

Differenza tra Apache Nifi e Apache Spark
Fino a molto tempo, quando c'era un lavoro pesante che doveva essere completato, le persone si affidavano ai cavalli per tirare carichi pesanti, mantenere la velocità o qualsiasi altra via di mezzo. Tuttavia, non tutti i cavalli erano adatti per ogni compito. Lo stesso vale per la tecnologia oggi. Con l'avvento delle nuove tecnologie che affluiscono ogni giorno, diventa estremamente importante conoscere le loro reali applicazioni. Due di queste tecnologie sono Apache Nifi e Apache Spark e ne studieremo in questo post.
Apache Spark è un framework open source per il calcolo di cluster che mira a fornire un'interfaccia per la programmazione di interi gruppi di cluster con tolleranza agli errori implicita e parallelismo dei dati. Si avvale di RDD (Resilient Distributed Dataset) ed elabora i dati sotto forma di stream discreti che vengono ulteriormente utilizzati a fini analitici.
Apache Nifi (che è la forma abbreviata di NiagaraFiles) è un altro progetto software che mira ad automatizzare il flusso di dati tra i sistemi software. Il design si basa sul modello di programmazione basato sul flusso che fornisce funzionalità che includono il funzionamento con capacità dei cluster. È un sistema facile da usare, affidabile e potente per elaborare e distribuire dati. Supporta grafici diretti scalabili per il routing dei dati, la mediazione del sistema e la logica di trasformazione. Discutiamo i confronti di entrambi gli argomenti.
Confronto testa a testa tra Apache Nifi vs Apache Spark (Infografica)
Di seguito è riportato il top 9 Confronto tra Apache Nifi vs Apache Spark
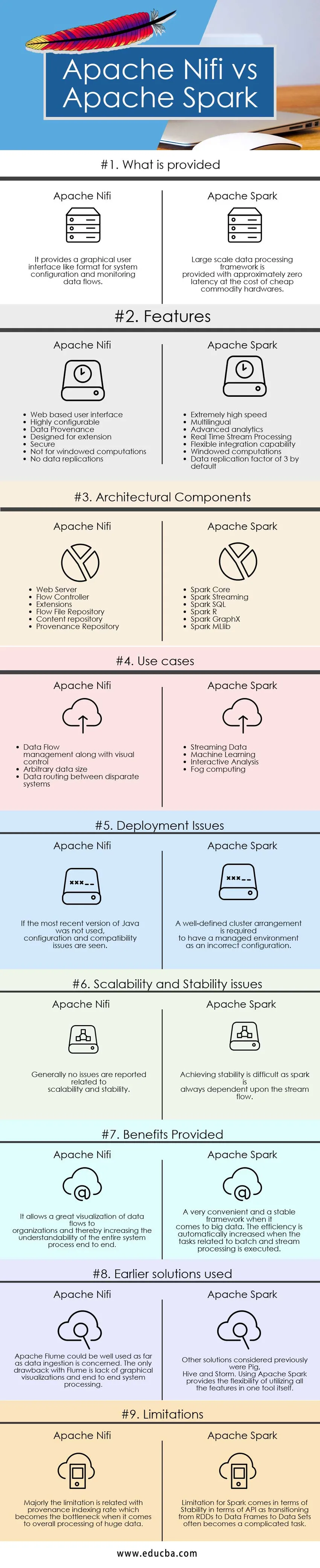
Differenze chiave tra Apache Nifi e Apache Spark
Le differenze tra Apache Nifi e Apache Spark sono spiegate nei punti presentati di seguito:
- Apache Nifi è uno strumento di ingestione di dati che viene utilizzato per fornire un sistema facile da usare, potente e affidabile in modo che l'elaborazione e la distribuzione dei dati sulle risorse diventino facili mentre Apache Spark è una tecnologia di elaborazione cluster estremamente veloce progettata per un calcolo più rapido da facendo uso efficiente di query interattive, nella gestione della memoria e nelle capacità di elaborazione del flusso.
- Apache Nifi funziona in modalità standalone e in modalità cluster, mentre Apache Spark funziona bene in modalità locale o standalone, Mesos, Yarn e altri tipi di modalità cluster di big data.
- Le funzionalità di Apache Nifi includono la consegna garantita di dati, buffering efficiente dei dati, accodamento prioritario, QoS specifico per flusso, provenienza dei dati, ripristino del buffer di rollio, comando e controllo visivi, modelli di flusso, sicurezza, funzionalità di streaming parallelo mentre le funzionalità di Apache Spark includono un lampo veloce capacità di elaborazione della velocità, multilingua, elaborazione in memoria, utilizzo efficiente dei sistemi hardware di base, analisi avanzata, capacità di integrazione efficiente.
