

Introduzione all'architettura HBase
HBase è un sistema di archiviazione dei dati chiave-valore distribuito open source e database orientato alle colonne con output di scrittura elevato e prestazioni di lettura casuale a bassa latenza. Usando HBase, possiamo eseguire analisi online in tempo reale. L'architettura HBase ha una forte leggibilità casuale. In HBase, i dati sono suddivisi fisicamente in quelle che sono conosciute come regioni. Ogni regione è ospitata da un singolo server di area e una o più aree sono responsabili di ciascun server di area. L'architettura HBase è composta da server master-slave. Il cluster HBase ha un nodo Master chiamato HMaster e diversi server regionali chiamati HRegion Server (HRegion Server). Esistono più aree: aree in ciascun server regionale.
Meccanismo di archiviazione HDFS

In HDFS, i dati sono archiviati nella tabella come mostrato sopra.
Ogni riga ha una chiave.
Colonna: è una raccolta di dati che appartiene a una famiglia di colonne ed è inclusa nella riga.
Famiglia di colonne: ogni famiglia di colonne è composta da una o più colonne.
Ogni tabella contiene una raccolta di famiglie di colonne. Queste colonne non fanno parte dello schema.
HBase ha colonne dinamiche. Le diverse celle possono avere colonne diverse perché i nomi delle colonne sono codificati all'interno delle celle
Qualificatore di colonna: il nome della colonna è noto come qualificatore di colonna.
Componenti dell'architettura HBase
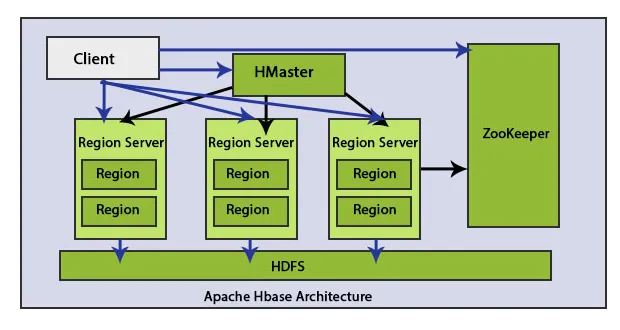
Ci sono elementi principali nell'architettura HBase: HMaster e Region Server. Dati di salvataggio regionali HBase.
1. HMaster
Il nodo HMaster è leggero e utilizzato per assegnare la regione alla regione del server.
Ci sono alcune principali responsabilità di Hmaster che sono:
- Esecuzione di alcune attività amministrative, tra cui caricamento, bilanciamento, creazione di dati, aggiornamento, cancellazione, ecc.
Responsabile delle modifiche allo schema o delle modifiche ai dati META secondo la direzione dell'applicazione client
- Gran parte del lavoro DDL sulle tabelle HBase è gestito da HMaster.
Alcuni dei metodi esposti da HMaster Interface sono principalmente. Metodi orientati ai dati META.
- Tabella (crea, rimuovi, abilita, disabilita, rimuovi tabella)
- ColumnFamily (aggiungi colonna, modifica colonna)
- Regione (sposta, assegna)
Il client comunica in modo bidirezionale sia con HMaster sia con ZooKeeper. Contatta direttamente i server HRegion per leggere e scrivere operazioni. HMaster assegna le regioni ai server della regione e, a sua volta, controlla lo stato di integrità dei server regionali.
2. Region Server
Possiamo avere un'idea approssimativa del server della regione tramite uno schema riportato di seguito.

