
Definizione di Algoritmo di spostamento medio
L'algoritmo di spostamento medio rientra nell'ambito dell'apprendimento senza supervisione, classificato come algoritmo di clustering. L'ideologia dell'algoritmo di spostamento medio è che assegna in modo iterativo punti dati ai cluster spostandosi verso il punto che ha il punto di densità più elevato (Modalità). La logica alla base dello spostamento medio si basa sul concetto di stima della densità del kernel indicata come KDE.
Clustering algoritmo di spostamento medio
Una tecnica di apprendimento senza supervisione scoperta da Fukunaga e Hostetler per trovare i cluster:
- Lo spostamento medio è anche noto come algoritmo di ricerca della modalità che assegna i punti dati ai cluster in un modo spostando i punti dati verso la regione ad alta densità. La più alta densità di punti dati è definita come modello nella regione. L'algoritmo Mean Shift ha applicazioni ampiamente utilizzate nel campo della visione artificiale e della segmentazione delle immagini.
- KDE è un metodo per stimare la distribuzione dei punti dati. Funziona posizionando un kernel su ciascun punto dati. Il kernel in termini matematici è una funzione di ponderazione che applicherà pesi per singoli punti dati. L'aggiunta di tutto il singolo kernel genera la probabilità.
La funzione kernel è richiesta per soddisfare le seguenti condizioni:
- Il primo requisito è garantire che la stima della densità del kernel sia normalizzata.
- Il secondo requisito è che KDE sia ben associato alla simmetria dello spazio.
Due funzioni popolari del kernel
Di seguito sono riportate le due funzioni del kernel popolari utilizzate in esso:
- Kernel piatto
- Kernel Gaussiano
- In base al parametro Kernel utilizzato, la funzione di densità risultante varia. Se non viene menzionato alcun parametro del kernel, il kernel gaussiano viene richiamato per impostazione predefinita. KDE utilizza il concetto di funzione di densità di probabilità che aiuta a trovare i massimi locali della distribuzione dei dati. L'algoritmo funziona facendo in modo che i punti dati si attraggano l'un l'altro consentendo ai punti dati verso l'area di alta densità.
- I punti dati che tentano di convergere verso i massimi locali saranno dello stesso gruppo di cluster. Contrariamente all'algoritmo di clustering K-Means, l'output dell'algoritmo di spostamento medio non dipende da ipotesi sulla forma del punto dati e dal numero di cluster. Il numero di cluster sarà determinato dall'algoritmo rispetto ai dati.
- Per eseguire l'implementazione dell'algoritmo Mean Shift, utilizziamo il pacchetto python SKlearn.
Implementazione dell'algoritmo di spostamento medio
Di seguito è l'implementazione dell'algoritmo:
Esempio 1
Basato sul tutorial di Sklearn per l'algoritmo di clustering a spostamento medio. Il primo frammento implementerà un algoritmo di spostamento medio per trovare i cluster del set di dati bidimensionali. Pacchetti utilizzati per implementare l'algoritmo di spostamento medio.
Codice:
fromcluster importMeanShift, estimate_bandwidth
from sklearn.datasets.samples_generator import make_blobs as mb
importpyplot as plt
fromitertools import cycle as cy
Una cosa fondamentale da notare è che useremo la libreria make_blobs di sklearn per generare punti dati centrati su 3 posizioni. Per applicare l'algoritmo di spostamento medio ai punti generati, dobbiamo impostare la larghezza di banda che rappresenta l'interazione tra la lunghezza. Sklearn's Library ha funzioni integrate per stimare la larghezza di banda.
Codice:
#Sample data points
cen = ((1, .75), (-.75, -1), (1, -1)) x_train, _ = mb(n_samples=10000, centers= cen, cluster_std=0.6)
# Bandwidth estimation using in-built function
est_bandwidth = estimate_bandwidth(x_train, quantile=.1,
n_samples=500)
mean_shift = MeanShift(bandwidth= est_bandwidth, bin_seeding=True)
fit(x_train)
ms_labels = mean_shift.labels_
c_centers = ms_labels.cluster_centers_
n_clusters_ = ms_labels.max()+1
# Plot result
figure(1)
clf()
colors = cy('bgrcmykbgrcmykbgrcmykbgrcmyk')
fori, each inzip(range(n_clusters_), colors):
my_members = labels == i
cluster_center = c_centers(k) plot(x_train(my_members, 0), x_train(my_members, 1), each + '.')