- Apache Nifi consente una migliore leggibilità e comprensione generale del sistema fornendo funzionalità di visualizzazione e funzionalità di trascinamento della selezione. Il flusso di dati può essere facilmente gestito e regolato utilizzando tecniche e processi convenzionali, mentre nel caso di Apache Spark per visualizzare questo tipo di visualizzazioni è necessario un sistema di gestione dei cluster come Ambari. Apache Spark in sé non fornisce funzionalità di visualizzazione ed è utile solo per quanto riguarda la programmazione. È di gran lunga un sistema molto conveniente e stabile per l'elaborazione di enormi quantità di dati.
- La limitazione con Apache Nifi è legata a quale sia il suo vantaggio. L'unica funzione di trascinamento della selezione offre una limitazione di non essere in grado di ridimensionare e fornire robustezza quando si tratta di integrarla con altri componenti e strumenti, mentre in caso di Apache Spark la limitazione principale si accompagna all'uso di hardware hardware ampio e alla loro gestione a volte diventa un compito noioso. L'altra limitazione segnalata arriva con le sue funzionalità di streaming relative a Discretized Stream e Windowed o batch stream in cui la trasformazione di RDD in frame di dati e set di dati fornisce a volte una causa di instabilità.
Tabella di confronto tra Apache Nifi e Apache Spark
| Base di confronto | Apache Nifi | Apache Spark |
| Cosa viene fornito | Fornisce un'interfaccia utente grafica come un formato per la configurazione del sistema e il monitoraggio dei flussi di dati. | Il framework di elaborazione dati su larga scala viene fornito con latenza approssimativamente pari a zero a costo dell'hardware economico delle materie prime. |
| Caratteristiche |
|
|
| Componenti architettonici |
|
|
| Casi d'uso |
|
|
| Problemi di distribuzione | Se non è stata utilizzata la versione più recente di Java, vengono visualizzati problemi di configurazione e compatibilità | È necessario un accordo cluster ben definito per avere un ambiente gestito come una configurazione errata |
| Problemi di scalabilità e stabilità | Generalmente non vengono segnalati problemi relativi a scalabilità e stabilità | Raggiungere la stabilità è difficile poiché una scintilla dipende sempre dal flusso del flusso. |
| Vantaggi forniti | Consente una grande visualizzazione dei flussi di dati verso le organizzazioni e quindi aumenta la comprensione dell'intero processo di sistema end-to-end | Un framework molto conveniente e stabile quando si tratta di big data. L'efficienza aumenta automaticamente quando vengono eseguite le attività relative all'elaborazione batch e stream. |
| Soluzioni precedenti utilizzate | Apache Flume potrebbe essere ben utilizzato per quanto riguarda l'ingestione di dati. L'unico inconveniente di Flume è la mancanza di visualizzazioni grafiche e l'elaborazione del sistema end-to-end | Altre soluzioni considerate in precedenza erano Pig, Hive e Storm. L'uso di Apache Spark offre la flessibilità di utilizzare tutte le funzionalità in uno stesso strumento. |
| limitazioni | Principalmente la limitazione è legata al tasso di indicizzazione della provenienza che diventa il collo di bottiglia quando si tratta dell'elaborazione complessiva di enormi dati | Limitazione per Spark arriva in termini di stabilità in termini di API poiché la transizione da RDD a frame di dati a set di dati diventa spesso un'attività complicata. |
Conclusione - Apache Nifi vs Apache Spark
Per concludere il post, si può dire che Apache Spark è un cavallo da guerra pesante mentre Apache Nifi è un cavallo da corsa agile. Entrambi hanno i propri vantaggi e limitazioni da utilizzare nelle rispettive aree. Devi decidere lo strumento giusto per la tua azienda. Resta sintonizzato sul nostro blog per ulteriori articoli relativi alle più recenti tecnologie di big data.
Articolo raccomandato
Questa è stata una guida per Apache Nifi vs Apache Spark, il loro significato, confronto testa a testa, differenze chiave, tabella di confronto e conclusioni. Puoi anche consultare i seguenti articoli per saperne di più -
- Apache Hadoop vs Apache Spark | I 10 migliori confronti che devi sapere!
- Apache Storm vs Apache Spark: impara 15 differenze utili
- 7 cose importanti su Apache Spark (Guida)
- Le 15 migliori cose che devi sapere su MapReduce vs Spark