

Differenza tra Big Data e Apache Hadoop
Tutto è su Internet. Internet ha molti dati. Pertanto, tutto è Big Data. Sai che 2, 5 Quintilioni di byte di dati vengono creati ogni giorno e accumulati come Big Data? Le nostre attività quotidiane come commenti, Mi piace, post, ecc. Sui social media come Facebook, LinkedIn, Twitter e Instagram si stanno aggiungendo come Big Data. Si presume che entro il 2020 verranno creati quasi 1, 7 megabyte di dati ogni secondo, per ogni persona sulla terra. Puoi immaginare e considerare quanti dati vengono generati assumendo da ogni singola persona sulla terra. Oggi siamo connessi e condividiamo le nostre vite online. Molti di noi sono connessi online. Viviamo in una casa intelligente e utilizziamo veicoli intelligenti e tutti sono collegati ai nostri telefoni intelligenti. Hai mai immaginato come questi dispositivi stiano diventando intelligenti? Mi piacerebbe darti una risposta molto semplice grazie all'analisi della grande quantità di dati, ad esempio i Big Data. Entro cinque anni ci saranno oltre 50 miliardi di dispositivi connessi intelligenti nel mondo, tutti sviluppati per raccogliere, analizzare e condividere dati per rendere più confortevole la nostra vita.
Quelle che seguono sono le presentazioni di Big Data vs Apache Hadoop
Presentazione di Term Big Data
Cosa sono i Big Data? Quale dimensione dei dati è considerata grande e verrà definita come grande data? Abbiamo molti presupposti relativi per il termine Big Data. È possibile che la quantità di dati affermi che 50 terabyte possano essere considerati come big data per Start-up, ma potrebbero non essere Big Data per aziende come Google e Facebook. È perché hanno l'infrastruttura per archiviare ed elaborare quella quantità di dati. Vorrei definire il termine Big Data come:
- Big Data è la quantità di dati che va oltre la capacità della tecnologia di archiviare, gestire ed elaborare in modo efficiente.
- I Big Data sono dati la cui scala, diversità e complessità richiedono nuove architetture, tecniche, algoritmi e analisi per gestirli ed estrarre valore e conoscenza nascosta da esso.
- I big data sono risorse informative ad alto volume e ad alta velocità e ad alta varietà che richiedono forme innovative e convenienti di elaborazione delle informazioni che consentono una migliore comprensione, processo decisionale e automazione dei processi.
- I Big Data si riferiscono a tecnologie e iniziative che coinvolgono dati troppo diversi, in rapida evoluzione o enormi per consentire alle tecnologie, competenze e infrastrutture convenzionali di affrontare in modo efficiente. Detto diversamente, il volume, la velocità o la varietà di dati è troppo grande.
3 V di Big Data
- Volume: Il volume si riferisce alla quantità / quantità con cui vengono creati i dati come Ogni ora, le transazioni dei clienti Wal-Mart forniscono all'azienda circa 2, 5 petabyte di dati.
- Velocità: Velocità indica la velocità con cui i dati si muovono come gli utenti di Facebook inviano in media 31, 25 milioni di messaggi e visualizzano 2, 77 milioni di video ogni minuto ogni singolo giorno su Internet.
- Varietà: varietà si riferisce a diversi formati di dati creati come dati strutturati, semi-strutturati e non strutturati. Come l'invio di e-mail con l'allegato su Gmail sono dati non strutturati mentre la pubblicazione di commenti con alcuni collegamenti esterni è anche definita come dati non strutturati. La condivisione di immagini, clip audio e video è una forma non strutturata di dati.
Archiviare ed elaborare questo enorme volume, velocità e varietà di dati è un grosso problema. Dobbiamo pensare ad altre tecnologie diverse da RDBMS per i Big Data. È perché RDBMS è in grado di archiviare ed elaborare solo dati strutturati. Quindi qui Apache Hadoop viene in soccorso.
