

Introduzione ai comandi dell'alveare
Il comando Hive è uno strumento di infrastruttura di data warehouse che si trova in cima a Hadoop per sintetizzare i Big Data. Elabora i dati strutturati. Semplifica l'interrogazione e l'analisi dei dati. Il comando Hive viene anche chiamato "schema in lettura;" Hive non verifica i dati quando vengono caricati, la verifica avviene solo quando viene eseguita una query. Questa proprietà di Hive lo rende veloce per il caricamento iniziale. È come copiare o spostare semplicemente un file senza vincoli o controlli. L'alveare è stato sviluppato per la prima volta da Facebook. Apache Software Foundation lo ha ripreso in seguito e lo ha sviluppato ulteriormente.
Ecco i componenti del comando Hive:
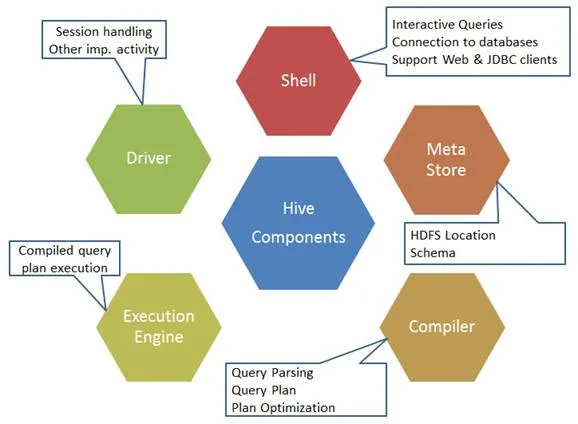
Fig 1. Componenti di Hive
https://www.developer.com/
Ecco le funzioni del comando Hive elencate di seguito:
- I negozi di alveari sono set di dati non elaborati ed elaborati in Hadoop.
- È progettato per l'elaborazione delle transazioni OnLine (OLTP). OLTP è il sistema che facilita i dati ad alto volume in pochissimo tempo senza fare affidamento sul singolo server.
- È veloce, scalabile e affidabile.
- Il linguaggio di query di tipo SQL fornito qui si chiama HiveQL o HQL. Ciò semplifica le attività ETL e altre analisi.
Fig 2. Proprietà dell'alveare
Immagini di fonti: - Google
Esistono anche alcune limitazioni al comando Hive, che sono elencate di seguito:
- Hive non supporta le subquery.
- Hive sicuramente supporta la sovrascrittura, ma sfortunatamente non supporta la cancellazione e gli aggiornamenti.
- Hive non è progettato per OLTP, ma è usato per questo.
Per accedere alla shell interattiva di Hive:
$ HIVE_HOME / bin / alveare
Comandi base dell'alveare
-
Creare
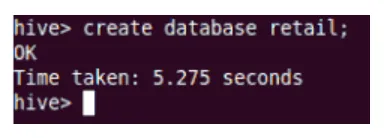
Questo creerà il nuovo database in Hive.
-
Far cadere
Il drop rimuoverà una tabella da Hive
-
Alter
Il comando Alter ti aiuterà a rinominare la tabella o le colonne della tabella.
Per esempio:
hive> ALTER TABLE dipendente RENAME TO dipendente1;
-
Mostrare
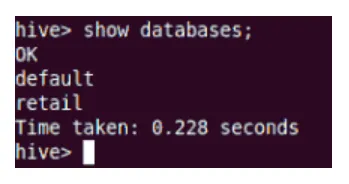
Il comando Show mostrerà tutti i database che risiedono in Hive.
-
Descrivere
Il comando Describe ti aiuterà con le informazioni sullo schema della tabella.
Comandi intermedi dell'alveare
Hive divide una tabella in partizioni variamente correlate basate su colonne. Usando queste partizioni, diventa più facile interrogare i dati. Queste partizioni vengono ulteriormente suddivise in bucket, per eseguire query in modo efficiente sui dati.
In altre parole, i bucket distribuiscono i dati nel set di cluster calcolando il codice hash della chiave menzionato nella query.
-
Aggiunta di una partizione
L'aggiunta della partizione può essere realizzata modificando la tabella. Supponi di avere una tabella "EMP", con campi come ID, nome, stipendio, dipartimento, designazione e yoj.
alveare> dipendente ALTER TABLE
> ADD PARTITION (year = '2012')
posizione '/ 2012 / part2012';
-
Rinominare la partizione
hive> ALTER TABLE dipendente PARTITION (year = '1203')
Rinomina alla partizione (Yoj = '1203');
-
Elimina partizione
alveare> ALTER TABLE DROP dipendente (SE ESISTE)
> PARTITION (year = '1203');
-
Operatori relazionali
Gli operatori relazionali sono costituiti da un determinato insieme di operatori, che aiuta a recuperare informazioni pertinenti.
Ad esempio: supponiamo che la tabella "EMP" sia simile alla seguente:
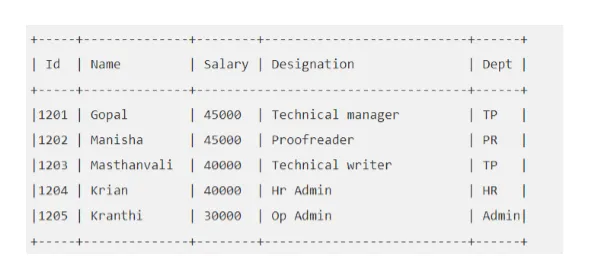
Eseguiamo la query Hive che ci porterà il dipendente il cui stipendio è maggiore di 30000.
alveare> SELEZIONA * DALL'EMP DOVE Stipendio> = 40000;
-
Operatori aritmetici
Si tratta di operatori che aiutano nella realizzazione di operazioni aritmetiche sugli operandi e, a loro volta, restituiscono sempre tipi di numeri.
