
Introduzione alla scienza dei dati
Data Science è uno dei lavori in più rapida crescita, stimolante e altamente remunerativo di questo decennio. Quindi, la domanda è: cos'è la scienza dei dati? la scienza dei dati è un campo interdisciplinare (è costituito da più di una branca di studio) che utilizza algoritmi statistici, informatici e di apprendimento automatico per ottenere approfondimenti da dati strutturati e non strutturati. Secondo "Economic Times", l'India ha visto aumentare di oltre il 400% la domanda di professionisti della scienza dei dati in vari settori industriali in un momento in cui l'offerta di tali talenti è testimone di una crescita lenta.
Componenti principali di Data Science
I principali componenti o processi seguiti nell'Introduzione alla scienza dei dati sono i seguenti:
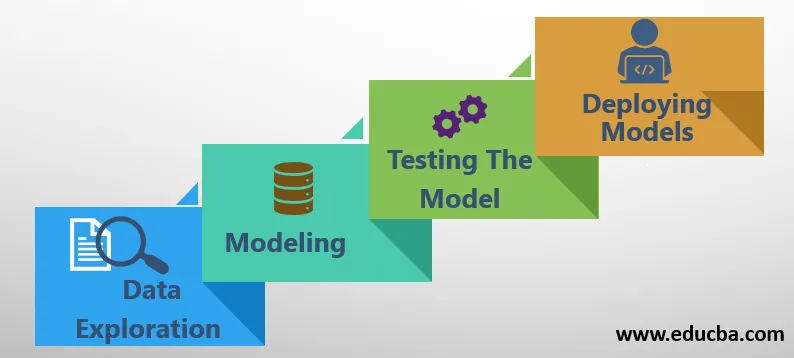
1. Esplorazione dei dati
È il passaggio più importante poiché questo passaggio richiede più tempo. Circa il 70 percento del tempo è dedicato all'esplorazione dei dati. L'ingrediente principale per la scienza dei dati sono i dati, quindi quando otteniamo i dati, raramente i dati sono in una forma strutturata corretta. C'è molto rumore presente nei dati. Il rumore qui significa molti dati indesiderati che non sono richiesti. Quindi cosa facciamo in questo passaggio? Questo passaggio prevede il campionamento e la trasformazione dei dati in cui controlliamo le osservazioni (righe) e le caratteristiche (colonne) e rimuoviamo il rumore utilizzando metodi statistici. Questo passaggio viene anche utilizzato per verificare la relazione tra le varie funzionalità (colonne) nel set di dati, per relazione intendiamo se le funzionalità (colonne) sono dipendenti l'una dall'altra o indipendenti l'una dall'altra, se ci sono valori mancanti nei dati o no. Quindi sostanzialmente i dati vengono trasformati e preparati per un ulteriore utilizzo. Quindi questo è uno dei passaggi che richiedono più tempo.
2. Modellazione
Quindi, ormai i nostri dati sono pronti e pronti all'uso. Questo è il secondo passo in cui utilizziamo effettivamente gli algoritmi di Machine Learning. Qui inseriamo effettivamente i dati nel modello. La selezione di un modello dipende dal tipo di dati in nostro possesso e dalle esigenze aziendali. Ad esempio, la selezione del modello per raccomandare un articolo a un cliente sarà diversa dal modello richiesto per prevedere il numero di articoli che verranno venduti in un determinato giorno. Una volta deciso il modello, inseriamo i dati nel modello.
3. Test del modello
È il passo successivo e molto importante per quanto riguarda le prestazioni del modello. Il modello viene testato con i dati di test per verificare l'accuratezza e altre caratteristiche del modello e apportare le modifiche necessarie nel modello per ottenere il risultato desiderato. Nel caso in cui non otteniamo l'accuratezza desiderata, possiamo di nuovo andare al passaggio 2 (modellazione) selezionare un modello diverso e quindi ripetere lo stesso passaggio 3 e scegliere il modello che offre il miglior risultato in base ai requisiti aziendali.
4. Distribuzione dei modelli
Una volta ottenuto il risultato desiderato eseguendo test adeguati in base ai requisiti aziendali, finalizziamo il modello che ci offre il miglior risultato in base ai risultati dei test e implementiamo il modello nell'ambiente di produzione.
Caratteristiche della scienza dei dati
Le caratteristiche di un data scientist sono le seguenti:
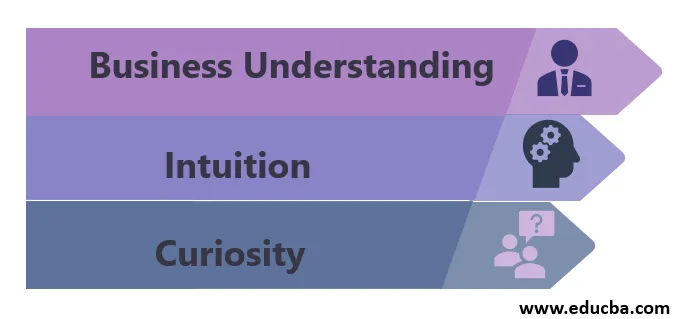
1. Comprensione aziendale
È la caratteristica più importante in quanto se non si capisce il business non è possibile creare un buon modello anche se si ha una buona conoscenza degli algoritmi di machine learning o delle capacità statistiche. Uno scienziato di dati deve comprendere i requisiti aziendali e sviluppare analisi in base ad esso. Pertanto, anche la conoscenza del dominio dell'azienda diventa importante o utile.
