

Introduzione alla mappa Join in Hive
Map join è una funzionalità utilizzata nelle query Hive per aumentare la sua efficienza in termini di velocità. Unire è una condizione utilizzata per combinare i dati da 2 tabelle. Pertanto, quando eseguiamo un join normale, il lavoro viene inviato a un'attività Riduci mappa che suddivide l'attività principale in 2 fasi: "Fase mappa" e "Fase riduzione". Lo stage Mappa interpreta i dati di input e restituisce l'output allo stage di riduzione sotto forma di coppie chiave-valore. Questo passaggio successivo passa attraverso la fase casuale in cui vengono ordinati e combinati. Il riduttore accetta questo valore ordinato e completa il processo di join.
Una tabella può essere caricata completamente nella memoria all'interno di un mapper e senza dover utilizzare il processo Mappa / Riduttore. Legge i dati dalla tabella più piccola e li memorizza in una tabella hash in memoria e quindi li serializza in un file di memoria hash riducendo così notevolmente il tempo. È anche noto come Map Side Join in Hive. Fondamentalmente, comporta l'esecuzione di join tra 2 tabelle utilizzando solo la fase Mappa e saltando la fase Riduci. È possibile osservare una riduzione del tempo nel calcolo delle query se utilizzano regolarmente join di una tabella di piccole dimensioni.
Sintassi per Map Join in Hive
Se vogliamo eseguire una query di join utilizzando map-join, dobbiamo specificare una parola chiave "/ * + MAPJOIN (b) * /" nell'istruzione come di seguito:
>SELECT /*+ MAPJOIN(c) */ * FROM tablename1 t1 JOIN tablename2 t2 ON (t1.emp_id = t2.emp_id);
Per questo esempio, dobbiamo creare 2 tabelle con nomi tablename1 e tablename2 con 2 colonne: emp_id e emp_name. Uno dovrebbe essere un file più grande e uno dovrebbe essere più piccolo.
Prima di eseguire la query, dobbiamo impostare la proprietà sottostante su true:
hive.auto.convert.join=true
La query di join per join mappa è scritta come sopra e il risultato che otteniamo è:
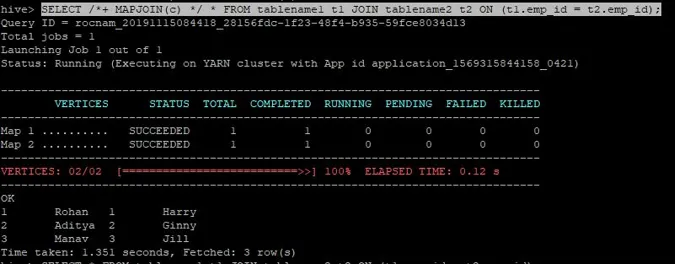
La query è stata completata in 1.351 secondi.
Esempi di mappe Unisciti a Hive
Ecco i seguenti esempi menzionati di seguito
1. Mappa esempio di join
Per questo esempio, creiamo 2 tabelle denominate table1 e table2 con rispettivamente 100 e 200 record. È possibile fare riferimento al comando e agli screenshot seguenti per eseguire lo stesso:
