
Che cos'è l'algoritmo SVM?
SVM sta per Support Vector Machine. SVM è un algoritmo di apprendimento automatico supervisionato che viene comunemente utilizzato per le sfide di classificazione e regressione. Le applicazioni comuni dell'algoritmo SVM sono Intrusion Detection System, Handwriting Recognition, Protein Structure Prediction, Detecting Steganography in image digital, ecc.
Nell'algoritmo SVM, ogni punto è rappresentato come un elemento di dati all'interno dello spazio n-dimensionale in cui il valore di ogni caratteristica è il valore di una coordinata specifica.
Dopo la stampa, la classificazione è stata eseguita trovando il piano di campagna pubblicitaria che differenzia due classi. Fare riferimento all'immagine seguente per comprendere questo concetto.
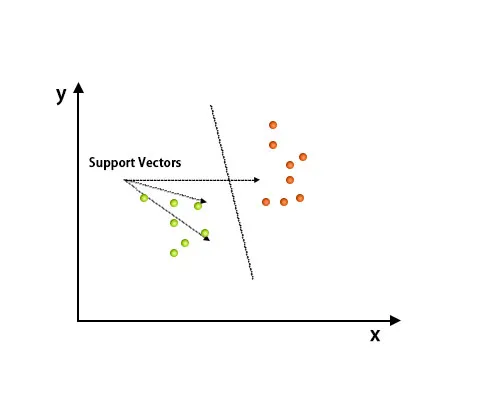
L'algoritmo Support Vector Machine viene utilizzato principalmente per risolvere i problemi di classificazione. I vettori di supporto non sono altro che le coordinate di ciascun elemento di dati. Support Vector Machine è una frontiera che differenzia due classi usando l'iperpiano.
Come funziona l'algoritmo SVM?
Nella sezione precedente, abbiamo discusso della differenziazione di due classi usando l'iperpiano. Ora vedremo come funziona effettivamente questo algoritmo SVM.
Scenario 1: identificare l'iperpiano giusto
Qui abbiamo preso tre iperpiani cioè A, B e C. Ora dobbiamo identificare l'iperpiano giusto per classificare la stella e il cerchio.
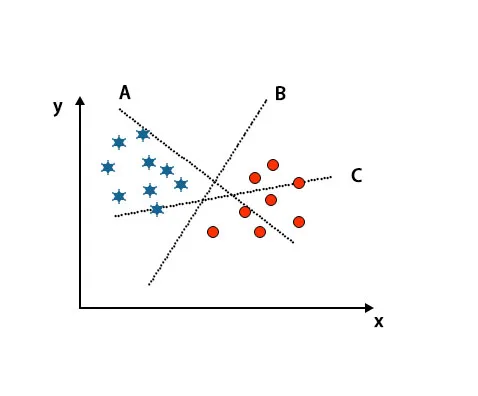
Per identificare il giusto iperpiano dovremmo conoscere la regola del pollice. Seleziona l'iperpiano che differenzia due classi. Nell'immagine sopra menzionata, l'iperpiano B differenzia molto bene due classi.
Scenario 2: identificare l'iperpiano giusto
Qui abbiamo preso tre iperpiani cioè A, B e C. Questi tre iperpiani stanno già differenziando molto bene le classi.
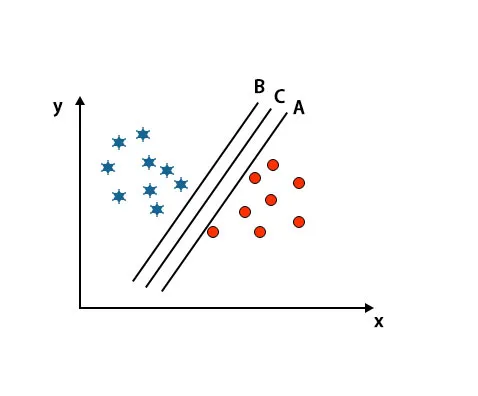
In questo scenario, per identificare l'iperpiano corretto aumentiamo la distanza tra i punti dati più vicini. Questa distanza non è altro che un margine. Fare riferimento sotto l'immagine.