2. Intuizione
Sebbene la matematica coinvolta sia comprovata e fondamentale, ma uno scienziato di dati deve scegliere il modello giusto con la giusta precisione. Poiché tutti i modelli non daranno esattamente gli stessi risultati. Quindi uno scienziato di dati deve sentire quando un modello è pronto per l'implementazione della produzione. Hanno anche bisogno dell'intuizione di sapere a che punto il modello di produzione è obsoleto e necessita di refactoring per rispondere al mutevole contesto economico.
3. Curiosità
La scienza dei dati non è un nuovo campo. Lo è stato anche in passato, ma i progressi in questo campo sono molto rapidi e nuovi metodi per risolvere i problemi familiari vengono costantemente sviluppati, così come la curiosità dei data scientist per apprendere le tecnologie emergenti diventa molto importante.
applicazioni
Qui nell'introduzione alla scienza dei dati, abbiamo chiarito che le applicazioni della scienza dei dati sono enormi. È richiesto in ogni campo. Ecco alcuni esempi di alcuni settori in cui la scienza dei dati può essere utilizzata o utilizzata attivamente.
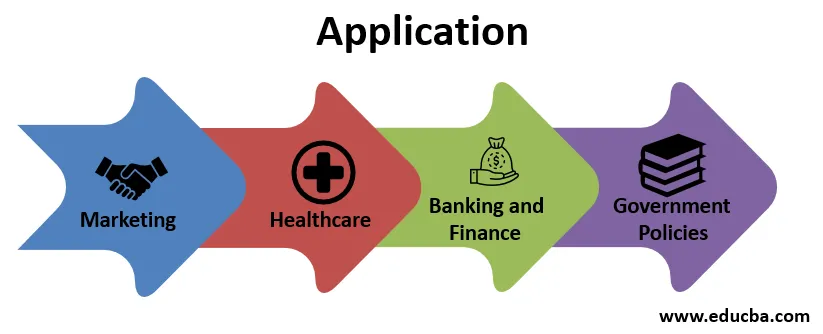
1. Marketing
Esiste un vasto campo di applicazione nel marketing, ad esempio, Strategia di prezzo migliorata Aziende come Uber, le aziende di e-commerce possono utilizzare i prezzi basati sulla scienza dei dati che consente loro di aumentare i loro profitti.
2. Assistenza sanitaria
Utilizzo di dati indossabili per prevenire e monitorare problemi di salute. I dati generati dall'organismo possono essere utilizzati in ambito sanitario per prevenire emergenze future.
3. Attività bancarie e finanziarie
Mentre discutiamo dell'introduzione della scienza dei dati, andremo avanti con l'applicazione degli usi della scienza dei dati nel settore bancario per il rilevamento delle frodi che può essere utile per ridurre le attività deteriorate delle banche.
4. Politiche governative
Il governo può utilizzare la scienza dei dati per preparare politiche migliori per soddisfare meglio le esigenze delle persone e ciò che desiderano utilizzando i dati che possono ottenere conducendo sondaggi e altri da altre fonti ufficiali.
Vantaggi e svantaggi della scienza dei dati
Dopo aver esaminato tutti i componenti, le caratteristiche e l'ampia Introduzione alla Data Science, esploreremo i vantaggi e gli svantaggi di Data Science:
vantaggi
In questo argomento di Introduzione alla scienza dei dati, ti mostriamo anche i vantaggi della scienza dei dati. Alcuni di questi sono i seguenti:
- Ci aiuta a ottenere approfondimenti dai dati storici con i suoi potenti strumenti.
- Aiuta a ottimizzare il business, assumere le persone giuste e generare maggiori entrate poiché l'utilizzo della scienza dei dati ti aiuta a prendere decisioni future migliori per il business.
- Le aziende possono sviluppare e commercializzare i loro prodotti meglio in quanto possono selezionare meglio i loro clienti target.
- L'introduzione alla scienza dei dati aiuta anche i consumatori a cercare beni migliori, soprattutto nei siti di e-commerce basati sul sistema di raccomandazioni basato sui dati.
svantaggi
Mentre studiamo sull'introduzione alla scienza dei dati ora stiamo andando avanti con gli svantaggi della scienza dei dati:
Gli svantaggi sono generalmente quando la scienza dei dati viene utilizzata per la profilazione dei clienti e la violazione della privacy dei clienti, in quanto le loro informazioni, quali transazioni, acquisti e abbonamenti, sono visibili alle loro società madri. Le informazioni ottenute utilizzando la scienza dei dati possono essere utilizzate contro un determinato gruppo, individuo, paese o comunità.
Articoli consigliati
Questa è stata una guida all'introduzione alla scienza dei dati. Qui abbiamo discusso dell'introduzione alla scienza dei dati con i componenti e le caratteristiche principali dell'introduzione alla scienza dei dati. Puoi anche consultare i seguenti articoli:
- Data Science vs Data Visualization
- Domande di intervista di data science
- Data Science vs Data Analytics
- Predictive Analytics vs Data Science
- Algoritmi di scienza dei dati | tipi