellazione di elementi da un elenco collegato sono molto semplici.
Impara a progettare e personalizzare i programmi per varie piattaforme. Codice, test, debug e implementazione di applicazioni software. Sviluppare competenze per garantire il corretto funzionamento delle applicazioni.
I tipi di elenco collegato sono:
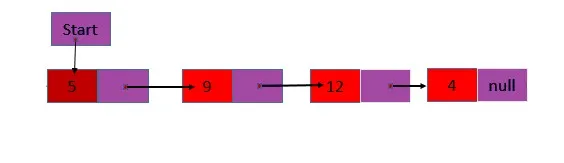
1. Elenco collegato singolarmente : contiene un solo campo collegato che contiene l'indirizzo del nodo successivo nell'elenco e le informazioni archiviate che contengono le informazioni da memorizzare.
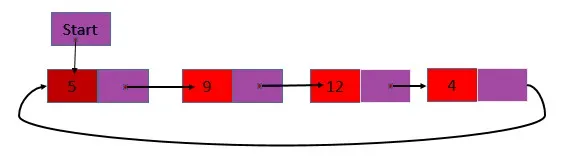
2. L'elenco collegato a una sola circolare è solo un elenco ma l'ultimo nodo dell'elenco contiene l'indirizzo del primo nodo anziché null. Questo è il contenuto di head e il campo successivo dell'ultimo nodo sono gli stessi.
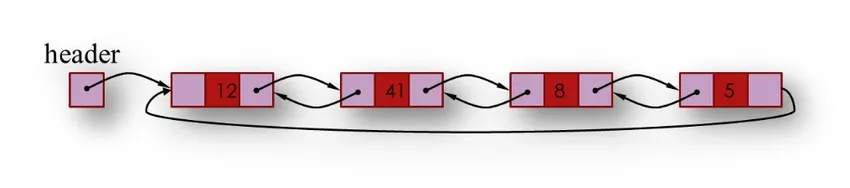
3. L'elenco doppiamente collegato contiene due campi collegati precedente e successivo. Un campo precedentemente collegato che contiene un indirizzo del nodo precedente nell'elenco e il campo collegato successivo contiene l'indirizzo del nodo successivo nell'elenco e le informazioni archiviate contengono le informazioni come archivio.

4. La doppia lista collegata circolare è doppiamente collegata ma il campo successivo dell'ultimo nodo contiene l'indirizzo del primo nodo anziché null.
Corsi consigliati
- Corso su VB.NET
- Formazione sulla programmazione di data science
- Corso ISTQB online
- Corso di formazione Kali Linux
L'implementazione dell'elenco collegato in C ++ comporta la creazione di un nodo, l'eliminazione di un nodo dall'elenco, l'inserimento di un nodo appena creato nell'elenco e la ricerca di un nodo con una chiave particolare.
Il codice per la creazione del nodo è dato come segue:

