

Introduzione ad ANOVA in R
Il seguente articolo ANOVA in R fornisce uno schema per confrontare il valore medio di diversi gruppi. Un'analisi della varianza (ANOVA) è una tecnica molto comune utilizzata per confrontare il valore medio di diversi gruppi. Il modello ANOVA viene utilizzato per il test delle ipotesi, in cui determinati presupposti o parametri vengono generati per una popolazione e il metodo statistico viene utilizzato per determinare se l'ipotesi è vera o falsa.
L'ipotesi deriva dall'ipotesi dello sperimentatore e dalle informazioni disponibili sulla popolazione. L'ANOVA è chiamata Analisi della varianza e viene utilizzata per test di ipotesi in cui è necessario misurare i mezzi di una variabile in più gruppi indipendenti.
Ad esempio, in un laboratorio per studiare o inventare un nuovo farmaco per l'obesità, i ricercatori confronteranno il risultato del trattamento sperimentale e standard. In uno studio sull'obesità, si possono derivare risultati preziosi quando il tasso medio di obesità della popolazione può essere confrontato in diverse fasce di età. In questo caso, si vorrebbe osservare il tasso medio di obesità tra le diverse fasce di età come l'età (da 5 a 18), (19, 35) e (da 36 a 50). Il metodo ANOVA viene applicato in quanto vi sono più di due gruppi indipendenti. Il metodo ANOVA viene utilizzato per confrontare l'obesità media dei gruppi indipendenti. Viene utilizzata la funzione aov () e la sintassi è aov (formula, data = dataframe) In questo articolo, impareremo a conoscere il modello ANOVA e discuteremo ulteriormente del modello ANOVA a senso unico e bidirezionale insieme ad esempi.
Perché ANOVA
- Questa tecnica viene utilizzata per rispondere all'ipotesi durante l'analisi di più gruppi di dati. Esistono diversi approcci statistici, tuttavia, l'ANOVA in R viene applicato quando il confronto deve essere effettuato su più di due gruppi indipendenti, come nel nostro esempio precedente tre diverse fasce di età.
- La tecnica ANOVA misura la media dei gruppi indipendenti per fornire ai ricercatori il risultato dell'ipotesi. Per ottenere risultati accurati, è necessario tenere conto delle medie del campione, della dimensione del campione e della deviazione standard da ciascun singolo gruppo.
- È possibile osservare la media individualmente per ciascuno dei tre gruppi per il confronto. Tuttavia, questo approccio presenta delle limitazioni e potrebbe rivelarsi errato poiché questi tre confronti non considerano i dati totali e pertanto potrebbero causare errori di tipo 1. R ci fornisce la funzione di condurre l'analisi ANOVA per esaminare la variabilità tra i gruppi indipendenti di dati. Esistono cinque fasi per condurre l'analisi ANOVA. Nella prima fase, i dati sono disposti in formato CSV e la colonna viene generata per ogni variabile. Una delle colonne sarebbe una variabile dipendente e restanti sono la variabile indipendente. Nella seconda fase, i dati vengono letti in R studio e denominati in modo appropriato. Nella terza fase, un set di dati è collegato a singole variabili e letto dalla memoria. Infine, l'ANOVA in R viene definita e analizzata. Nelle sezioni seguenti ho fornito un paio di esempi di casi studio in cui dovrebbero essere utilizzate le tecniche ANOVA.
- Sei insetticidi sono stati testati su 12 campi ciascuno e i ricercatori hanno contato il numero di bug rimasti in ciascun campo. Ora gli agricoltori devono sapere se gli insetticidi fanno la differenza e, in caso affermativo, quale utilizzare meglio. Rispondi a questa domanda utilizzando la funzione aov () per eseguire un ANOVA.
- Cinquanta pazienti hanno ricevuto uno dei cinque trattamenti farmacologici per ridurre il colesterolo (trt). Tre delle condizioni di trattamento riguardavano lo stesso farmaco somministrato come 20 mg una volta al giorno (1 volta) 10 mg due volte al giorno (2 volte) 5 mg quattro volte al giorno (4 volte). Le due condizioni rimanenti (drugD e drugE) rappresentavano farmaci concorrenti. Quale trattamento farmacologico ha prodotto la maggiore riduzione del colesterolo (risposta)?
ANOVA a senso unico
- Il metodo unidirezionale è una delle tecniche di base ANOVA in cui viene applicata l'analisi della varianza e viene confrontato il valore medio di più gruppi di popolazione.
- L'ANOVA a una via ha preso il nome dalla disponibilità di dati classificati a una via. In una sola ANOVA variabile dipendente singola e una o più variabili indipendenti possono essere disponibili.
