
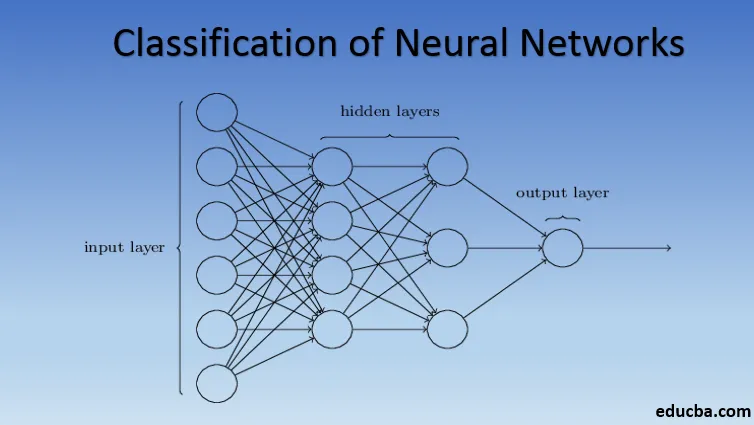
Introduzione alla classificazione della rete neurale
Le reti neurali sono il modo più efficiente (sì, hai letto bene) per risolvere i problemi del mondo reale nell'intelligenza artificiale. Attualmente, è anche una delle aree più ampiamente ricercate nell'informatica che una nuova forma di rete neurale sarebbe stata sviluppata durante la lettura di questo articolo. Esistono centinaia di reti neurali per risolvere problemi specifici a diversi domini. Qui ti guideremo attraverso diversi tipi di reti neurali di base in ordine crescente di complessità.
Diversi tipi di basi nella classificazione delle reti neurali
1. Reti neurali superficiali (filtro collaborativo)
Le reti neurali sono costituite da gruppi di Perceptron per simulare la struttura neurale del cervello umano. Le reti neurali poco profonde hanno un singolo strato nascosto del percettrone. Uno degli esempi comuni di reti neurali superficiali è il filtro collaborativo. Lo strato nascosto del percettrone verrebbe addestrato a rappresentare le somiglianze tra entità al fine di generare raccomandazioni. Il sistema di raccomandazione in Netflix, Amazon, YouTube, ecc. Utilizza una versione del filtro collaborativo per raccomandare i propri prodotti in base all'interesse dell'utente.
2. Perceptron multistrato (reti neurali profonde)
Le reti neurali con più di un livello nascosto sono chiamate reti neurali profonde. Avviso spoiler! Tutte le reti neurali seguenti sono una forma di rete neurale profonda ottimizzata / migliorata per affrontare i problemi specifici del dominio. In generale, ci aiutano a raggiungere l'universalità. Dato un numero sufficiente di strati nascosti del neurone, una rete neurale profonda può approssimarsi, cioè risolvere qualsiasi problema complesso del mondo reale.
Il teorema di approssimazione universale è il nucleo delle reti neurali profonde per formare e adattare qualsiasi modello. Ogni versione della rete neurale profonda è sviluppata da uno strato completamente collegato di un prodotto max pooled di moltiplicazione di matrice che è ottimizzato da algoritmi di backpropagation. Continueremo ad apprendere i miglioramenti risultanti in diverse forme di reti neurali profonde.
3. Rete neurale convoluzionale (CNN)
Le CNN sono la forma più matura di reti neurali profonde per produrre i risultati più accurati, cioè migliori dei risultati umani nella visione artificiale. Le CNN sono costituite da strati di Convoluzioni creati scansionando ogni pixel di immagini in un set di dati. Man mano che i dati vengono approssimati strato per strato, la CNN inizia a riconoscere gli schemi e quindi a riconoscere gli oggetti nelle immagini. Questi oggetti sono ampiamente utilizzati in varie applicazioni per l'identificazione, la classificazione, ecc. Pratiche recenti come l'apprendimento dei trasferimenti nelle CNN hanno portato a significativi miglioramenti nell'inesattezza dei modelli. Google Translator e Google Lens sono l'esempio più avanzato della CNN.