>CREATE TABLE IF NOT EXISTS table1 ( emp_id int, emp_name String, email_id String, gender String, ip_address String) row format delimited fields terminated BY ', ' tblproperties("skip.header.line.count"="1");
>CREATE TABLE IF NOT EXISTS table2 ( emp_id int, emp_name String) row format delimited fields terminated BY ', ' tblproperties("skip.header.line.count"="1");

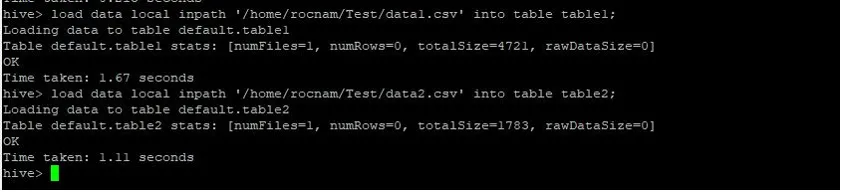
Ora cariciamo i record in entrambe le tabelle usando i comandi seguenti:
>load data local inpath '/relativePath/data1.csv' into table table1;
>load data local inpath '/relativePath/data2.csv' into table table2;
Eseguiamo una normale query di join della mappa sui loro ID come mostrato di seguito e verificiamo il tempo impiegato per lo stesso:
>SELECT /*+ MAPJOIN(table2) */ table1.emp_name, table1.emp_id, table2.emp_id FROM table1 JOIN table2 ON table1.emp_name = table2.emp_name;
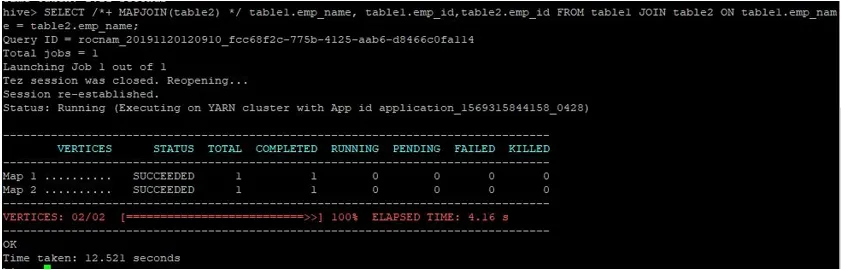
Come possiamo vedere, una normale query di join della mappa ha richiesto 12.521 secondi.
2. Esempio di join Bucket-Map
Usiamo ora Bucket-map join per eseguire lo stesso. Ci sono alcuni vincoli che devono essere seguiti per il bucket:
- I bucket possono essere uniti tra loro solo se i bucket totali di una tabella sono multipli del numero di bucket nell'altra tabella.
- Deve disporre di tabelle con bucket per eseguire il bucket. Quindi creiamo lo stesso.
Di seguito sono riportati i comandi utilizzati per creare tabelle con bucket table1 e table2:
>>CREATE TABLE IF NOT EXISTS table1_buk (emp_id int, emp_name String, email_id String, gender String, ip_address String) clustered by(emp_name) into 4 buckets row format delimited fields terminated BY ', ';
>CREATE TABLE IF NOT EXISTS table2_buk ( emp_id int, emp_name String) clustered by(emp_name) into 8 buckets row format delimited fields terminated BY ', ' ;

Inseriremo gli stessi record dalla tabella 1 anche in queste tabelle raggruppate:
>insert into table1_buk select * from table1;
>insert into table2_buk select * from table2;
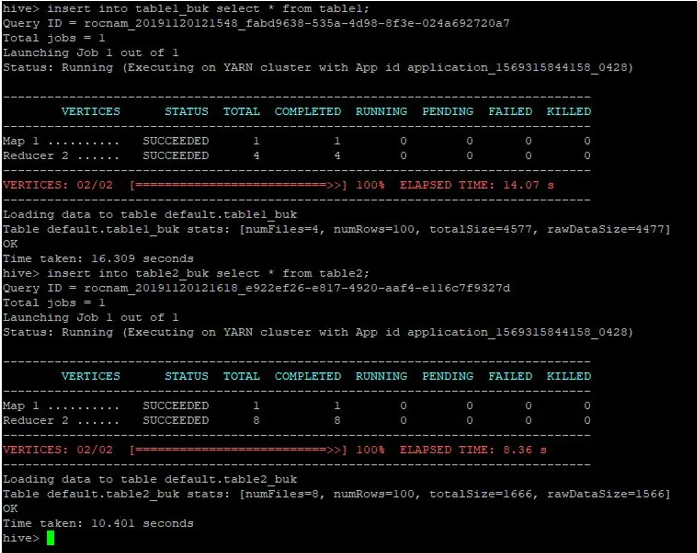
Ora che abbiamo i nostri 2 tavoli con bucket, eseguiamo un join bucket-map su questi. La prima tabella ha 4 bucket mentre la seconda tabella ha 8 bucket creati sulla stessa colonna.
