
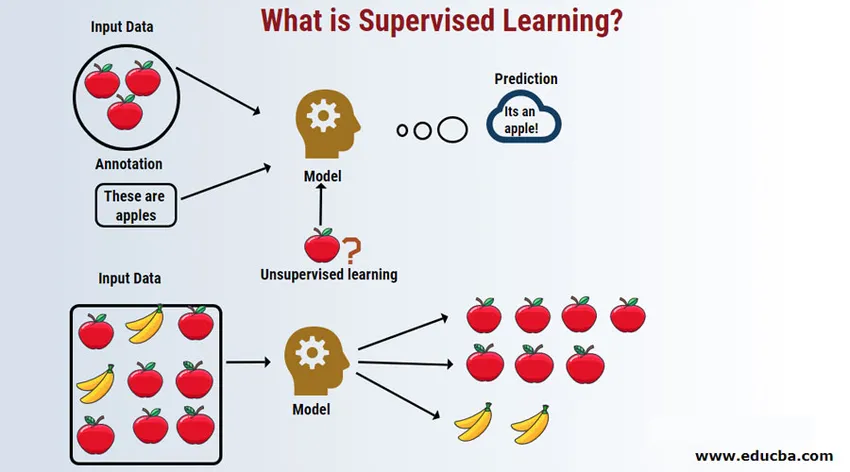
Introduzione all'apprendimento supervisionato
L'apprendimento supervisionato è un'area di machine learning in cui lavoriamo sulla previsione dei valori utilizzando set di dati etichettati. I set di dati di input etichettati vengono chiamati variabili indipendenti mentre i risultati previsti vengono chiamati variabili dipendenti perché dipendono dalla variabile indipendente per i loro risultati. Ad esempio, tutti abbiamo una cartella spam nel nostro account di posta elettronica (ad esempio Gmail) che rileva automaticamente la maggior parte dei messaggi di posta elettronica spam / fraudolenti con un'accuratezza superiore al 95%. Funziona sulla base di un modello di apprendimento supervisionato in cui abbiamo un set di formazione di dati etichettati, che in questo caso è etichettato come spam e-mail contrassegnato dagli utenti. Questi set di formazione vengono utilizzati per l'apprendimento che in seguito verranno utilizzati per la categorizzazione di nuove e-mail come spam se rientra nella categoria.
Lavorare sull'apprendimento automatico supervisionato
Cerchiamo di capire l'apprendimento automatico supervisionato con l'aiuto di un esempio. Diciamo che abbiamo un cesto di frutta che viene riempito con diverse specie di frutti. Il nostro compito è di classificare i frutti in base alla loro categoria.
Nel nostro caso, abbiamo preso in considerazione quattro tipi di frutta e quelli sono mela, banana, uva e arance.
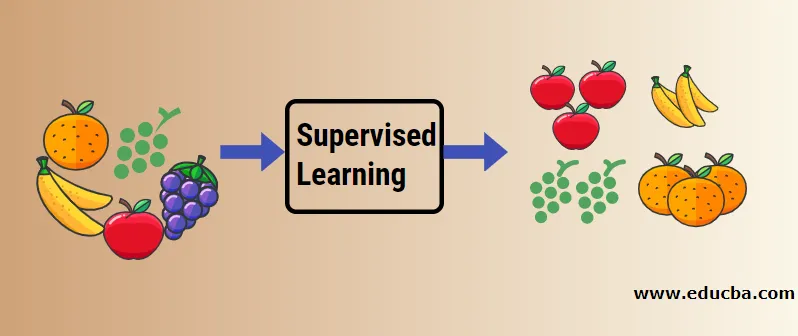
Ora proveremo a menzionare alcune delle caratteristiche uniche di questi frutti che li rendono unici.
|
S No. | Taglia | Colore | Forma |
Nome di battesimo |
|
1 | Piccolo | verde | Rotondo a ovale, forma di mazzo cilindrico |
Uva |
|
2 | Grande | Rosso | Forma arrotondata con una depressione nella parte superiore |
Mela |
|
3 | Grande | Giallo | Cilindro curvo lungo |
Banana |
| 4 | Grande | arancia | Forma arrotondata |
arancia |
Ora diciamo che hai raccolto un frutto dal cesto di frutta, ne hai guardato le caratteristiche, ad esempio la sua forma, dimensione e colore, e quindi deduci che il colore di questo frutto è rosso, la dimensione se grande, la forma è arrotondata con depressione nella parte superiore, quindi è una mela.
- Allo stesso modo, fai lo stesso anche per tutti gli altri frutti rimasti.
- La colonna più a destra ("Fruit Name") è nota come variabile di risposta.
- È così che formuliamo un modello di apprendimento supervisionato, ora sarà abbastanza facile per chiunque sia nuovo (diciamo un robot o un alieno) con determinate proprietà per raggruppare facilmente lo stesso tipo di frutti.