L'applicazione delle CNN è esponenziale in quanto vengono persino utilizzate per risolvere problemi che non sono principalmente legati alla visione artificiale. Una spiegazione molto semplice ma intuitiva delle CNN è disponibile qui.
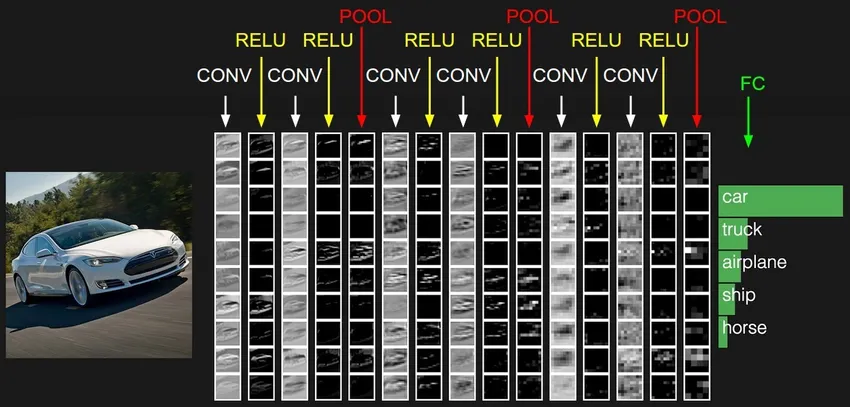
4. Rete neurale ricorrente (RNN)
Gli RNN sono la forma più recente di reti neurali profonde per risolvere i problemi della PNL. In poche parole, gli RNN restituiscono l'output di alcuni layer nascosti al layer di input per aggregare e portare avanti l'approssimazione alla successiva iterazione (epoca) del set di dati di input. Aiuta anche il modello ad autoapprendimento e corregge le previsioni più velocemente in una certa misura. Tali modelli sono molto utili per comprendere la semantica del testo nelle operazioni di PNL. Esistono diverse varianti di RNN come Long Short Term Memory (LSTM), Gated Recurrent Unit (GRU), ecc. Nello schema seguente, l'attivazione da h1 e h2 viene alimentata con l'ingresso x2 e x3 rispettivamente.
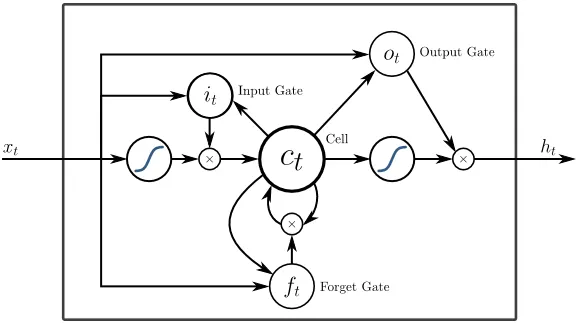
5. Memoria a breve termine (LSTM)
Gli LSTM sono progettati specificamente per affrontare il problema dei gradienti di fuga con l'RNN. I gradienti di sparizione si verificano con grandi reti neurali in cui i gradienti delle funzioni di perdita tendono ad avvicinarsi allo zero facendo mettere in pausa le reti neurali per imparare. LSTM risolve questo problema impedendo le funzioni di attivazione all'interno dei suoi componenti ricorrenti e avendo i valori memorizzati non muti. Questa piccola modifica ha apportato grandi miglioramenti al modello finale, portando i giganti della tecnologia ad adattare LSTM nelle loro soluzioni. Oltre all'illustrazione "più semplice autoesplicativa" di LSTM,
6. Reti basate sull'attenzione
I modelli di attenzione stanno lentamente prendendo il posto anche dei nuovi RNN in pratica. I modelli di attenzione sono costruiti concentrandosi su una parte di un sottoinsieme delle informazioni che vengono fornite, eliminando così la straordinaria quantità di informazioni di base che non sono necessarie per l'attività in corso. I modelli di attenzione sono costruiti con una combinazione di attenzione morbida e dura e adattamento mediante attenzione morbida a propagazione posteriore. I modelli di attenzione multipla impilati gerarchicamente sono chiamati Transformer. Questi trasformatori sono più efficienti per eseguire le pile in parallelo in modo da produrre risultati allo stato dell'arte con dati e tempi relativamente inferiori per l'addestramento del modello. Una distribuzione dell'attenzione diventa molto potente se usata con CNN / RNN e può produrre una descrizione testuale di un'immagine come segue.