Affinché la query di join bucket-map funzioni, dovremmo impostare la proprietà sottostante su true nell'alveare:
set hive.optimize.bucketmapjoin = true
>SELECT /*+ MAPJOIN(table2_buk) */ table1_buk.emp_name, table1_buk.emp_id, table2_buk.emp_id FROM table1_buk JOIN table2_buk ON table1_buk.emp_name = table2_buk.emp_name ;
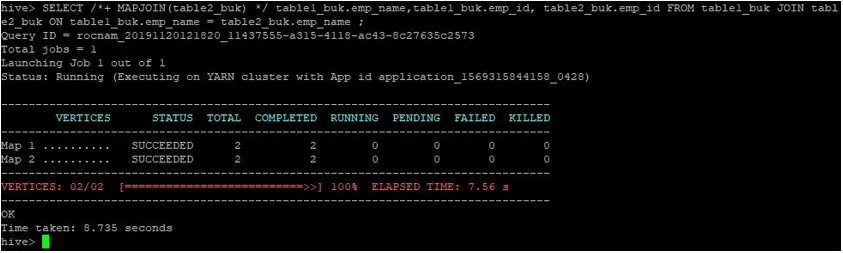
Come possiamo vedere, la query è stata completata in 8.735 secondi, il che è più veloce di un normale join della mappa.
3. Ordina unisci mappa benna Unisci esempio (SMB)
SMB può essere eseguito su tabelle con bucket con lo stesso numero di bucket e se le tabelle devono essere ordinate e raggruppate su colonne di join. Il livello del mapper si unisce a questi bucket di conseguenza.
Come nel join Bucket-map, ci sono 4 bucket per table1 e 8 bucket per table2. Per questo esempio, creeremo un'altra tabella con 4 bucket.
Per eseguire la query SMB, dobbiamo impostare le seguenti proprietà hive come mostrato di seguito:
Hive.input.format = org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
hive.optimize.bucketmapjoin = true;
hive.optimize.bucketmapjoin.sortedmerge = true;
Per eseguire il join SMB è necessario ordinare i dati secondo le colonne del join. Quindi, sovrascriviamo i dati nella tabella1, come indicato di seguito:
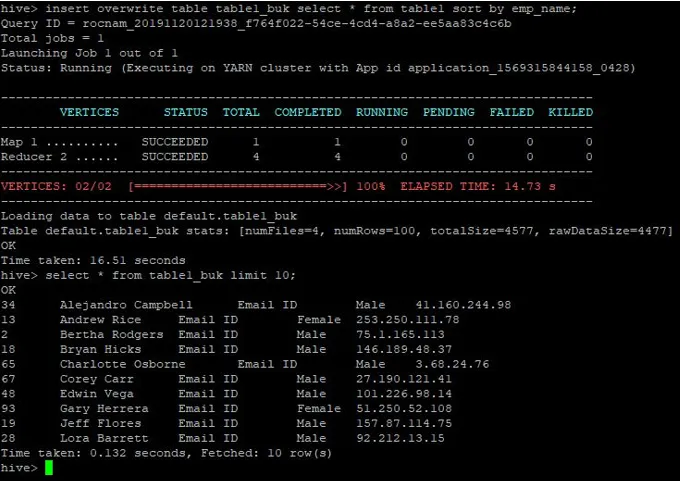
>insert overwrite table table1_buk select * from table1 sort by emp_name;
I dati sono ordinati ora che possono essere visualizzati nello screenshot qui sotto:
Dovremo anche sovrascrivere i dati nella tabella a secchiello 2 come di seguito:
>insert overwrite table table2_buk select * from table2 sort by emp_name;

Eseguiamo il join per le 2 tabelle sopra come segue:
>SELECT /*+ MAPJOIN(table2_buk) */ table1_buk.emp_name, table1_buk.emp_id, table2_buk.emp_id FROM table1_buk JOIN table2_buk ON table1_buk.emp_name = table2_buk.emp_name ;
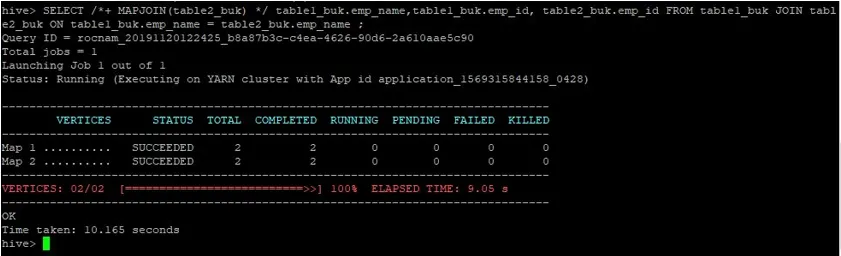
Possiamo vedere che la query ha richiesto 10.165 secondi, il che è di nuovo migliore di un normale join della mappa.