Tipi di algoritmo di apprendimento automatico supervisionato
Vediamo diversi tipi di algoritmi di apprendimento automatico:
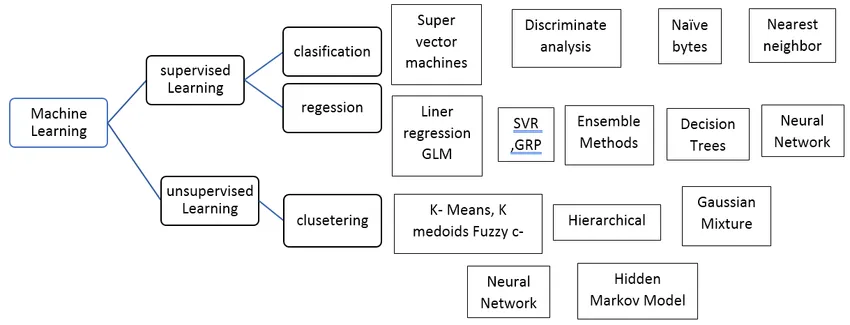
Regressione:
La regressione viene utilizzata per prevedere l'output di un singolo valore utilizzando il set di dati di training. Il valore di output viene sempre chiamato come variabile dipendente mentre gli input sono noti come variabile indipendente. Abbiamo diversi tipi di regressione nell'apprendimento supervisionato, ad esempio,
- Regressione lineare - Qui abbiamo solo una variabile indipendente che viene utilizzata per prevedere l'output, ovvero la variabile dipendente.
- Regressione multipla - Qui abbiamo più di una variabile indipendente che viene utilizzata per prevedere l'output, ovvero la variabile dipendente.
- Regressione polinomiale : qui il grafico tra le variabili dipendenti e indipendenti segue una funzione polinomiale. Ad esempio, all'inizio, la memoria aumenta con l'età, quindi raggiunge una soglia a una certa età e quindi inizia a diminuire con l'invecchiamento.
Classificazione:
La classificazione degli algoritmi di apprendimento supervisionato viene utilizzata per raggruppare oggetti simili in classi uniche.
- Classificazione binaria: se l'algoritmo sta cercando di raggruppare 2 gruppi distinti di classi, viene chiamata classificazione binaria.
- Classificazione multiclasse: se l'algoritmo sta cercando di raggruppare gli oggetti in più di 2 gruppi, si chiama classificazione multiclasse.
- Forza - Gli algoritmi di classificazione di solito funzionano molto bene.
- Svantaggi: inclini a sovralimentazione e potrebbero non essere vincolati. Ad esempio - Classificatore spam e - mail
- Regressione / classificazione logistica: quando la variabile Y è un codice binario categorico (ovvero 0 o 1), utilizziamo la regressione logistica per la previsione. Ad esempio : prevedere se una determinata transazione con carta di credito è una frode o meno.
- Classificatori Naïve Bayes - Il classificatore Naïve Bayes si basa sul teorema bayesiano. Questo algoritmo è generalmente più adatto quando la dimensionalità degli input è elevata. È costituito da grafici aciclici che presentano un nodo padre e molti nodi figlio. I nodi figlio sono indipendenti l'uno dall'altro.
- Alberi decisionali - Un albero decisionale è una struttura ad albero che consiste in un nodo interno (test su attributo), ramo che indica il risultato del test e i nodi foglia che rappresentano la distribuzione delle classi. Il nodo principale è il nodo più in alto. È una tecnica molto usata per la classificazione.
- Support Vector Machine - Una macchina vector support è o un SVM fa il lavoro di classificazione trovando l'hyperplane che dovrebbe massimizzare il margine tra 2 classi. Queste macchine SVM sono collegate alle funzioni del kernel. I campi in cui gli SVM sono ampiamente utilizzati sono biometria, riconoscimento di schemi, ecc.
vantaggi
Di seguito sono riportati alcuni dei vantaggi dei modelli di apprendimento automatico supervisionato:
- Le prestazioni dei modelli possono essere ottimizzate dalle esperienze dell'utente.
- L'apprendimento supervisionato produce risultati utilizzando l'esperienza precedente e consente anche di raccogliere dati.
- Gli algoritmi di apprendimento automatico supervisionato possono essere utilizzati per implementare una serie di problemi del mondo reale.
svantaggi
Gli svantaggi dell'apprendimento supervisionato sono i seguenti:
- Lo sforzo di formare modelli di apprendimento automatico supervisionato può richiedere molto tempo se il set di dati è più grande.
- La classificazione dei big data a volte pone una sfida più grande.
- Uno potrebbe dover affrontare i problemi di overfitting.
- Abbiamo bisogno di molti buoni esempi se vogliamo che il modello funzioni bene mentre stiamo addestrando il classificatore.
Buone pratiche durante la costruzione di modelli di apprendimento
È una buona pratica durante la costruzione di modelli di macchine per l'apprendimento supervisionato: -
- Prima di creare un buon modello di apprendimento automatico, è necessario eseguire il processo di preelaborazione dei dati.
- Bisogna decidere l'algoritmo che dovrebbe essere più adatto per un determinato problema.
- Dobbiamo decidere quale tipo di dati verrà utilizzato per il set di formazione.
- Deve decidere sulla struttura dell'algoritmo e della funzione.
Conclusione
Nel nostro articolo, abbiamo appreso ciò che è l'apprendimento supervisionato e abbiamo visto che qui formiamo il modello utilizzando dati etichettati. Quindi abbiamo iniziato a lavorare sui modelli e sui loro diversi tipi. Abbiamo finalmente visto i vantaggi e gli svantaggi di questi algoritmi di apprendimento automatico supervisionati.
Articoli consigliati
Questa è una guida a ciò che è l'apprendimento supervisionato ?. Qui discutiamo i concetti, come funziona, i tipi, i vantaggi e gli svantaggi dell'apprendimento supervisionato. Puoi anche consultare i nostri altri articoli suggeriti per saperne di più -
- Che cos'è l'apprendimento profondo
- Apprendimento supervisionato vs apprendimento profondo
- Che cos'è la sincronizzazione in Java?
- Che cos'è l'hosting Web?
- Modi per creare un albero decisionale con vantaggi
- Regressione polinomiale | Usi e caratteristiche