- Ad esempio, eseguiremo la tecnica ANOVA sul set di dati del colesterolo. Il set di dati è composto da due variabili trt (che sono trattamenti a 5 livelli diversi) e variabili di risposta. Variabile indipendente - gruppi di trattamento farmacologico, variabile dipendente - mezzi di 2 o più gruppi ANOVA. Da questi risultati, è possibile confermare che l'assunzione delle dosi da 5 mg 4 volte al giorno era meglio che assumere una dose da venti mg una volta al giorno. La droga D ha effetti migliori rispetto a quella droga E
Il farmaco D fornisce risultati migliori se assunto in dosi di 20 mg rispetto al farmaco E
Utilizza il set di dati del colesterolo nel pacchetto multcompinstall.packages('multcomp')
library(multcomp)
str(cholesterol)
attach(cholesterol)
aov_model <- aov(response ~ trt)
Il test ANOVA F per il trattamento (trt) è significativo (p <.0001), fornendo prove che i cinque trattamenti
# non sono tutti ugualmente efficaci.
riassunto (aov_model)
detach (colesterolo)

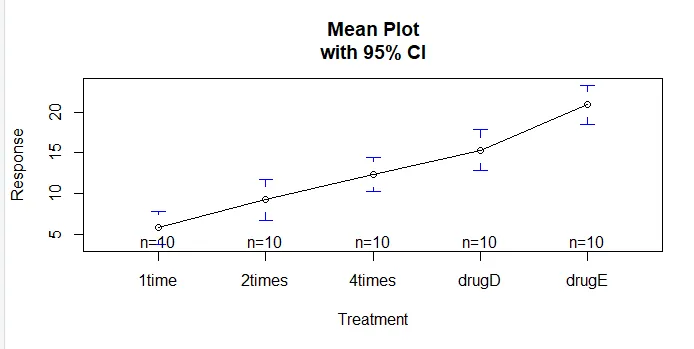
La funzione plotmeans () nel pacchetto gplots può essere usata per produrre un grafico dei mezzi del gruppo e dei loro intervalli di confidenza Ciò mostra chiaramente le differenze di trattamentoinstall.packages('gplots')
library(gplots)
plotmeans(response ~ trt, xlab="Treatment", ylab="Response",
main="Mean Plot\nwith 95% CI")
Esaminiamo l'output di TukeyHSD () per le differenze a coppie tra medie di gruppo
TukeyHSD (aov_model)
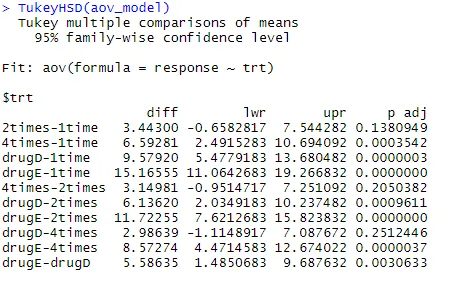
Le riduzioni medie del colesterolo per 1 volta e 2 volte non sono significativamente diverse l'una dall'altra (p = 0, 138), mentre la differenza tra 1 volta e 4 volte è significativamente diversa (p <.001).
par (mar = c (5, 8, 4, 2)) # aumenta la trama del margine sinistro (TukeyHSD (aov_model), las = 2)
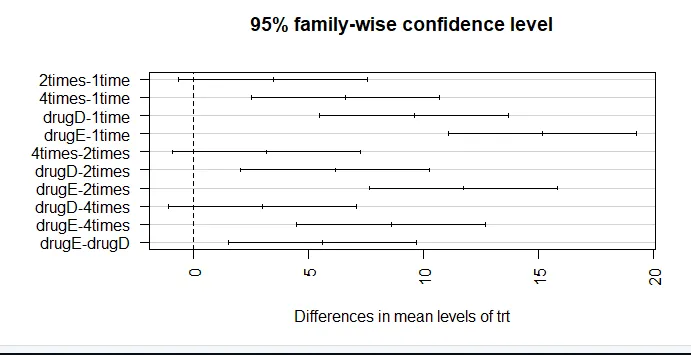
La fiducia nei risultati dipende dal grado in cui i dati soddisfano i presupposti alla base dei test statistici. In un ANOVA a senso unico, si presume che la variabile dipendente sia normalmente distribuita e abbia una varianza uguale in ciascun gruppo. È possibile utilizzare un diagramma QQ per valutare la libreria di assunzioni di normalità (auto).