Creiamo ora un'altra tabella per table2 con 4 bucket e gli stessi dati ordinati con emp_name.
>CREATE TABLE IF NOT EXISTS table2_buk1 (emp_id int, emp_name String) clustered by(emp_name) into 4 buckets row format delimited fields terminated BY ', ' ;
>insert overwrite table table2_buk1 select * from table2 sort by emp_name;
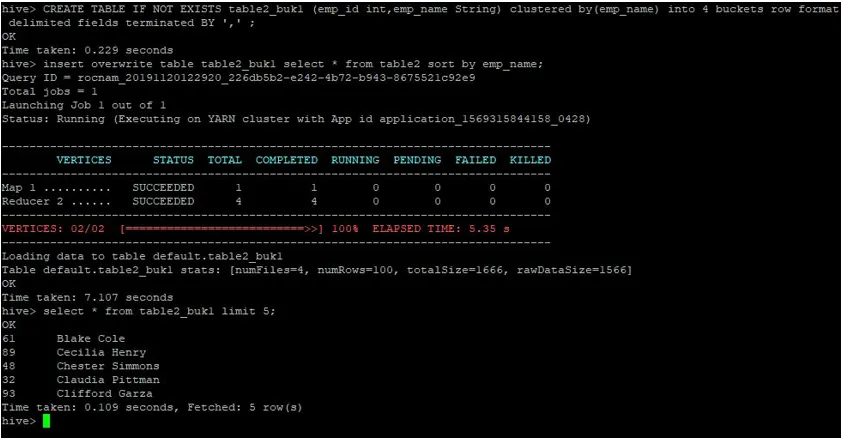
Considerando che ora abbiamo entrambe le tabelle con 4 bucket, eseguiamo nuovamente una query di join.
>SELECT /*+ MAPJOIN(table2_buk1) */table1_buk.emp_name, table1_buk.emp_id, table2_buk1.emp_id FROM table1_buk JOIN table2_buk1 ON table1_buk.emp_name = table2_buk1.emp_name ;
La query ha richiesto nuovamente 8.851 secondi più velocemente della normale query di join della mappa.
vantaggi
- L'unione delle mappe riduce il tempo impiegato per i processi di ordinamento e fusione che si svolgono nello shuffle e riduce le fasi riducendo al minimo anche i costi.
- Aumenta l'efficienza delle prestazioni dell'attività.
limitazioni
- La stessa tabella / alias non può essere utilizzata per unire colonne diverse nella stessa query.
- La query di join della mappa non può convertire i join esterni completi nei join laterali della mappa.
- Il join della mappa può essere eseguito solo quando una delle tabelle è abbastanza piccola da poter essere adattata alla memoria. Quindi non può essere eseguito dove i dati della tabella sono enormi.
- È possibile eseguire un join sinistro su un join mappa solo quando la dimensione della tabella destra è ridotta.
- È possibile eseguire un join destro per un join della mappa solo quando la dimensione della tabella sinistra è ridotta.
Conclusione
Abbiamo cercato di includere i migliori punti possibili di Map Join in Hive. Come abbiamo visto sopra, l'unione lato mappa funziona meglio quando una tabella ha meno dati in modo da completare rapidamente il lavoro. Il tempo impiegato per le query mostrate qui dipende dalla dimensione del set di dati, quindi il tempo mostrato qui è solo per l'analisi. Il join della mappa può essere facilmente implementato in applicazioni in tempo reale poiché disponiamo di enormi dati che aiutano a ridurre il traffico I / O di rete.
Articoli consigliati
Questa è una guida per Map Join in Hive. Qui discutiamo gli esempi di Map Join in Hive insieme ai vantaggi e ai limiti. Puoi anche leggere il seguente articolo per saperne di più -
- Si unisce a Hive
- Hive Funzioni integrate
- Che cos'è un alveare?
- Comandi alveare