
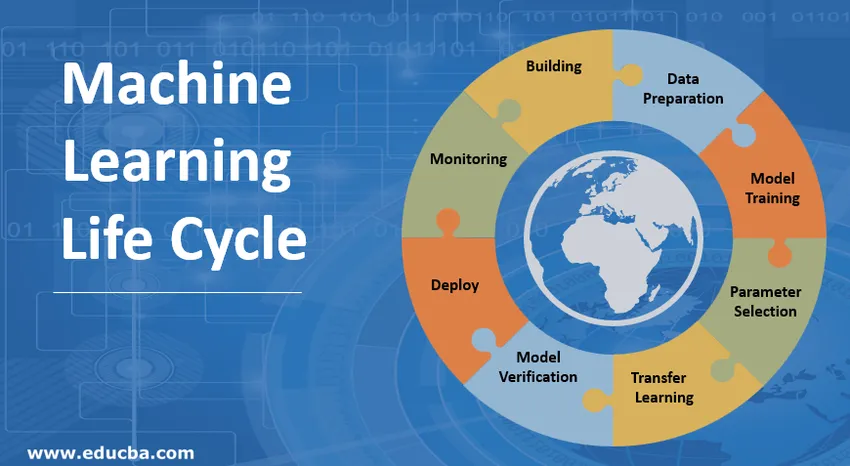
Introduzione al ciclo di vita di Machine Learning (ML)
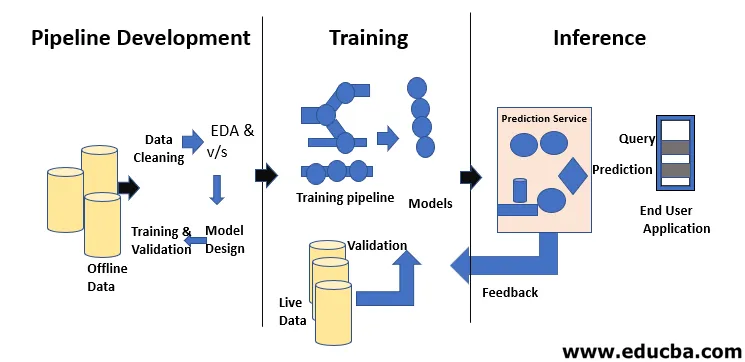
Il ciclo di vita di Machine Learning riguarda l'acquisizione di conoscenze attraverso i dati. Il ciclo di vita dell'apprendimento automatico descrive un processo trifase utilizzato da data scientist e data engineer per sviluppare, formare e servire modelli. Lo sviluppo, la formazione e l'assistenza dei modelli di apprendimento automatico sono il risultato di un processo chiamato ciclo di vita dell'apprendimento automatico. È un sistema che utilizza i dati come input, avendo la capacità di apprendere e migliorare usando gli algoritmi senza essere programmato per farlo. Il ciclo di vita dell'apprendimento automatico prevede tre fasi, come mostrato nella figura seguente: sviluppo della pipeline, formazione e inferenza.
Il primo passo nel ciclo di vita dell'apprendimento automatico consiste nella trasformazione di dati grezzi in un set di dati pulito, che viene spesso condiviso e riutilizzato. Se un analista o uno scienziato di dati che riscontrano problemi nei dati ricevuti, devono accedere ai dati originali e agli script di trasformazione. Esistono diversi motivi per cui potremmo voler tornare alle versioni precedenti dei nostri modelli e dati. Ad esempio, trovare la migliore versione precedente potrebbe richiedere la ricerca in molte versioni alternative poiché i modelli si degradano inevitabilmente nella loro potenza predittiva. Ci sono molte ragioni per questo degrado, come uno spostamento nella distribuzione dei dati che può comportare un rapido declino del potere predittivo come compensazione degli errori. La diagnosi di questo declino può richiedere il confronto dei dati di allenamento con i dati in tempo reale, la riqualificazione del modello, la rivisitazione delle precedenti decisioni di progettazione o persino la riprogettazione del modello.
Imparare dagli errori
Lo sviluppo di modelli richiede set di dati di formazione e test separati. L'uso eccessivo dei dati dei test durante l'allenamento può portare a scarse generalizzazioni e prestazioni, in quanto possono comportare un eccesso di adattamento. Il contesto gioca qui un ruolo vitale, quindi è necessario capire quali dati sono stati usati per addestrare i modelli previsti e con quali configurazioni. Il ciclo di vita dell'apprendimento automatico è basato sui dati perché il modello e l'output della formazione sono collegati ai dati su cui è stato formato. Una panoramica di una pipeline di apprendimento automatico end-to-end con un punto di vista dei dati è mostrata nella figura seguente:
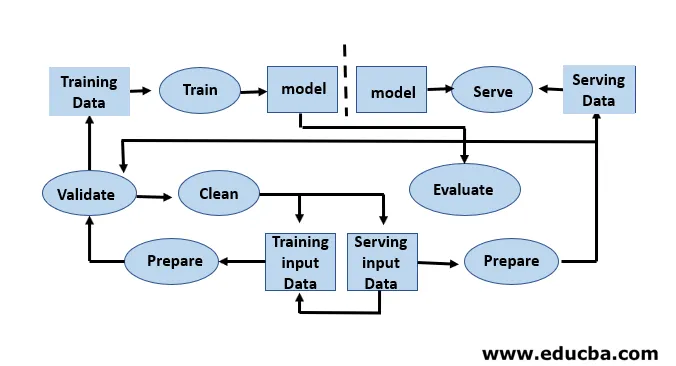
Passaggi coinvolti nel ciclo di vita dell'apprendimento automatico
Lo sviluppatore di Machine Learning esegue costantemente la sperimentazione di nuovi set di dati, modelli, librerie software, parametri di ottimizzazione al fine di ottimizzare e migliorare l'accuratezza del modello. Poiché le prestazioni del modello dipendono completamente dai dati di input e dal processo di formazione.