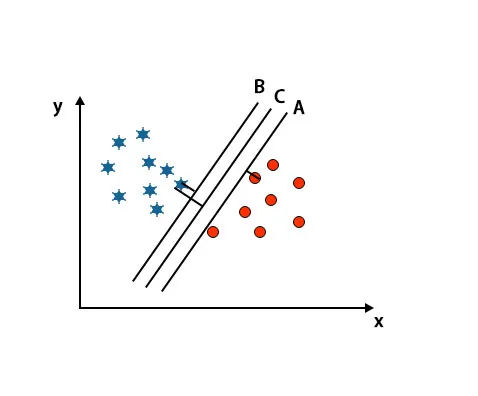
Nell'immagine sopra menzionata, il margine dell'iperpiano C è maggiore dell'iperpiano A e dell'iperpiano B. Quindi in questo scenario, C è l'iperpiano giusto. Se scegliamo l'iperpiano con un margine minimo, può portare a un'errata classificazione. Quindi abbiamo scelto l'iperpiano C con il margine massimo a causa della robustezza.
Scenario 3: identificare l'iperpiano giusto
Nota: per identificare l'iperpiano seguire le stesse regole menzionate nelle sezioni precedenti.
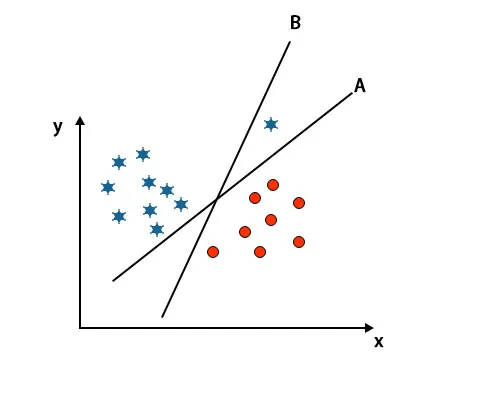
Come puoi vedere nell'immagine sopra menzionata, il margine dell'iperpiano B è più alto del margine dell'iperpiano A, ecco perché alcuni selezioneranno l'ipereo B come un diritto. Ma nell'algoritmo SVM, seleziona quell'iperpiano che classifica le classi con precisione prima di massimizzare il margine. In questo scenario, l'iperpiano A ha classificato tutto in modo accurato e c'è qualche errore con la classificazione dell'iperpiano B. Pertanto A è l'iperpiano giusto.
Scenario 4: classificare due classi
Come puoi vedere nell'immagine sotto menzionata, non siamo in grado di differenziare due classi usando una linea retta perché una stella si trova come anomala nell'altra classe del cerchio.
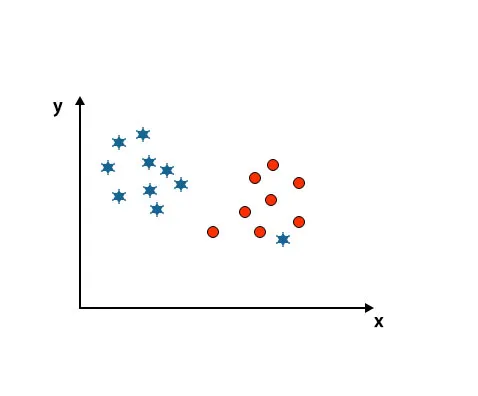
Qui, una stella è in un'altra classe. Per la classe stellare, questa stella è il valore anomalo. A causa della proprietà di robustezza dell'algoritmo SVM, troverà l'hyperplane giusto con un margine più alto ignorando un valore anomalo.
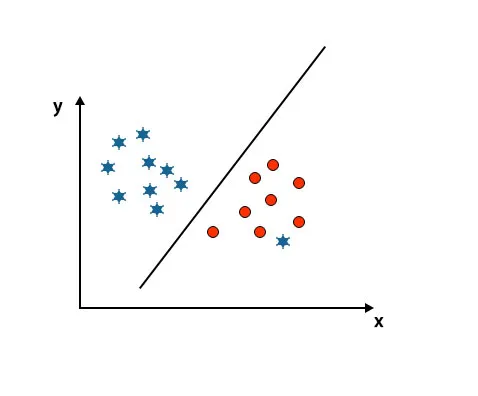
Scenario 5: iperpiano fine per differenziare le classi
Fino ad ora abbiamo osservato un iperpiano lineare. Nell'immagine sotto menzionata, non abbiamo un iperpiano lineare tra le classi.