I server delle regioni sono nodi di lavoro che gestiscono le richieste dei clienti di lettura, scrittura, aggiornamento ed eliminazione. Region Server è leggero, funziona su tutti i nodi del cluster Hadoop. Il compito principale del server della regione è salvare i dati nelle aree ed eseguire le richieste dei clienti. Un altro compito importante di HBase Region Server è utilizzare il metodo Auto-Sharding per eseguire il bilanciamento del carico distribuendo dinamicamente la tabella HBase quando diventa troppo grande dopo aver inserito i dati.
HMaster può contattare più server HRegion ed eseguire le seguenti funzioni:
- Hosting di gestione e regioni
- Suddividi automaticamente le regioni
- Gestione delle richieste di lettura e scrittura
- Comunicazione diretta con il cliente
3. HDFS
HDFS è l'acronimo di Hadoop Distributed File system. Memorizza ogni file in più blocchi e replica i blocchi in un cluster Hadoop per mantenere la tolleranza agli errori. HDFS offre un'elevata tolleranza ai guasti e funziona con materiali a basso costo. Utilizzando hardware economico per aggiungere nodi al cluster, elaborarlo e salvarlo, si otterranno risultati migliori del cliente rispetto all'hardware esistente. HDFS contatta i componenti di HBase e salva molti dati in modo distribuito.
4. Zookeeper
Zookeeper è un progetto open source. HMaster e HRegionServers si registrano con ZooKeeper.
Fornisce vari servizi come la gestione delle informazioni di configurazione, la denominazione, la sincronizzazione distribuita, ecc. La sincronizzazione distribuita è il processo di fornitura di servizi di coordinamento tra nodi per accedere alle applicazioni in esecuzione. Ha nodi effimeri che rappresentano i server delle regioni. I server master utilizzano questi nodi per cercare i server disponibili.
Questi nodi vengono anche utilizzati per tenere traccia delle partizioni di rete e degli errori del server. Zookeeper è il mezzo di interazione tra il server della regione client. Se un client desidera comunicare con il server della regione, Zookeeper è il mezzo di comunicazione tra di loro.
Come inizializza la ricerca nell'architettura HBase
Come sapete, la posizione della tabella META viene salvata da Zookeeper. Ogni volta che un cliente si avvicina o scrive richieste per HBase, la procedura è la seguente.
Il cliente scopre da ZooKeeper come posizionarli nella tabella META. Il client richiede quindi la chiave di riga appropriata dalla tabella META per accedere alla posizione del server della regione. Con la posizione della tabella META, il cliente memorizza nella cache queste informazioni. Il cliente non deve fare riferimento alla tabella META fino a quando e se l'area viene spostata o spostata. Quindi il server META verrà nuovamente richiesto e la cache verrà aggiornata. Come sempre, i clienti non perdono tempo a trovare la posizione del server della regione sul server META, quindi risparmia tempo e accelera il processo di ricerca.
Caratteristiche
È facile da integrare dalla fonte e dalla destinazione con Hadoop.
L'archiviazione distribuita come HDFS è supportata.
Ha una funzione di accesso casuale utilizzando una tabella hash interna per archiviare i dati per ricerche più veloci nei file HDFS.
Vantaggi dell'architettura HBase
- Questi possono archiviare set di dati di grandi dimensioni
- Possiamo condividere il database
- Gigabyte a petabyte convenienti
- Elevata disponibilità tramite replica e errore
Svantaggi dell'architettura HBase
- La struttura SQL non supporta
- Non supporta le transazioni
- Solo con chiave ordinata
- Problemi di memoria del cluster
Conclusione
HBase è uno dei database distribuiti orientati alla colonna NonSql in apache. Rispetto a Hadoop o Hive, HBase ha prestazioni migliori per il recupero di meno record. Quindi, in questo articolo, abbiamo discusso dell'architettura HBase e dei suoi componenti importanti.
Articoli consigliati
Questa è stata una guida all'architettura HBase. Qui abbiamo discusso il concetto, i componenti, le caratteristiche, i vantaggi e gli svantaggi. Puoi anche consultare i nostri altri articoli suggeriti per saperne di più -
- Che cos'è la tecnologia dei Big Data?
- HDFS vs HBase quale è meglio
- Che cos'è il linguaggio assembly?
- Introduzione all'HTML