

Differenza tra Hadoop e HBase
Hadoop è un framework Java open source, utilizzato per gestire ed elaborare un'enorme quantità di dati strutturati e non strutturati. Hadoop è enormemente scalabile, quindi viene utilizzato per elaborare carichi di lavoro di Big Data. I big data vengono archiviati, accessibili ed elaborati nel cluster affidabile ed espandibile. HBase (Hadoop Database) è un database non relazionale e non solo SQL, ovvero NoSQL, che viene eseguito in cima a Hadoop come archivio di dati di grandi dimensioni distribuito e scalabile. È un database open source in cui i dati sono archiviati sotto forma di righe e colonne, in quella cella si trova un'intersezione di colonne e righe.
Di seguito sono riportati i componenti principali dell'architettura Hadoop:
- Hadoop Distributed File System (HDFS): Hadoop include un sistema di archiviazione distribuito, Hadoop Distributed File System (HDFS). HDFS è l'architettura master-slave che archivia i dati attraverso il cluster. Dati distribuiti su più nodi slave dal nodo master nel blocco modulo. Il nodo principale si chiama Namenode e i nodi slave sono chiamati Datanode. HDFS è facilmente espandibile e memorizza un'enorme quantità di dati su Datanodes. HDFS ha un fattore di replica configurabile con valore predefinito 3 che può essere modificabile.
- MapReduce: MapReduce è un paradigma di programmazione, che elabora parallelamente un numero enorme di set di dati sulla rete. MapReduce fa riferimento a due diverse attività: mappare i dati di input in cui i dati divisi in un sottoinsieme di dati chiamati come tuple e l'attività di riduzione prende queste tuple dalla mappa come input e si combinano per formare l'output dell'originale.
- Filato: FILATO indica l'ennesimo navigatore di risorse che elabora risorse come la gestione della CPU e della memoria, la pianificazione delle richieste di risorse.
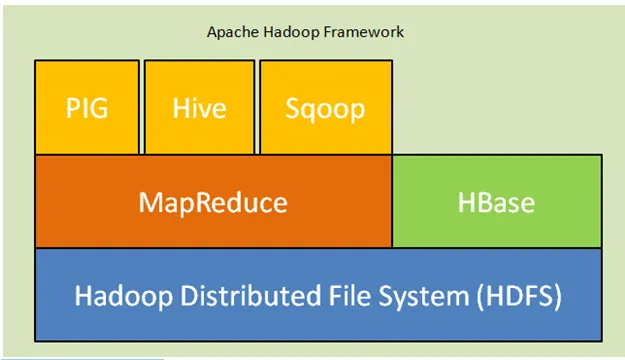
Fig. Apache Hadoop Framework
Il server della regione serve i dati per le operazioni di lettura / scrittura. Tutti i dati HBase sono memorizzati nel file HDFS. Il Datanode HDFS memorizza i dati gestiti dal Region Server. Il Namenode HDFS conserva le informazioni sui metadati per tutti i blocchi di dati fisici che compongono i file.
Il controllo delle versioni viene utilizzato per tenere traccia delle modifiche delle celle, mantenendo la versione dei contenuti. Da ciò è possibile recuperare qualsiasi versione del contenuto. Ogni valore di cella include l'attributo 'versione' rispetto al timestamp per recuperare la cella. Ogni valore nella mappa è un array ininterrotto di byte. La mappa è indicizzata da una chiave di riga, chiave di colonna e un timestamp. L'architettura di HBase è mappe altamente scalabili, sparse, distribuite, persistenti e ordinate multidimensionalmente.
Confronto testa a testa tra Hadoop vs HBase (infografica)
Di seguito è la differenza 7 principale tra Hadoop vs HBase
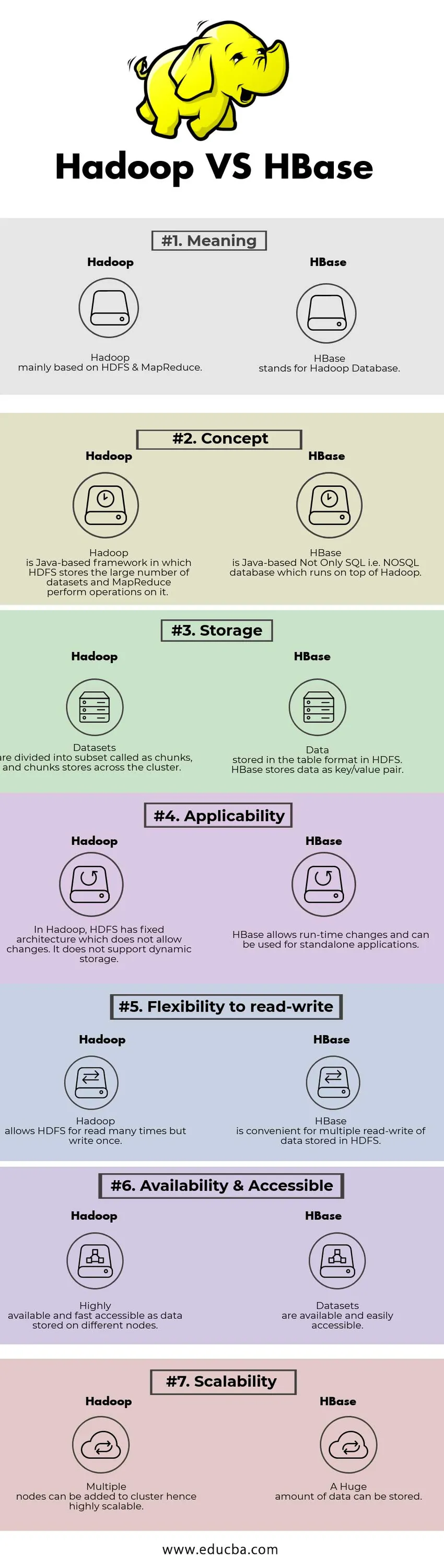
Differenze chiave tra Hadoop e HBase
La differenza tra Hadoop e HBase è spiegata nei punti presentati di seguito:
- Hadoop non è adatto per l'elaborazione analitica online (OLAP) e HBase fa parte dell'ecosistema Hadoop che fornisce accesso casuale in tempo reale (lettura / scrittura) ai dati nel file system Hadoop.
