

Introduzione al data mining
Questo è un metodo di data mining utilizzato per posizionare elementi di dati nei loro gruppi simili. Il cluster è la procedura di divisione degli oggetti dati in sottoclassi. La qualità del clustering dipende dal metodo che abbiamo usato. Il clustering è anche chiamato segmentazione dei dati poiché i grandi gruppi di dati sono divisi per la loro somiglianza.
Che cos'è il clustering nel data mining?
Il clustering è il raggruppamento di oggetti specifici in base alle loro caratteristiche e alle loro somiglianze. Per quanto riguarda il data mining, questa metodologia divide i dati più adatti all'analisi desiderata utilizzando uno speciale algoritmo di join. Questa analisi consente a un oggetto di non essere parte o rigorosamente parte di un cluster, che è chiamato partizionamento rigido di questo tipo. Tuttavia, le partizioni uniformi suggeriscono che ogni oggetto dello stesso grado appartiene a un cluster. Divisioni più specifiche possono essere create come oggetti di più cluster, un singolo cluster può essere costretto a partecipare o persino alberi gerarchici possono essere costruiti nelle relazioni di gruppo. Questo filesystem può essere implementato in diversi modi in base a vari modelli. Questi algoritmi distinti si applicano a tutti i modelli, distinguendone le proprietà e i risultati. Un buon algoritmo di clustering è in grado di identificare il cluster indipendentemente dalla forma del cluster. Esistono 3 fasi di base dell'algoritmo di clustering che sono mostrate di seguito
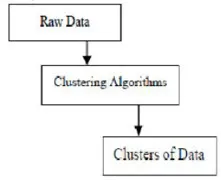
Algoritmi di clustering nel data mining
A seconda dei modelli di cluster descritti di recente, è possibile utilizzare molti cluster per partizionare le informazioni in un set di dati. Va detto che ogni metodo ha i suoi vantaggi e svantaggi. La selezione di un algoritmo dipende dalle proprietà e dalla natura del set di dati.
I metodi di clustering per il data mining possono essere mostrati come di seguito
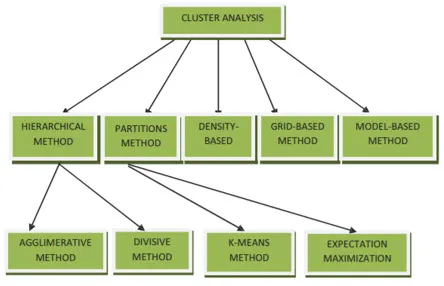
- Metodo basato sul partizionamento
- Metodo basato sulla densità
- Metodo basato sul centroide
- Metodo gerarchico
- Metodo basato su griglia
- Metodo basato sul modello
1. Metodo basato sul partizionamento
L'algoritmo di partizione divide i dati in molti sottoinsiemi.
Supponiamo che l'algoritmo di partizionamento costruisca la partizione di dati poiché k e n sono gli oggetti presenti nel database. Quindi ogni partizione sarà rappresentata come k ≤ n.
Questo dà l'idea che la classificazione dei dati sia in k gruppi, che può essere mostrato di seguito
La Figura 1 mostra i punti originali nel raggruppamento

La Figura 2 mostra il clustering delle partizioni dopo aver applicato un algoritmo
Ciò indica che ogni gruppo ha almeno un oggetto, così come ogni oggetto, deve appartenere esattamente a un gruppo.
2. Metodo basato sulla densità
Questi algoritmi producono cluster in una posizione determinata in base all'alta densità dei partecipanti al set di dati. Aggrega alcune nozioni di intervallo per i membri del gruppo nei cluster a un livello standard di densità. Tali processi possono comportare meno nel rilevare le aree di superficie del gruppo.