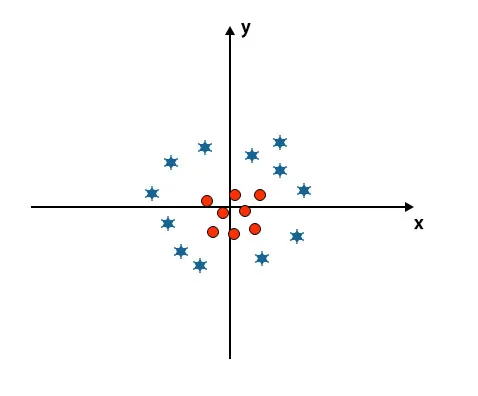
Per classificare queste classi, SVM introduce alcune funzionalità aggiuntive. In questo scenario, useremo questa nuova funzione z = x 2 + y 2.
Traccia tutti i punti dati sugli assi xe z.

Nota
- Tutti i valori sull'asse z dovrebbero essere positivi perché z è uguale alla somma di x al quadrato e y al quadrato.
- Nel grafico sopra menzionato, i cerchi rossi sono chiusi all'origine dell'asse x e dell'asse y, portando il valore di z verso il basso e la stella è esattamente l'opposto del cerchio, è lontana dall'origine dell'asse x e asse y, portando il valore di z ad alto.
Nell'algoritmo SVM, è facile classificare usando l'iperpiano lineare tra due classi. Ma qui sorge la domanda se dovremmo aggiungere questa funzionalità di SVM per identificare l'iper-piano. Quindi la risposta è no, per risolvere questo problema SVM ha una tecnica che è comunemente nota come trucco del kernel.
Il trucco del kernel è la funzione che trasforma i dati in una forma adatta. Esistono vari tipi di funzioni del kernel utilizzate nell'algoritmo SVM, ad es. Polinomiale, lineare, non lineare, funzione di base radiale, ecc. Qui usando il trucco del kernel lo spazio di input a bassa dimensione viene convertito in uno spazio di dimensione superiore.
Quando osserviamo l'iperpiano l'origine dell'asse e dell'asse y, sembra un cerchio. Fare riferimento sotto l'immagine.
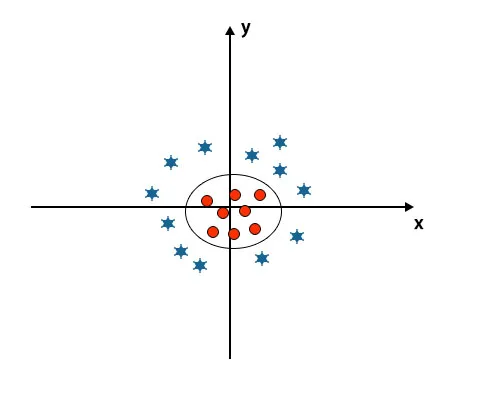
Pro di SVM Algorithm
- Anche se i dati di input sono non lineari e non separabili, le SVM generano risultati di classificazione accurati grazie alla sua robustezza.
- Nella funzione decisionale, utilizza un sottoinsieme di punti di allenamento chiamati vettori di supporto, quindi è efficiente in termini di memoria.
- È utile per risolvere qualsiasi problema complesso con un'adeguata funzione del kernel.
- In pratica, i modelli SVM sono generalizzati, con meno rischi di overfitting in SVM.
- Le SVM funzionano alla grande per la classificazione del testo e per trovare il miglior separatore lineare.
Contro di SVM Algorithm
- Ci vuole molto tempo per allenarsi quando si lavora con set di dati di grandi dimensioni.
- È difficile comprendere il modello finale e l'impatto individuale.
Conclusione
È stato guidato al Support Vector Machine Algorithm che è un algoritmo di machine learning. In questo articolo, abbiamo discusso cos'è l'algoritmo SVM, come funziona e i suoi vantaggi in dettaglio.
Articoli consigliati
Questa è stata una guida all'algoritmo SVM. Qui discutiamo del suo funzionamento con uno scenario, pro e contro di SVM Algorithm. Puoi anche consultare i seguenti articoli per saperne di più -
- Algoritmi di data mining
- Tecniche di data mining
- Che cos'è l'apprendimento automatico?
- Strumenti di apprendimento automatico
- Esempi di algoritmo C ++