Presentazione di Termine Apache Hadoop
Apache Hadoop è un framework software open source per l'archiviazione di dati e l'esecuzione di applicazioni su cluster di hardware di largo consumo. Apache Hadoop è un framework software che consente l'elaborazione distribuita di grandi set di dati tra cluster di computer utilizzando semplici modelli di programmazione. È progettato per scalare da singoli server a migliaia di macchine, ognuna delle quali offre elaborazione e archiviazione locali. Apache Hadoop è un framework per l'archiviazione e l'elaborazione dei Big Data. Apache Hadoop è in grado di archiviare ed elaborare tutti i formati di dati come dati strutturati, semi-strutturati e non strutturati. Apache Hadoop è un hardware open source e di largo consumo che ha rivoluzionato l'industria IT. È facilmente accessibile a tutti i livelli di società. Non devono investire di più per installare il cluster Hadoop e su diverse infrastrutture. Vediamo quindi l'utile differenza tra Big Data e Apache Hadoop in dettaglio in questo post.
Quadro Apache Hadoop
Il framework Apache Hadoop è diviso in due parti:
- Hadoop Distributed File System (HDFS): questo livello è responsabile della memorizzazione dei dati.
- MapReduce: questo livello è responsabile dell'elaborazione dei dati su Hadoop Cluster.
Hadoop Framework è diviso in architettura master e slave. Hadoop Distributed File System (HDFS) livello Nome Nodo è componente principale mentre Data Node è componente Slave mentre nel livello MapReduce Job Tracker è componente principale mentre il tracker attività è componente slave. Di seguito è riportato il diagramma per il framework Apache Hadoop.
Perché è importante Apache Hadoop?
- Capacità di archiviare ed elaborare enormi quantità di qualsiasi tipo di dati, rapidamente
- Potenza di calcolo: il modello di calcolo distribuito di Hadoop elabora rapidamente i big data. Maggiore è il numero di nodi di elaborazione utilizzati, maggiore sarà la potenza di elaborazione.
- Tolleranza ai guasti: l' elaborazione dei dati e delle applicazioni è protetta da guasti hardware. Se un nodo si arresta, i lavori vengono automaticamente reindirizzati ad altri nodi per assicurarsi che il calcolo distribuito non fallisca. Copie multiple di tutti i dati vengono archiviate automaticamente.
- Flessibilità: è possibile archiviare tutti i dati desiderati e decidere come utilizzarli in seguito. Ciò include dati non strutturati come testo, immagini e video.
- Basso costo: il framework open source è gratuito e utilizza hardware di base per archiviare grandi quantità di dati.
