

Che cos'è AWS Kinesis?
Kinesis è una piattaforma che aiuta a raccogliere, elaborare e analizzare i dati di streaming in Amazon Web Services. Lo streaming di dati è una grande quantità di dati generati da diverse fonti come social media, sensori IoT, previsioni meteorologiche, assistenza sanitaria, ecc. Vengono utilizzati per la creazione di applicazioni in base alle esigenze dell'utente. Alcune delle applicazioni più comuni includono analisi predittive in Big Data, Machine Learning, ecc. In questo argomento, impareremo a conoscere AWS Kinesis.
AWS Kinesis Services
Prima di passare ai servizi, comprendiamo innanzitutto alcune terminologie utilizzate in Kinesis.
Terminologia
| Termine | Definizione |
| Record di dati | Unità di dati memorizzata nel flusso di dati di Kinesis. È costituito da BLOB di dati, numero di sequenza e una chiave di partizione |
| Coccio | Insieme della sequenza di set di dati. Il numero di frammenti può essere aumentato o diminuito se si aumenta la velocità dei dati. |
| Periodo di conservazione | Il periodo di tempo in cui è possibile accedere ai dati dopo averli aggiunti allo stream.
Periodo di conservazione predefinito: 24 ore |
| Produttore | Collega i record di dati in Kinesis Stream |
| Consumatore | Ottiene i record da Kinesis Stream e li elabora. |
Kinesis fornisce 3 servizi principali. Loro sono:
1. Kinesis Streams
Kinesis Stream è costituito da una serie di sequenze di record di dati noti come Shards. Questi frammenti hanno una capacità fissa che può fornire una velocità di lettura massima di 2 MB / secondo e una velocità di scrittura di 1 MB / secondo. La capacità massima di un flusso è la somma della capacità di ciascun frammento.
Lavorazione di Kinesis:
- I dati prodotti dall'IoT e da altre fonti conosciute come Produttori vengono immessi nei flussi Kinesis per essere archiviati nei frammenti.
- Questi dati saranno disponibili in Shard per un massimo di 24 ore.
- Se deve essere conservato per un periodo di tempo superiore a quello predefinito, l'utente può aumentare fino a un periodo di conservazione di 7 giorni.
- Una volta che i dati raggiungono i frammenti, le istanze EC2 possono prendere questi dati per scopi diversi.
- Le istanze EC2 che recuperano i dati sono note come consumatori.
- Dopo l'elaborazione dei dati, vengono inseriti in uno dei servizi Web di Amazon come Simple Storage Service (S3), DynamoDB, Redshift, ecc.
2. Kinesis Firehose
Kinesis Firehose è utile per spostare dati su servizi Web di Amazon come Redshift, servizio di archiviazione semplice, ricerca elastica, ecc. Fa parte della piattaforma di streaming che non gestisce alcuna risorsa. I produttori di dati sono configurati in modo tale che i dati debbano essere inviati a Kinesis Firehose e quindi li inviano automaticamente alla destinazione corrispondente.
Lavorazione di Kinesis Firehose:
- Come menzionato nel funzionamento di AWS Kinesis Streams, Kinesis Firehose ottiene anche dati da produttori come telefoni cellulari, laptop, EC2, ecc. Ma questo non deve prendere i dati in frammenti o aumentare i periodi di conservazione come Kinesis Streams. È perché Kinesis Firehose lo fa automaticamente.
- I dati vengono quindi analizzati automaticamente e inseriti in Simple Storage Service
- Poiché non esiste un periodo di conservazione, i dati devono essere analizzati o inviati a qualsiasi archivio dipende dalle esigenze dell'utente.
- Se i dati devono essere inviati a Redshift, devono prima essere spostati in Simple Storage Service e devono essere copiati su Redshift da lì.
- Ma, nel caso di Elastic Search, i dati possono essere inseriti direttamente in esso in modo simile al servizio di archiviazione semplice.
