

Differenze tra Sqoop e Flume
Sqoop è un prodotto del software Apache. Sqoop estrae informazioni utili da Hadoop e quindi passa agli archivi dati esterni. Con l'aiuto di Sqoop, possiamo importare dati da un RDBMS o mainframe in HDFS. Flume proviene anche dal software Apache. Raccoglie e sposta i dati ricorsivi che vengono generati. Apache Flume non si limita solo a registrare l'aggregazione dei dati, ma le origini dati sono personalizzabili e quindi Flume può essere utilizzato per trasportare enormi quantità di dati. Il modo migliore per raccogliere, aggregare e spostare grandi quantità di dati tra il file system distribuito Hadoop e RDBMS è tramite strumenti come Sqoop o Flume.
Discutiamo questi due strumenti comunemente usati per lo scopo sopra menzionato.
Cos'è Sqoop
Per usare Sqoop, un utente deve specificare lo strumento che l'utente desidera utilizzare e gli argomenti che controllano quel particolare strumento. È inoltre possibile esportare nuovamente i dati in un RDBMS utilizzando Sqoop. La funzionalità di esportazione di Sqoop viene utilizzata per estrarre informazioni utili da Hadoop ed esportarle negli archivi di dati strutturati esterni. Funziona con diversi database come Teradata, MySQL, Oracle, HSQLDB.
- Architettura Sqoop: -
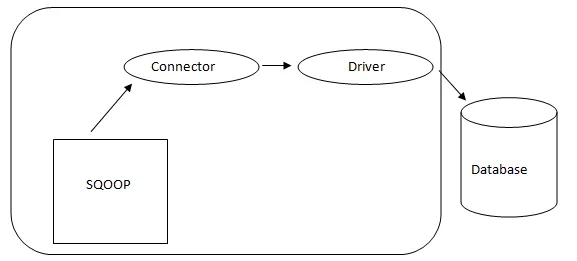
Architettura di Sqoop
Il connettore in uno Sqoop è un plug-in per una particolare fonte di database, quindi è fondamentale che sia un pezzo di stabilimento Sqoop. Nonostante il fatto che i driver siano pezzi specifici del database e distribuiti da vari fornitori di database, Sqoop stesso viene fornito in bundle con diversi tipi di connettori utilizzati per il sistema di database e di deposito delle informazioni prevalente. Pertanto, Sqoop viene fornito con una varietà mista di connettori già pronti all'uso. Sqoop fornisce un componente collegabile per una rete ideale e un sistema esterno. L'API Sqoop offre una struttura utile per l'assemblaggio di nuovi connettori e quindi tutti i connettori del database possono essere inseriti nell'installazione di Sqoop per fornire connettività a diversi sistemi di dati.
Cos'è Flume
Apache Flume non si limita solo a registrare l'aggregazione dei dati, ma le origini dei dati sono personalizzabili e quindi Flume può essere utilizzato per trasportare enormi quantità di dati, inclusi ma non limitati a messaggi e-mail, dati generati dai social media, dati sul traffico di rete e praticamente qualsiasi fonte di dati possibile.
Architettura Flume: - L' architettura Flume si basa su molti concetti fondamentali:
- Flume Event : è rappresentato come unità di flusso di dati, che ha un payload di byte e un set di stringhe con intestazioni di stringa opzionali. Flume considera un evento solo un generico BLOB di byte.
- Flume Agent : è un processo JVM che ospita componenti come canali, sink e origini. Ha il potenziale per ricevere, archiviare e inoltrare gli eventi da una fonte esterna al livello successivo.
- Flume Flow : è il momento in cui l'evento viene generato.
- Flume Client: si riferisce all'interfaccia in cui il client opera nel punto di origine dell'evento e lo consegna all'agente Flume.
- Sorgente: una sorgente consuma eventi con un formato specifico e li consegna tramite un meccanismo specifico.
- Canale : è un negozio passivo in cui si svolgono gli eventi fino a quando il sink non lo rimuove per ulteriore trasporto.
- Sink: rimuove l'evento da un canale e lo inserisce in un repository esterno come HDFS. Attualmente supporta la creazione di file di testo e di sequenza e supporta la compressione in entrambi i tipi di file.