L'inserimento di un nodo nell'elenco comporta tre casi
1. Inserire un nodo all'inizio significa inserire il nodo appena creato come nodo iniziale. Per inserire un nodo all'inizio, è stato innanzitutto creato un nuovo nodo e fare in modo che il nuovo nodo punti al vecchio inizio, quindi aggiornare start in modo che punti al nuovo nodo come mostrato nella figura seguente:
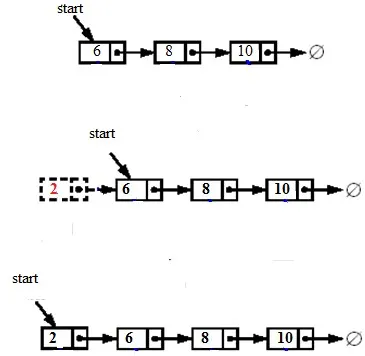
Codice per l' inserimento di un nodo all'inizio:
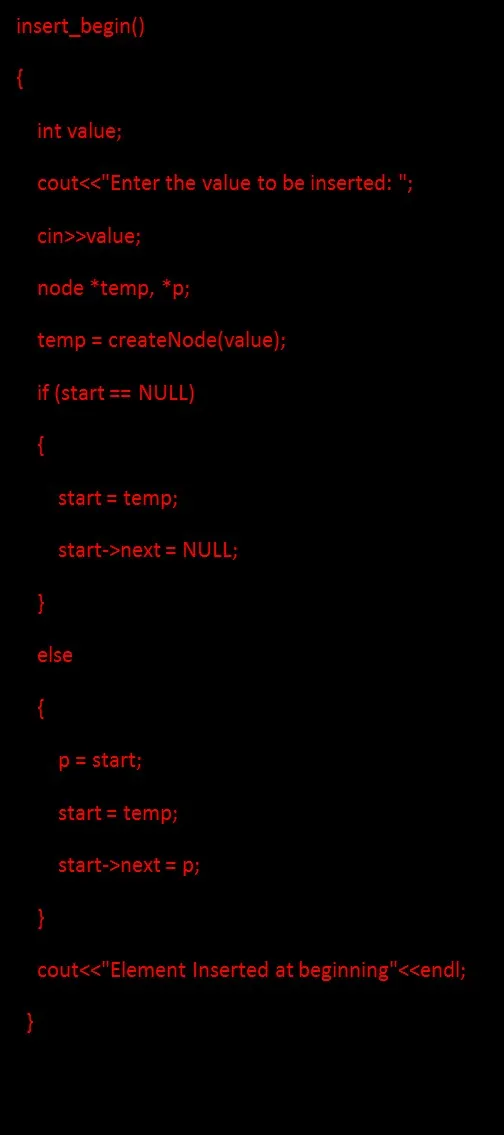
2. Inserire un nodo in coda significa inserire il nodo appena creato come ultimo nodo. Per inserire il nodo come nodo di coda è necessario creare un nuovo nodo e fare in modo che il vecchio ultimo nodo punti al nuovo nodo e quindi aggiorni la coda per puntare a un nuovo nodo.
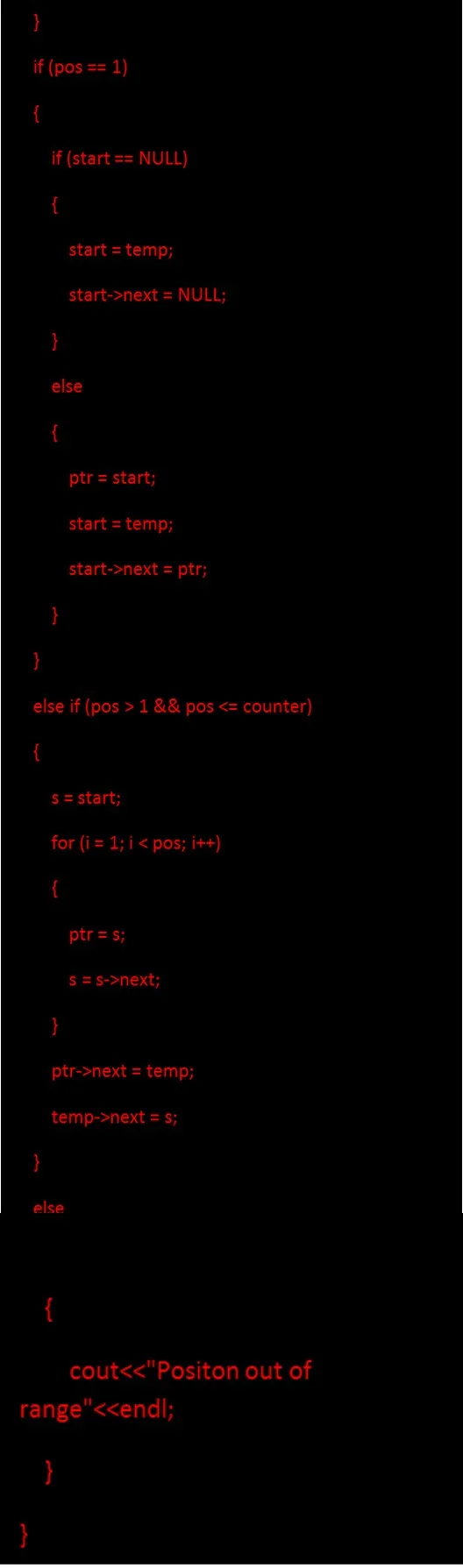
3. L' inserimento di un nodo in una determinata posizione comporta la creazione di un nuovo nodo temporaneo, quindi è necessario trovare la posizione di inserimento del nodo appena creato.
Codice per l'inserimento del nodo in una determinata posizione:

L'eliminazione di un nodo dall'elenco comporta la rimozione di un nodo dall'elenco esistente. La cancellazione del nodo dall'elenco dei collegamenti è semplice rispetto all'inserimento di un nodo nell'elenco. Nel codice C ++ per la cancellazione del nodo è dato come segue:

Attraversando un nodo con una chiave particolare (valore) da un elenco, verrà cercato un nodo dall'elenco le cui informazioni corrisponderanno alla chiave di un determinato nodo. Il seguente codice C ++ attraverserà un elenco. strutture dati e algoritmi C ++