plot(cluster_center(0), cluster_center(1),
'o', markerfacecolor=each,
markeredgecolor='k', markersize=14)
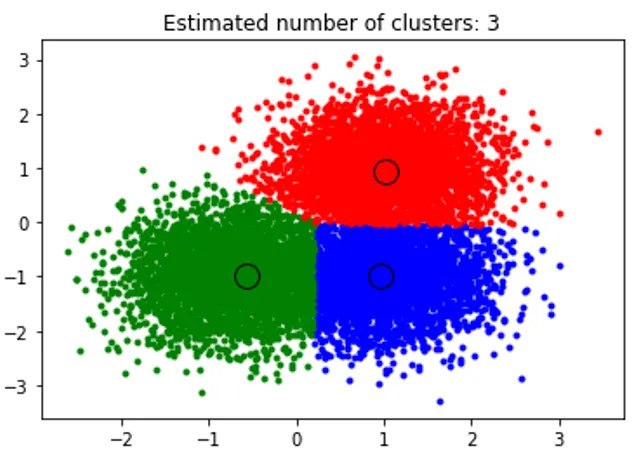
title('Estimated cluster numbers: %d'% n_clusters_)
show()
Lo snippet precedente esegue il clustering e l'algoritmo ha trovato i cluster centrati su ciascun BLOB che abbiamo generato. Possiamo vedere che dall'immagine seguente tracciata dallo snippet mostra l'algoritmo di spostamento medio in grado di identificare il numero di cluster necessari in fase di esecuzione e capire la larghezza di banda appropriata per rappresentare la lunghezza dell'interazione.
Produzione:
Esempio n. 2
Basato sulla segmentazione delle immagini in Computer Vision. Il secondo frammento esplorerà come l'algoritmo di spostamento medio ha usato in Deep Learning per eseguire la segmentazione dell'immagine colorata. Stiamo usando l'algoritmo di spostamento medio per identificare i cluster spaziali. Il frammento precedente abbiamo usato un set di dati 2D mentre in questo esempio esploreremo lo spazio 3D. Il pixel dell'immagine verrà trattato come punti dati (r, g, b). Dobbiamo convertire l'immagine in formato array in modo che ogni pixel rappresenti il punto dati nell'immagine che stiamo andando al segmento. Il raggruppamento dei valori di colore nello spazio restituisce una serie di cluster, in cui i pixel nel cluster saranno simili allo spazio RGB. Pacchetti utilizzati per implementare l'algoritmo di spostamento medio:
Codice:
importnumpy as np
fromcluster importMeanShift, estimate_bandwidth
fromdatasets.samples_generator importmake_blobs
importpyplot as plt
fromitertools import cycle
fromPIL import Image
Sotto lo snippet per eseguire la segmentazione dell'immagine originale:
#Segmentation of Color Image
img = Image.open('Sample.jpg.webp')
img = np.array(img)
#Need to convert image into feature array based
flatten_img=np.reshape(img, (-1, 3))
#bandwidth estimation
est_bandwidth = estimate_bandwidth(flatten_img,
quantile=.2, n_samples=500)
mean_shift = MeanShift(est_bandwidth, bin_seeding=True)
fit(flatten_img)
labels= mean_shift.labels_
# Plot image vs segmented image
figure(2)
subplot(1, 1, 1)
imshow(img)
axis('off')
subplot(1, 1, 2)
imshow(np.reshape(labels, (854, 1224)))
axis('off')
L'immagine generata afferma che questo approccio per identificare le forme delle immagini e determinare i cluster spaziali può essere fatto efficacemente senza alcuna elaborazione dell'immagine.
Produzione:


Vantaggi e applicazioni Mean Shift Algorithm
Di seguito sono riportati i vantaggi e l'applicazione dell'algoritmo medio:
- È ampiamente utilizzato per risolvere la visione artificiale, dove viene utilizzato per la segmentazione delle immagini.
- Clustering dei punti dati in tempo reale senza menzionare il numero di cluster.
- Funziona bene con la segmentazione delle immagini e il tracciamento video.
- Più robusto per i valori anomali.
Pro di Mean Shift Algorithm
Di seguito sono riportati l'algoritmo di spostamento dei pro:
- L'output dell'algoritmo è indipendente dalle inizializzazioni.
- La procedura è efficace in quanto ha un solo parametro: la larghezza di banda.
- Nessuna ipotesi sul numero di cluster di dati e sulla forma.
- Ha prestazioni migliori rispetto a K-Means Clustering.
Contro dell'algoritmo di spostamento medio
Di seguito sono riportati i contro dell'algoritmo di spostamento medio:
- Costoso per funzionalità di grandi dimensioni.
- Rispetto al clustering di K-Means è molto lento.
- L'output dell'algoritmo dipende dalla larghezza di banda del parametro.
- L'output dipende dalla dimensione della finestra.
Conclusione
Sebbene si tratti di un approccio semplice, utilizzato principalmente per risolvere problemi legati alla segmentazione delle immagini, al clustering. È relativamente più lento di K-Means ed è costoso dal punto di vista computazionale.
Articoli consigliati
Questa è una guida all'algoritmo di spostamento medio. Qui discutiamo dei problemi relativi alla segmentazione delle immagini, al clustering, ai vantaggi e alle due funzioni del kernel. Puoi anche consultare i nostri altri articoli correlati per saperne di più-
- K: significa algoritmo di clustering
- Algoritmo KNN in R
- Cos'è l'algoritmo genetico?
- Metodi del kernel
- Metodi del kernel in Machine Learning
- Spiegazione dettagliata dell'algoritmo C ++