- Scalabilità: puoi facilmente far crescere il tuo sistema per gestire più dati semplicemente aggiungendo nodi. È richiesta poca amministrazione
Confronto diretto tra Big Data e Apache Hadoop (infografica)
Di seguito è riportato il Top 4 confronto tra Big Data vs Apache Hadoop
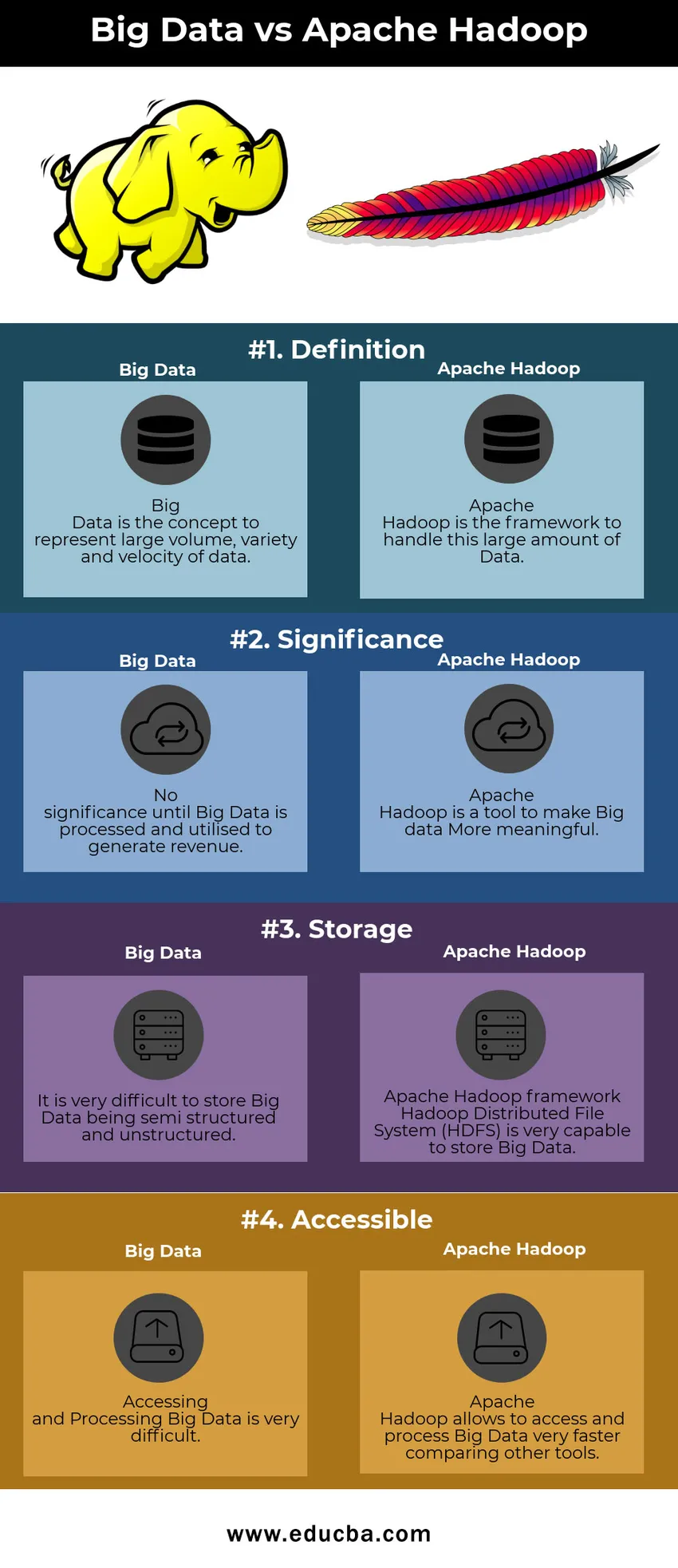
Tabella di confronto Big Data vs Apache Hadoop
Sto discutendo di importanti artefatti e distinguendo tra Big Data e Apache Hadoop
| Big Data | Apache Hadoop | |
| Definizione | Big Data è il concetto che rappresenta il grande volume, la varietà e la velocità dei dati | Apache Hadoop è il framework per gestire questa grande quantità di dati |
| Significato | Nessun significato fino a quando i Big Data non vengono elaborati e utilizzati per generare entrate | Apache Hadoop è uno strumento per rendere i Big Data più significativi |
| Conservazione | È molto difficile archiviare i Big Data essendo semi-strutturati e non strutturati | Framework Hadoop di Apache Hadoop Distributed File System (HDFS) è in grado di archiviare Big Data |
| Accessibile | L'accesso e l'elaborazione dei Big Data è molto difficile | Apache Hadoop consente di accedere ed elaborare i Big Data molto più rapidamente confrontando altri strumenti |
Conclusione - Big Data vs Apache Hadoop
Non puoi confrontare Big Data e Apache Hadoop. È perché i Big Data sono un problema mentre Apache Hadoop è la soluzione. Poiché la quantità di dati sta aumentando esponenzialmente in tutti i settori, è quindi molto difficile archiviare ed elaborare i dati da un singolo sistema. Quindi, per elaborare questa grande quantità di dati, abbiamo bisogno di elaborazione e archiviazione distribuite dei dati. Pertanto Apache Hadoop fornisce la soluzione per l'archiviazione e l'elaborazione di una grande quantità di dati. Infine, concluderò che i Big Data sono una grande quantità di dati complessi, mentre Apache Hadoop è un meccanismo per archiviare ed elaborare i Big Data in modo molto efficiente e senza problemi.
Articolo raccomandato
Questa è stata una guida per Big Data vs Apache Hadoop, il loro significato, il confronto testa a testa, le differenze chiave, la tabella di confronto e le conclusioni. questo articolo contiene tutte le utili differenze tra Big Data e Apache Hadoop. Puoi anche consultare i seguenti articoli per saperne di più -
- Big Data vs Data Science: come sono diversi?
- Le 5 principali tendenze dei big data che le aziende dovranno padroneggiare
- Hadoop vs Apache Spark - Cose interessanti che devi sapere
- Apache Hadoop vs Apache Spark | I 10 migliori confronti che devi sapere!