Ad esempio: per aggiungere due numeri come 22 e 33
alveare> SELEZIONA 22 + 33 AGGIUNGI DA temp;
-
Operatore logico
Questi operatori devono eseguire operazioni logiche, che in cambio restituiscono sempre Vero / Falso.
alveare> SELEZIONA * DALL'EMP DOVE Stipendio> 40000 && Dept = TP;
Comandi Hive avanzati
-
Visualizza
Il concetto di visualizzazione in Hive è simile come in SQL. La vista può essere creata al momento dell'esecuzione di un'istruzione SELECT.
Esempio:
hive> CREATE VIEW EMP_30000 AS
SELEZIONA * DA EMP
DOVE stipendio> 30000;
-
Caricamento dei dati nella tabella
Hive> Carica dati inpath locale '/home/hduser/Desktop/AllStates.csv' negli stati della tabella;
Qui "States" è la tabella già creata in Hive.
https://www.tutorialspoint.com/hive/
Hive ha alcune funzioni integrate che ti aiutano a recuperare i risultati in un modo migliore.
Come tondo, piano, GRANDE ecc.
-
Aderire
La clausola Join può aiutare a unire due tabelle in base allo stesso nome di colonna.
Esempio:
hive> SELECT c.ID, c.NAME, c.AGE, o.AMOUNT
DA CLIENTI c ISCRIVITI ORDINI o
ON (c.ID = o.CUSTOMER_ID);
Tutti i tipi di join sono supportati da Hive: join esterno sinistro, join esterno destro, join esterno completo.
Suggerimenti e trucchi per utilizzare i comandi hive
Hive rende l'elaborazione dei dati così semplice, diretta ed estensibile, che l'utente presta meno attenzione all'ottimizzazione delle query Hive. Ma prestare attenzione a poche cose mentre si scrive query Hive, porterà sicuramente grande successo nella gestione del carico di lavoro e nel risparmio di denaro. Di seguito sono riportati alcuni suggerimenti a riguardo:
- Partizioni e bucket: Hive è uno strumento per big data che può eseguire query su set di dati di grandi dimensioni. Tuttavia, scrivere la query senza comprendere il dominio può portare grandi partizioni in Hive.
Se l'utente è a conoscenza del set di dati, le colonne pertinenti e altamente utilizzate potrebbero essere raggruppate nella stessa partizione. Ciò contribuirà a eseguire la query in modo più rapido e inefficiente.
In definitiva il no. verranno ridotte anche le operazioni di mapper e I / O.
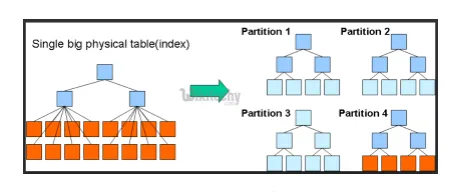
Fig 3. Partizionamento
Immagini di fonti: immagine di Google
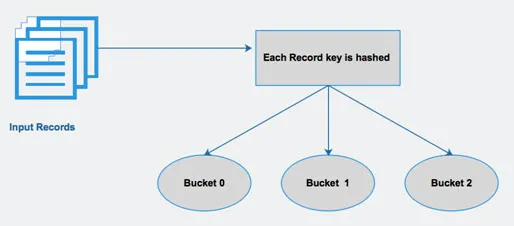
Fig 4 Bucketing
Immagini di fonti: - Immagine di Google
- Esecuzione parallela: Hive esegue la query in più fasi. In alcuni casi, queste fasi possono dipendere da altre fasi, quindi non è possibile iniziare una volta completata la fase precedente. Tuttavia, attività indipendenti possono essere eseguite in parallelo per risparmiare tempo di esecuzione complessivo. Per abilitare la corsa parallela in Hive:
set hive.exec.parallel = true;
Pertanto, ciò migliorerà l'utilizzo del cluster.
- Blocco del campionamento: il campionamento dei dati da una tabella consentirà l'esplorazione di query sui dati.
Nonostante il bucking, vogliamo piuttosto campionare i set di dati in modo più casuale. Il campionamento a blocchi viene fornito con varie potenti sintassi, che aiutano a campionare i dati in vari modi.
Il campionamento può essere utilizzato per trovare ca. informazioni dal set di dati come la distanza media tra origine e destinazione.
Interrogare l'1% dei big data darà quasi la risposta perfetta. L'esplorazione diventa molto più semplice ed efficace.
Conclusione - Comandi alveare
Hive è un'astrazione di livello superiore oltre a HDFS, che fornisce un linguaggio di query flessibile. Aiuta a interrogare ed elaborare i dati in modo più semplice.
Hive può essere clubbato con altri elementi Big Data, per sfruttare la sua funzionalità in modo completo.
Articoli consigliati
Questa è stata una guida ai comandi dell'alveare. Qui abbiamo discusso Comandi Hive di base così come avanzati e alcuni comandi Hive immediati. Puoi anche leggere il seguente articolo per saperne di più -
- Interviste sull'alveare
- Hive VS Hue - I 6 migliori confronti utili
- Comandi del tableau
- Comandi Adobe Photoshop
- Utilizzo della funzione ORDER BY in Hive
- Scarica e installa Hive passo dopo passo