3. Metodo basato sul centroide
Quasi ogni cluster è referenziato da un vettore di valori in questo tipo di tecnica di raggruppamento os. Rispetto ad altri cluster, ogni oggetto fa parte del cluster con una differenza minima di valore. Il numero di cluster dovrebbe essere predefinito e questo è il problema di algoritmo più grande di questo tipo. Questa metodologia è la più vicina all'argomento dell'identificazione ed è ampiamente utilizzata per problemi di ottimizzazione.
4. Metodo gerarchico
Il metodo creerà una decomposizione gerarchica di un determinato set di oggetti dati. In base a come si forma la decomposizione gerarchica, possiamo classificare i metodi gerarchici. Questo metodo è dato come segue
- Approccio Agglomerativo
- Approccio Divisivo
Approccio agglomerativo è anche noto come approccio Button-up. Qui iniziamo con ogni oggetto che costituisce un gruppo separato. Continua a fondere oggetti o gruppi vicini
L'approccio divisivo è anche noto come approccio dall'alto verso il basso. Iniziamo con tutti gli oggetti nello stesso cluster. Questo metodo è rigido, cioè non può mai essere annullato una volta completata una fusione o divisione
5. Metodo basato su griglia
I metodi basati su griglia funzionano nello spazio oggetti invece di dividere i dati in una griglia. La griglia è divisa in base alle caratteristiche dei dati. Utilizzando questo metodo i dati non numerici sono facili da gestire. L'ordine dei dati non influisce sul partizionamento della griglia. Un vantaggio importante di un modello basato su griglia offre una maggiore velocità di esecuzione.
I vantaggi del clustering gerarchico sono i seguenti
- È applicabile a qualsiasi tipo di attributo.
- Offre flessibilità in relazione al livello di granularità.
6. Metodo basato su modello
Questo metodo utilizza un modello ipotizzato basato sulla distribuzione di probabilità. Raggruppando la funzione di densità, questo metodo individua i cluster. Riflette la distribuzione spaziale dei punti dati.
Applicazione del clustering in Data Mining
Il clustering può aiutare in molti campi come in biologia, piante e animali classificati in base alle loro proprietà, nonché nel marketing, il clustering aiuterà a identificare i clienti di un determinato record di clienti con comportamenti simili. In molte applicazioni, come ricerche di mercato, riconoscimento di modelli, elaborazione di dati e immagini, l'analisi del clustering viene utilizzata in gran numero. Il clustering può anche aiutare gli inserzionisti nella loro base di clienti a trovare diversi gruppi. E i loro gruppi di clienti possono essere definiti acquistando modelli. In biologia, viene utilizzato per la determinazione delle tassonomie vegetali e animali, per la categorizzazione di geni con funzionalità simile e per la comprensione delle strutture intrinseche alla popolazione. In un database di osservazione della terra, il raggruppamento semplifica anche la ricerca di aree di uso simile nel territorio. Aiuta a identificare gruppi di case e appartamenti per tipo, valore e destinazione delle case. Il raggruppamento di documenti sul Web è utile anche per la scoperta di informazioni. L'analisi del cluster è uno strumento per ottenere informazioni dettagliate sulla distribuzione dei dati per osservare le caratteristiche di ciascun cluster come funzione di data mining.
Conclusione
Il clustering è importante nel data mining e nella sua analisi. In questo articolo, abbiamo visto come è possibile eseguire il clustering applicando vari algoritmi di clustering e la sua applicazione nella vita reale.
Articolo raccomandato
Questa è stata una guida a Che cos'è il clustering nel data mining. Qui abbiamo discusso i concetti, la definizione, le caratteristiche, l'applicazione del clustering nel data mining. Puoi anche consultare i nostri altri articoli suggeriti per saperne di più -
- Che cos'è l'elaborazione dei dati?
- Come diventare un analista di dati?
- Che cos'è SQL Injection?
- Definizione di cos'è SQL Server?
- Panoramica dell'architettura di data mining
- Clustering in Machine Learning
- Algoritmo di clustering gerarchico
- Clustering gerarchico Clustering agglomerativo e divisivo