- Il framework Hadoop è tollerante ai guasti in base alla progettazione e supporta il trasferimento rapido dei dati tra i nodi anche durante guasti del sistema. HBase è un database Not-Only-SQL non relazionale e open source che viene eseguito su Hadoop. HBase rientra nel tipo di CP del teorema CAP (Coerenza, Disponibilità e Tolleranza alle partizioni).
- Hadoop è particolarmente adatto per eseguire analisi batch. Tuttavia, uno dei suoi maggiori svantaggi è la sua incapacità di eseguire analisi in tempo reale, il requisito di tendenza del settore IT. HBase, d'altra parte, può gestire grandi set di dati e non è appropriato per l'analisi batch. Invece, viene utilizzato per scrivere / leggere i dati da Hadoop in tempo reale.
- Sia Hadoop che HBase sono in grado di elaborare dati strutturati, semi-strutturati e non strutturati. In Hadoop, HDFS manca di un motore di elaborazione in memoria che rallenta il processo di analisi dei dati; come sta usando semplicemente MapReduce vecchio per farlo. HBase, al contrario, vanta un motore di elaborazione in memoria che aumenta drasticamente la velocità di lettura / scrittura.
- Hadoop è molto trasparente nell'esecuzione dell'analisi dei dati. HBase, invece, essendo un database NoSQL in formato tabulare, recupera i valori ordinandoli in valori chiave diversi.
Tabella comparativa Hadoop vs HBase
| BASE PER CONFRONTO | Hadoop | HBase |
| Senso | Hadoop si basa principalmente su HDFS e MapReduce. | HBase è l'acronimo di Hadoop Database. |
| Concetto | Hadoop è un framework basato su Java in cui HDFS memorizza il gran numero di set di dati e MapReduce esegue operazioni su di esso. | HBase è un database non solo SQL, ovvero NoSQL basato su Java, che gira su Hadoop. |
| Conservazione | I set di dati sono divisi in sottogruppi chiamati come blocchi e i blocchi di blocchi vengono archiviati in tutto il cluster. | Dati memorizzati nel formato tabella in HDFS. HBase memorizza i dati come coppia chiave / valore. |
| applicabilità | In Hadoop, HDFS ha un'architettura fissa che non consente modifiche. Non supporta l'archiviazione dinamica. | HBase consente modifiche al runtime e può essere utilizzato per applicazioni autonome. |
| Flessibilità di lettura-scrittura | Hadoop consente a HDFS di leggere molte volte ma di scrivere una volta. | HBase è utile per la lettura / scrittura multipla dei dati archiviati in HDFS |
| Disponibilità e accessibilità | Altamente disponibili e rapidamente accessibili come dati memorizzati su nodi diversi. | I set di dati sono disponibili e facilmente accessibili |
| scalabilità | Nodi multipli possono essere aggiunti al cluster, quindi altamente scalabili. | È possibile memorizzare un'enorme quantità di dati. |
Conclusione - Hadoop vs HBase
Architettura di Hadoop basata principalmente su HDFS e MapReduce. HBase è il componente di supporto nel sistema Hadoop. HBase è in grado di ospitare enormi tabelle e fornisce un rapido accesso casuale ai dati disponibili mentre HDFS è adatto per la memorizzazione di file di grandi dimensioni. Sia Hadoop che HBase forniscono un rapido accesso ai dati ma con HBase è possibile eseguire operazioni di lettura / scrittura e per HDFS leggere più volte e una volta eseguita la scrittura. Questo articolo ha descritto una comprensione di Hadoop e HBase, ha brevemente evidenziato le caratteristiche e confrontato saggiamente.
Articolo raccomandato
- Apache Hadoop vs Apache Spark | I 10 migliori confronti che devi sapere!
- Hadoop vs Hive - Scopri le migliori differenze
- HBase vs Cassandra - Quale è meglio (infografica)
- I 12 migliori confronti tra Apache Hive e Apache HBase (infografica)
- Hadoop vs Spark: quali sono le caratteristiche