1. Creazione del modello di apprendimento automatico
Questo passaggio decide il tipo di modello in base all'applicazione. Scopre anche che l'applicazione del modello nella fase di apprendimento del modello in modo che possano essere progettati correttamente in base alle esigenze di un'applicazione prevista. Sono disponibili numerosi modelli di apprendimento automatico, come il modello Supervisionato, il Modello non supervisionato, i modelli di classificazione, i modelli di regressione, i modelli di clustering e i modelli di apprendimento del rinforzo. Uno sguardo ravvicinato è rappresentato nella figura di seguito:
2. Preparazione dei dati
Una varietà di dati può essere utilizzata come input per scopi di apprendimento automatico. Questi dati possono provenire da una serie di fonti, come un'azienda, aziende farmaceutiche, dispositivi IoT, imprese, banche, ospedali, ecc. Grandi quantità di dati vengono forniti nella fase di apprendimento della macchina poiché, man mano che il numero di dati aumenta, si allinea verso dando i risultati desiderati. Questi dati di output possono essere utilizzati per l'analisi o inseriti come input in altre applicazioni o sistemi di apprendimento automatico per i quali fungeranno da seed.
3. Formazione modello
Questa fase riguarda la creazione di un modello dai dati forniti. In questa fase, una parte dei dati di addestramento viene utilizzata per trovare parametri del modello come i coefficienti di un polinomio o i pesi dell'apprendimento automatico che aiutano a ridurre al minimo l'errore per il set di dati specificato. I dati rimanenti vengono quindi utilizzati per testare il modello. Questi due passaggi vengono generalmente ripetuti più volte al fine di migliorare le prestazioni del modello.
4. Selezione dei parametri
Implica la selezione dei parametri associati all'allenamento che sono anche chiamati iperparametri. Questi parametri controllano l'efficacia del processo di allenamento e quindi, in definitiva, le prestazioni del modello dipendono da questo. Sono molto cruciali per la produzione di successo del modello di apprendimento automatico.
5. Apprendimento di trasferimento
Dal momento che ci sono molti vantaggi nel riutilizzo dei modelli di apprendimento automatico in vari domini. Pertanto, nonostante il fatto che un modello non possa essere trasferito direttamente tra domini diversi, quindi viene utilizzato per fornire un materiale di partenza per iniziare l'addestramento di un modello della fase successiva. Quindi riduce significativamente i tempi di allenamento.
6. Verifica del modello
L'input di questa fase è il modello addestrato prodotto dalla fase di apprendimento del modello e l'output è un modello verificato che fornisce informazioni sufficienti per consentire agli utenti di determinare se il modello è adatto per l'applicazione prevista. Pertanto, questa fase del ciclo di vita dell'apprendimento automatico riguarda il fatto che un modello funziona correttamente se trattato con input invisibili.
7. Distribuire il modello di apprendimento automatico
In questa fase del ciclo di vita dell'apprendimento automatico, chiediamo di integrare i modelli di apprendimento automatico nei processi e nelle applicazioni. L'obiettivo finale di questa fase è la corretta funzionalità del modello dopo la distribuzione. I modelli dovrebbero essere distribuiti in modo tale da poter essere utilizzati per deduzione e dovrebbero essere aggiornati regolarmente.
8. Monitoraggio
Implica l'inclusione di misure di sicurezza per garantire il corretto funzionamento del modello durante la sua durata. A tal fine sono necessari una gestione e un aggiornamento adeguati.
Vantaggio del ciclo di vita dell'apprendimento automatico
L'apprendimento automatico offre i vantaggi di potenza, velocità, efficienza e intelligenza attraverso l'apprendimento senza programmarli esplicitamente in un'applicazione. Offre opportunità per migliorare prestazioni, produttività e robustezza.
Conclusione - Ciclo di vita dell'apprendimento automatico
I sistemi di apprendimento automatico stanno diventando sempre più importanti giorno dopo giorno poiché la quantità di dati coinvolti in varie applicazioni sta aumentando rapidamente. La tecnologia di apprendimento automatico è il cuore di dispositivi intelligenti, elettrodomestici e servizi online. Il successo dell'apprendimento automatico può essere ulteriormente esteso a sistemi critici per la sicurezza, gestione dei dati, elaborazione ad alte prestazioni, che ha un grande potenziale per i domini applicativi.
Articoli consigliati
Questa è una guida al ciclo di vita di Machine Learning. Qui discutiamo l'introduzione, l'apprendimento dagli errori, i passaggi coinvolti nel ciclo di vita dell'apprendimento automatico e i vantaggi. Puoi anche consultare i nostri altri articoli suggeriti per saperne di più–
- Aziende di intelligenza artificiale
- QlikView Set Analysis
- Ecosistema IoT
- Modellazione dei dati Cassandra