

Che cos'è l'algoritmo MapReduce?
MapReduce Algorithm si ispira principalmente al modello di programmazione funzionale. Viene utilizzato per l'elaborazione e la generazione di big data. Questi set di dati possono essere eseguiti contemporaneamente e distribuiti in un cluster. Un programma MapReduce consiste principalmente nella procedura della mappa e in un metodo di riduzione per eseguire l'operazione di riepilogo come il conteggio o la produzione di alcuni risultati. Il sistema MapReduce funziona su server distribuiti che funzionano in parallelo e gestiscono tutte le comunicazioni tra sistemi diversi. Il modello è una strategia speciale di strategia split-applica-combina che aiuta nell'analisi dei dati. Il mapping viene eseguito dalla classe Mapper e riduce l'attività viene eseguita dalla classe Reducer.
Comprensione di MapReduce Algorithm
MapReduce Algorithm funziona principalmente in tre fasi:
- Funzione mappa
- Funzione Shuffle
- Ridurre la funzione
Discutiamo ogni funzione e le sue responsabilità.
1. Funzione mappa
Questo è il primo passo dell'algoritmo MapReduce. Prende i set di dati e li distribuisce in attività secondarie più piccole. Ciò viene ulteriormente eseguito in due passaggi, suddivisione e mappatura. La divisione prende il set di dati di input e divide il set di dati mentre il mapping prende quei sottoinsiemi di dati ed esegue l'azione richiesta. L'output di questa funzione è una coppia chiave-valore.
2. Funzione Shuffle
Questo è anche noto come funzione Combina e include l'unione e l'ordinamento. L'unione combina tutte le coppie chiave-valore. Tutti questi avranno gli stessi tasti. L'ordinamento prende l'input dal passaggio di fusione e ordina tutte le coppie chiave-valore usando le chiavi. Questo passaggio tornerà anche alle coppie chiave-valore. L'output verrà ordinato.
3. Ridurre la funzione
Questo è l'ultimo passaggio di questo algoritmo. Prende le coppie chiave-valore dallo shuffle e riduce l'operazione.
In che modo gli algoritmi MapReduce semplificano il lavoro?
I sistemi di database relazionali dispongono di un server centralizzato che consente di archiviare ed elaborare i dati. Questi erano di solito sistemi centralizzati. Quando compaiono più file nell'immagine l'elaborazione è noiosa e crea un collo di bottiglia durante l'elaborazione di più file. MapReduce mappa l'insieme di dati e converte l'insieme di dati in cui tutti i dati sono divisi in tuple e l'attività di riduzione prenderà l'output da questo passaggio e combinerà queste tuple di dati in insiemi più piccoli. Funziona in diverse fasi e crea coppie chiave-valore che possono essere distribuite su sistemi diversi.
Cosa puoi fare con MapReduce Algorithms?
MapReduce può essere utilizzato con una varietà di applicazioni. Può essere utilizzato per la ricerca basata su modelli distribuiti, l'ordinamento distribuito, l'inversione dei grafici del collegamento Web, le statistiche del registro di accesso al Web. Può anche aiutare a creare e lavorare su più cluster, griglie desktop, ambienti informatici volontari. Si possono anche creare ambienti cloud dinamici, ambienti mobili e anche ambienti di elaborazione ad alte prestazioni. Google ha utilizzato MapReduce che rigenera Google Index del World Wide Web. Usandolo vengono aggiornati i vecchi programmi ad hoc e hanno eseguito diversi tipi di analisi. Ha inoltre integrato i risultati della ricerca live senza ricostruire l'indice completo. Tutti gli input e gli output sono memorizzati nel file system distribuito. I dati temporanei vengono archiviati su un disco locale.
Lavorare con MapReduce Algorithm
Per lavorare con MapReduce Algorithm, devi conoscere l'intero processo di funzionamento. I dati ingeriti vengono sottoposti ai seguenti passaggi:
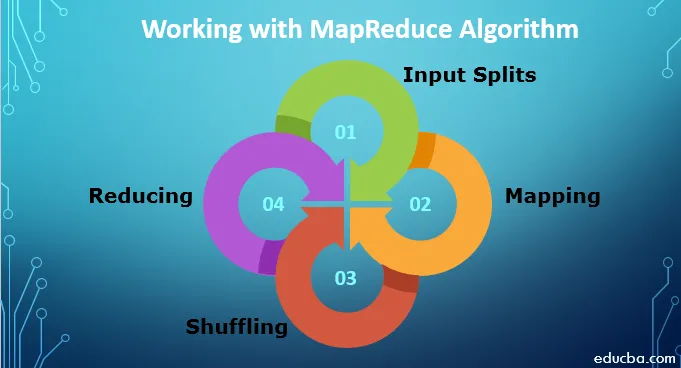
1. Divisioni di input: tutti i dati di input relativi al processo MapReduce sono divisi in parti uguali note come suddivisioni di input. È un blocco di input che può essere utilizzato da qualsiasi mappatore.