Grafico QQ (lm (risposta ~ trt, dati = colesterolo), simulazione = VERO, principale = "Grafico QQ", etichette = FALSO)
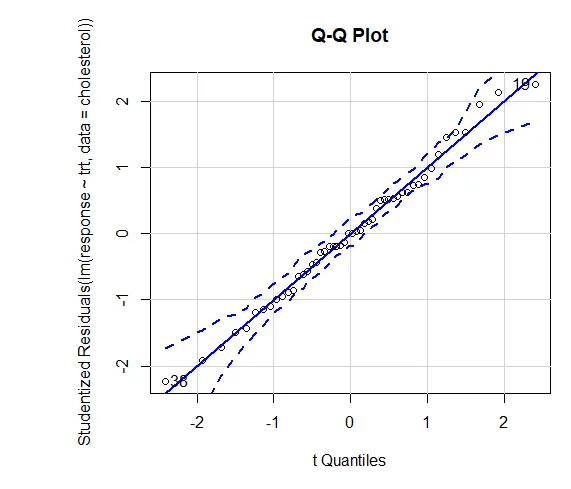
Linea tratteggiata = inviluppo di confidenza al 95%, suggerendo che l'assunzione della normalità è stata soddisfatta abbastanza bene ANOVA presume che le varianze siano uguali tra gruppi o campioni. Il test Bartlett può essere utilizzato per verificare tale presupposto
bartlett.test (risposta ~ trt, dati = colesterolo). Il test di Bartlett indica che le varianze nei cinque gruppi non differiscono in modo significativo (p = 0, 97).
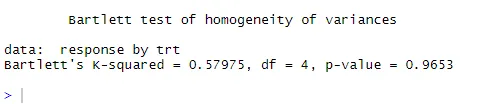
ANOVA è anche sensibile al test degli outlier per gli outlier utilizzando la funzione outlierTest () nel pacchetto auto. Potrebbe non essere necessario eseguire questo pacchetto per aggiornare la libreria dell'auto.update.packages(checkBuilt = TRUE)
install.packages("car", dependencies = TRUE)
library(car)
outlierTest(aov_model)
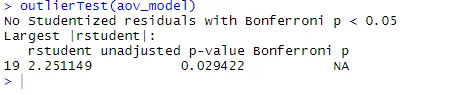
Dall'output, puoi vedere che non ci sono indicazioni di valori anomali nei dati sul colesterolo (NA si verifica quando p> 1). Prendendo insieme la trama QQ, il test di Bartlett e il test anomalo, i dati sembrano adattarsi abbastanza bene al modello ANOVA.
Anova a due vie
Un'altra variabile viene aggiunta nel test ANOVA a due vie. Quando ci sono due variabili indipendenti, avremo bisogno di usare ANOVA a due vie anziché ANOVA a una via che era stata usata nel caso precedente in cui avevamo una variabile dipendente continua e più di una variabile indipendente. Per verificare l'ANOVA a due vie, devono essere soddisfatte più ipotesi.
- Disponibilità di osservazioni indipendenti
- Le osservazioni dovrebbero essere normalmente distribuite
- La varianza dovrebbe essere uguale nelle osservazioni
- I valori anomali non dovrebbero essere presenti
- Errori indipendenti
Per verificare l'ANOVA a due vie, un'altra serie denominata BP viene aggiunta al set di dati. La variabile indica il tasso di pressione sanguigna nei pazienti. Vorremmo verificare se c'è qualche differenza statistica tra BP e dosaggio dato ai pazienti.
df <- read.csv (“file.csv”)
df
anova_two_way <- aov (risposta ~ trt + BP, data = df)
riassunto (anova_two_way)
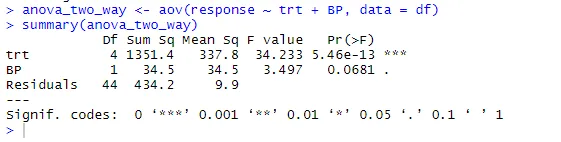
Dall'output, si può concludere che sia trt che BP sono statisticamente differenti da 0. Quindi, l'ipotesi nulla può essere respinta.
Vantaggi dell'ANOVA in R
Il test ANOVA determina la differenza nella media tra due o più gruppi indipendenti. Questa tecnica è molto utile per l'analisi di più articoli, essenziale per l'analisi del mercato. Utilizzando il test ANOVA è possibile ottenere le informazioni necessarie dai dati. Ad esempio, durante un sondaggio sul prodotto in cui vengono raccolte dagli utenti più informazioni come liste della spesa, Mi piace e antipatie dei clienti. Il test ANOVA ci aiuta a confrontare gruppi di popolazione. Il gruppo può essere maschio o femmina o varie fasce d'età. La tecnica ANOVA aiuta a distinguere tra i valori medi di diversi gruppi della popolazione che sono effettivamente diversi.
Conclusione - ANOVA in R
ANOVA è uno dei metodi più comunemente utilizzati per il test delle ipotesi. In questo articolo, abbiamo eseguito un test ANOVA sul set di dati composto da cinquanta pazienti che hanno ricevuto un trattamento farmacologico per ridurre il colesterolo e hanno ulteriormente visto come ANOVA a due vie può essere eseguito quando è disponibile un'ulteriore variabile indipendente.
Articoli consigliati
Questa è una guida per ANOVA in R. Qui discutiamo del modello Anova a senso unico e bidirezionale insieme ad esempi e vantaggi di ANOVA. Puoi anche consultare i nostri altri articoli suggeriti:
- Regressione vs ANOVA
- Che cos'è SPSS?
- Come interpretare i risultati usando ANOVA Test
- Funzioni in R