I giganti della tecnologia come Google, Facebook, ecc. Stanno rapidamente adattando i modelli di attenzione per costruire le loro soluzioni.
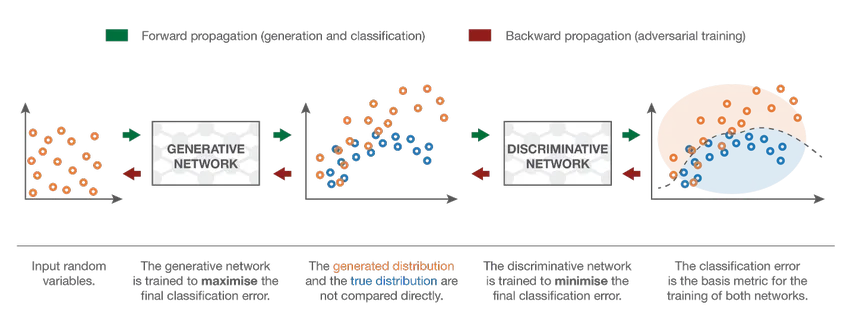
7. Generative Adversarial Network (GAN)
Sebbene i modelli di apprendimento profondo forniscano risultati allo stato dell'arte, possono essere ingannati da controparti umane molto più intelligenti aggiungendo rumore ai dati del mondo reale. I GAN sono l'ultimo sviluppo dell'apprendimento profondo per affrontare tali scenari. I GAN utilizzano l'apprendimento non supervisionato in cui le reti neurali profonde si sono allenate con i dati generati da un modello di intelligenza artificiale insieme al set di dati effettivo per migliorare l'accuratezza e l'efficienza del modello. Questi dati contraddittori sono principalmente utilizzati per ingannare il modello discriminatorio al fine di costruire un modello ottimale. Il modello risultante tende ad essere un'approssimazione migliore di quella che può superare tale rumore. L'interesse della ricerca nei GAN ha portato a implementazioni più sofisticate come Conditional GAN (CGAN), Laplacian Pyramid GAN (LAPGAN), Super Resolution GAN (SRGAN), ecc.