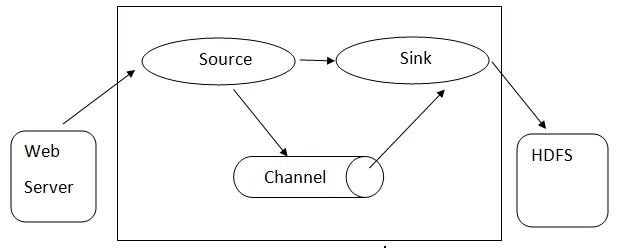
Architettura di Flume
Confronto testa a testa tra Sqoop vs Flume (infografica)
Di seguito è riportato il top 7 confronto tra Sqoop vs Flume

Differenze chiave tra Sqoop e Flume
Ora sappiamo che ci sono molte differenze tra Sqoop vs Flume, qui ci sono le differenze più importanti tra loro indicate di seguito -
1. Sqoop è progettato per scambiare informazioni di massa tra Hadoop e Database relazionale.
Considerando che, Flume è usato per raccogliere dati da diverse fonti che stanno generando dati riguardanti un particolare caso d'uso e quindi trasferendo questa grande quantità di dati da risorse distribuite a un unico repository centralizzato.
2. Sqoop include anche una serie di comandi che consentono di ispezionare il database con cui si sta lavorando. Quindi possiamo considerare Sqoop come una raccolta di strumenti correlati.
Durante la raccolta della data Flume ridimensiona i dati in orizzontale e più agenti Flume possono essere messi in azione per raccogliere la data e aggregarli. Successivamente i log di dati vengono spostati in un archivio dati centralizzato, ad esempio Hadoop Distributed File System (HDFS).
3. Il fattore chiave per l'utilizzo di Flume è che i dati devono essere generati in modo continuo e in streaming. Allo stesso modo, Sqoop è il più adatto in situazioni in cui i tuoi dati vivono in sistemi di database come MySQL, Oracle, Teradata, PostgreSQL
Sqoop vs Flume (tabella di confronto)
| Base per il confronto | Sqoop | FLUME |
|
Natura di base | Sqoop funziona bene con qualsiasi RDBMS che abbia JDBC (Java Database Connectivity) come Oracle, MySQL, Teradata, ecc. | Flume funziona bene per l'origine dati Streaming che genera continuamente come registri, JMS, directory, rapporti sugli arresti anomali, ecc. |
| Flusso di dati | Sqoop utilizzato specificamente per il trasferimento di dati parallelo. Per questo motivo, l'output potrebbe essere in più file | Flume viene utilizzato per la raccolta e l'aggregazione di dati a causa della sua natura distribuita. |
| Eventi guidati | Sqoop non è guidato da eventi. | Flume è completamente guidato dagli eventi. |
| Architettura | Sqoop segue l'architettura basata su connettore, il che significa connettori, sa come connettersi a una diversa origine dati. | Flume segue un'architettura basata su agenti, in cui il codice in esso scritto è noto come agente responsabile del recupero dei dati. |
| Dove usare | Utilizzato principalmente per copiare i dati più velocemente e quindi utilizzarli per generare risultati analitici. | Generalmente utilizzato per estrarre dati quando le aziende desiderano analizzare modelli, cause alla radice o analisi del sentiment utilizzando log e social media. |
| Prestazione | Riduce i carichi di archiviazione e di elaborazione eccessivi trasferendoli ad altri sistemi e ha prestazioni veloci. | Flume è resistente agli errori, robusto e ha un meccanismo di affidabilità sostenibile per il failover e il ripristino. |
| Cronologia delle versioni | La prima versione di Apache Sqoop è stata lanciata a marzo 2012. L'attuale versione stabile è la 1.4.7 | La prima versione stabile 1.2.0 di Apache Flume è stata lanciata nel giugno 2012. L'attuale versione stabile è Apache Flume Versione 1.8.0. |
Conclusione - Sqoop vs Flume
Come hai appreso sopra Sqoop e Flume, sono principalmente due gli strumenti di inserimento dati utilizzati nel mondo dei Big Data. Se devi inserire dati di log testuali in Hadoop / HDFS, Flume è la scelta giusta per farlo. Se i tuoi dati non vengono generati regolarmente, Flume funzionerà comunque, ma sarà eccessivo per quella situazione. Allo stesso modo, Sqoop non è la soluzione migliore per la gestione dei dati basata sugli eventi.
Articoli consigliati
Questa è stata una guida alle differenze tra Sqoop vs Flume, il loro significato, il confronto testa a testa, le differenze chiave, la tabella di confronto e la conclusione. questo articolo comprende tutte le utili differenze tra Sqoop e Flume. Puoi anche consultare i seguenti articoli per saperne di più
- Hadoop vs Teradata - Differenze utili da imparare
- 5 Differenza più importante tra Apache Kafka vs Flume
- Big Data vs Apache Hadoop - I 4 migliori confronti che devi imparare
- 5 Differenza più importante tra Apache Kafka vs Flume
- Importante estrazione del testo vs elaborazione del linguaggio naturale: i 5 migliori confronti