2. Mappatura: una volta suddivisi in blocchi, i dati passano attraverso la fase di mappatura nel programma di riduzione delle mappe. Questi dati suddivisi vengono passati alla funzione di mappatura che produce valori di output diversi.
3. Riproduzione casuale: una volta eseguita la mappatura, i dati vengono inviati a questa fase. Il suo compito è riunire i record richiesti dalla fase precedente.
4. Riduzione: in questa fase, l'output della fase di shuffle è aggregato. In questa fase, tutti i valori vengono mescolati e riuniti per aggregazione in modo da restituire un singolo valore di output. Crea un riepilogo del set di dati completo.
Vantaggi dell'algoritmo MapReduce
Le applicazioni che utilizzano MapReduce presentano i seguenti vantaggi:
- Sono stati dotati di convergenza e buone prestazioni di generalizzazione.
- I dati possono essere gestiti utilizzando applicazioni ad alta intensità di dati.
- Offre un'alta scalabilità.
- Contare ogni ricorrenza di ogni parola è facile e ha una vasta raccolta di documenti.
- Uno strumento generico può essere utilizzato per cercare strumenti in molte analisi dei dati.
- Offre tempo di bilanciamento del carico in cluster di grandi dimensioni.
- Aiuta anche nel processo di estrazione di contesti di posizione dell'utente, situazioni, ecc.
- Può accedere rapidamente a grandi campioni di intervistati.
Perché dovremmo usare l'algoritmo MapReduce?
MapReduce è un'applicazione utilizzata per l'elaborazione di enormi set di dati. Questi set di dati possono essere elaborati in parallelo. MapReduce può potenzialmente creare grandi set di dati e un gran numero di nodi. Questi set di dati di grandi dimensioni sono archiviati su HDFS, il che semplifica l'analisi dei dati. Può elaborare qualsiasi tipo di dati come strutturato, non strutturato o semi-strutturato.
Perché abbiamo bisogno dell'algoritmo MapReduce?
MapReduce sta crescendo rapidamente e aiuta nel calcolo parallelo. Aiuta a determinare il prezzo dei prodotti e aiuta a ottenere i profitti più alti. Aiuta anche a prevedere e raccomandare l'analisi. Consente ai programmatori di eseguire modelli su diversi set di dati e utilizza tecniche statistiche avanzate e tecniche di apprendimento automatico che aiutano a prevedere i dati. Filtra e invia i dati a diversi nodi all'interno del cluster e funziona secondo la funzione di mappatore e riduttore.
In che modo questa tecnologia ti aiuterà nella crescita della carriera?
Oggi Hadoop è tra i lavori più ricercati. Sta accelerando il tasso e l'opportunità che sta crescendo molto rapidamente in questo campo. Ci sarà ancora un boom in quest'area. I professionisti IT che lavorano in Java hanno un vantaggio in quanto sono le persone più ricercate. Inoltre, sviluppatori, architetti di dati, data warehouse e professionisti della BI possono togliere enormi quantità di stipendio imparando questa tecnologia.
Conclusione
MapReduce è la base del framework Hadoop. Imparando questo, entrerai sicuramente nel mercato dell'analisi dei dati. Puoi impararlo a fondo e conoscere come vengono elaborati grandi gruppi di dati e in che modo questa tecnologia sta cambiando con l'elaborazione e l'archiviazione dei dati.
Articoli consigliati
Questa è una guida per MapReduce Algorithms. Qui discutiamo il concetto, la comprensione, il lavoro, le necessità, i vantaggi e la crescita della carriera. Puoi anche consultare i nostri altri articoli suggeriti per saperne di più -
- Domande di intervista su MapReduce
- Che cos'è MapReduce in Hadoop?
- Come funziona MapReduce?
- Che cos'è MapReduce?
- Differenze tra Hadoop vs MapReduce
- Diverse operazioni relative alle tuple