Stack n. 3
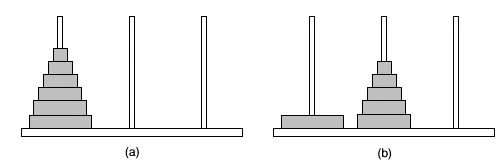
Una pila è un elenco di elementi in cui un elemento può essere inserito o eliminato solo a un'estremità, chiamato la parte superiore della pila. Considera l'esempio di una torre di Hanoi. Qui quando dobbiamo inserire un disco dobbiamo inserirlo solo dall'alto e allo stesso modo la rimozione del disco avviene solo dall'alto.
Stack utilizza il principio LIFO significa che funziona nell'ordine Last in First Out. Questo è l'ultimo elemento aggiunto allo stack è il primo elemento di rimozione. Quindi ci sono quattro operazioni di base che possono essere eseguite nello stack:
- Isempty: questa operazione verifica se lo stack è vuoto.
- Push : questa operazione aggiunge un nuovo oggetto da impilare.
- Pop: questa operazione rimuove un oggetto dallo stack aggiunto più di recente.
- In alto: questa operazione restituisce l'elemento che è stato aggiunto allo stack più di recente.
La seguente figura è un esempio della pila in cui l'inserimento nella pila e la rimozione da una pila dell'articolo avviene dalla cima della pila e da nessun'altra parte.
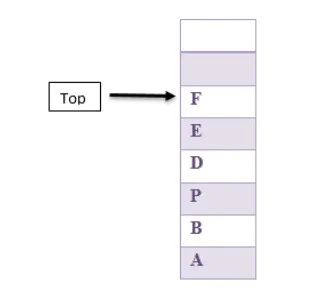
Stack overflow
La condizione risultante dal tentativo di spingere un elemento su uno stack completo.
Stack underflow
La condizione risultante dal tentativo di far apparire uno stack vuoto.
Qui abbiamo mostrato alcune operazioni push e pop in pila. Supponiamo che inizialmente lo stack sia vuoto, quindi abbiamo aggiunto F, A, M, R, N. Quindi pop due volte e premi N, H, B, T, K, O, P.
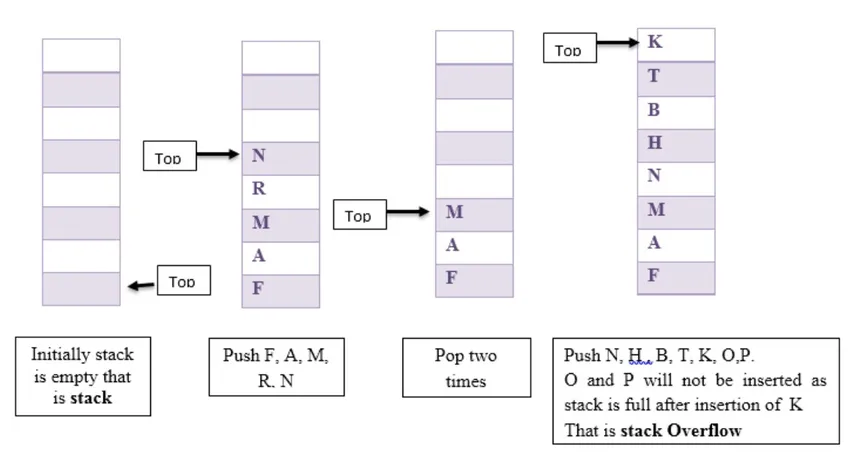
Implementazione di Stack:
Può essere implementato utilizzando un array o un elenco collegato entrambi.
Di seguito è riportato il codice che mostra come lo stack è implementato in C ++ usando Class. Qui è stata definita una classe denominata come stack in cui è stato creato un array denominato stick con dimensioni dinamiche e due funzioni principali push e pop.
Stack Overflow: When top> = size-1
Stack underflow: quando in alto <0

Articoli Correlati:-
Ecco alcuni articoli correlati alle strutture di dati e agli algoritmi C ++ che ti aiuteranno a ottenere maggiori dettagli sugli algoritmi C ++ e le strutture di dati e gli algoritmi che passano così gentilmente attraverso il link che viene fornito di seguito. se ti piacciono le strutture di dati dell'articolo e gli algoritmi C ++, dacci il tuo prezioso commento.
- Cheat sheet per il linguaggio di programmazione C ++
- Linux vs Ubuntu
- Domande di intervista in C ++ che devi conoscere
- Strutture di dati e algoritmi Domande di intervista | Il più utile
- Il miglior articolo per algoritmi e crittografia (esempi)
- 8 domande e risposte di intervista sull'algoritmo eccezionale
- Guida straordinaria su Kali Linux vs Ubuntu
- C ++ Vector vs Array: quali sono le funzioni migliori