Conclusione - Classificazione della rete neurale
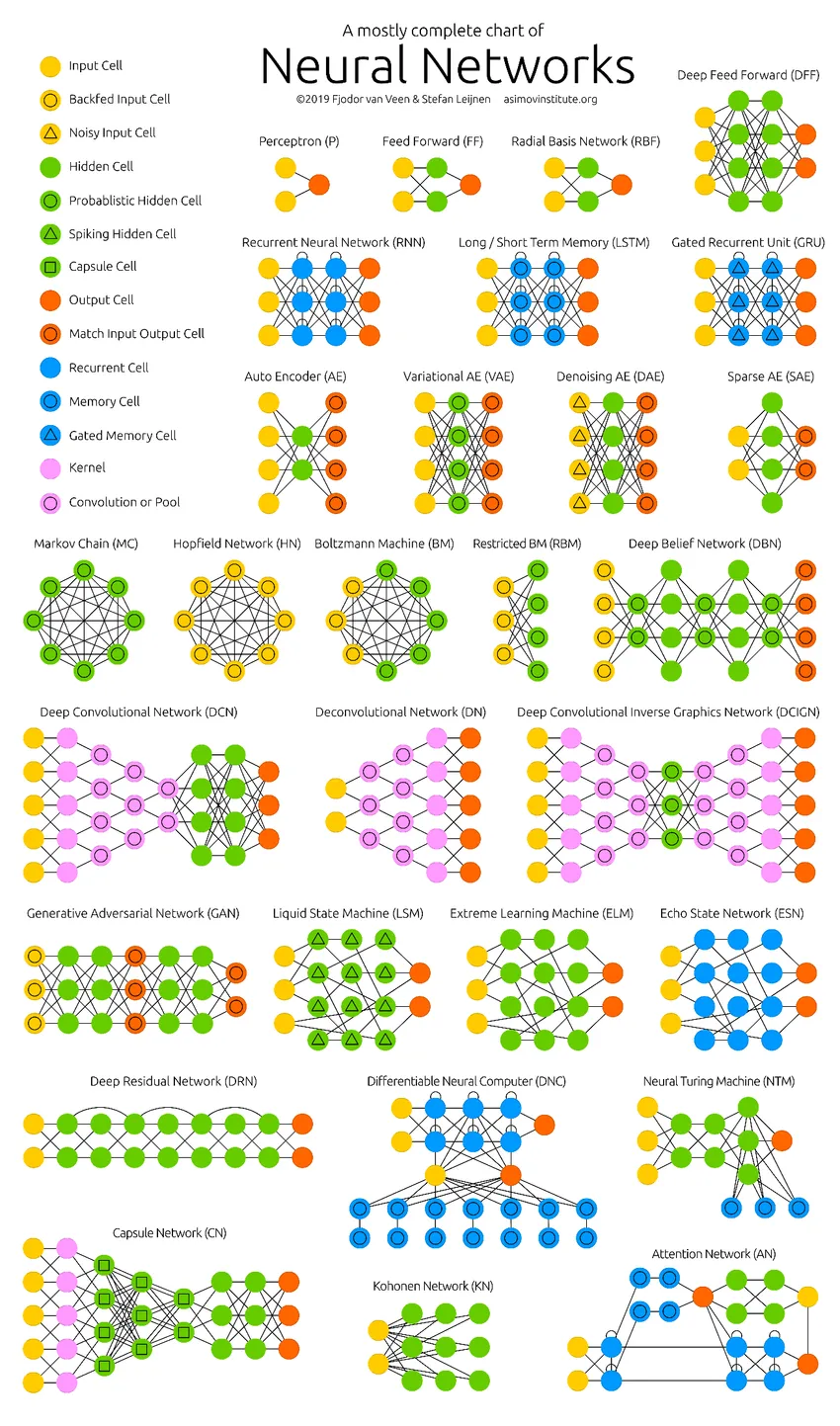
Le reti neurali profonde hanno spinto i limiti dei computer. Non si limitano solo alla classificazione (CNN, RNN) o previsioni (filtro collaborativo), ma anche alla generazione di dati (GAN). Questi dati possono variare dalla meravigliosa forma d'arte ai controversi falsi profondi, eppure ogni giorno superano gli umani con un compito. Pertanto, dovremmo anche considerare l'etica e gli impatti dell'IA mentre lavoriamo sodo per costruire un modello di rete neurale efficiente. Tempo per un'infografica accurata sulle reti neurali.
Articoli consigliati
Questa è una guida alla classificazione della rete neurale. Qui abbiamo discusso i diversi tipi di reti neurali di base. Puoi anche consultare i nostri articoli per saperne di più-
- Che cosa sono le reti neurali?
- Algoritmi di rete neurale
- Strumenti di scansione in rete
- Reti neurali ricorrenti (RNN)
- Top 6 Confronti tra CNN vs RNN