3. Kinesis Analytics
Kinesis Firehose consente di eseguire le query SQL nei dati presenti in Kinesis Firehose. Utilizzando queste query SQL, i dati possono essere archiviati in Redshift, Simple Storage Service, ElasticSearch, ecc.
AWS Kinesis Architecture
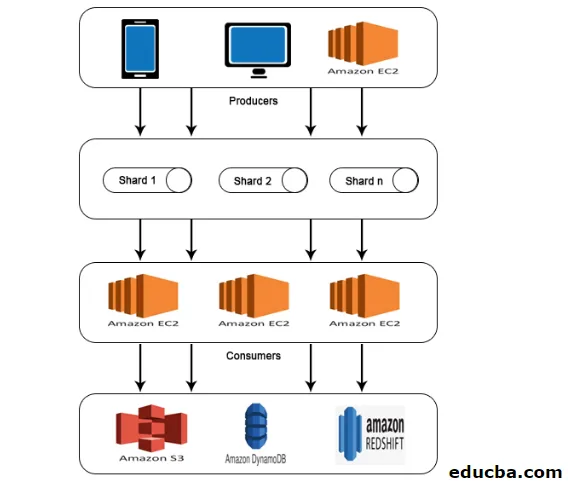
AWS Kinesis Architecture è composta da
- I produttori
- Frammenti
- I consumatori
- Conservazione
Analogamente al lavoro spiegato in AWS Kinesis Data Stream, i dati dei produttori vengono immessi in frammenti dove i dati vengono elaborati e analizzati. I dati analizzati vengono quindi spostati nelle istanze EC2 per l'esecuzione di determinate applicazioni. Alla fine, i dati verranno archiviati in uno qualsiasi dei servizi Web di Amazon come S3, Redshift, ecc.
Come usare la kinesis AWS?
Per lavorare con AWS Kinesis, è necessario eseguire i due passaggi seguenti.
1. Installare l'interfaccia della riga di comando (CLI) di AWS.
L'installazione dell'interfaccia della riga di comando è diversa per i diversi sistemi operativi. Quindi, installa CLI in base al tuo sistema operativo.
Per gli utenti Linux, utilizzare il comando sudo pip install AWS CLI
Assicurati di avere una versione di Python 2.6.5 o successiva. Dopo il download, configuralo utilizzando il comando AWS configure. Quindi, verranno richiesti i seguenti dettagli come mostrato di seguito.
AWS Access Key ID (None): #########################
AWS Secret Access Key (None): #########################
Default region name (None): ##################
Default output format (None): ###########
Per gli utenti Windows, scaricare il programma di installazione MSI appropriato ed eseguirlo.
2. Eseguire le operazioni di Kinesis utilizzando l'interfaccia della riga di comando
I flussi di dati di Kinesis non sono disponibili per il livello gratuito di AWS. Pertanto, verranno addebitati i flussi Kinesis creati.
Ora vediamo alcune operazioni di kinesis nella CLI.
- Crea stream
Crea uno stream KStream con Shard count 2 usando il seguente comando.
aws kinesis create-stream --stream-name KStream --shard-count 2
Controlla se lo stream è stato creato.
aws kinesis describe-stream --stream-name KStream
Se viene creato, verrà visualizzato un output simile al seguente esempio.
(
"StreamDescription": (
"StreamStatus": "ACTIVE",
"StreamName": " KStream ",
"StreamARN": ####################,
"Shards": (
(
"ShardId": #################,
"HashKeyRange": (
"EndingHashKey": ###################,
"StartingHashKey": "0"
),
"SequenceNumberRange": (
"StartingSequenceNumber": "###################"
)
)
) )
)
- Metti record
Ora, un record di dati può essere inserito usando il comando put-record. Qui, un record contenente un test di dati viene inserito nel flusso.
aws kinesis put-record --stream-name KStream --partition-key 456 --data test
Se l'inserimento ha esito positivo, l'output verrà visualizzato come mostrato di seguito.
(
"ShardId": "#############",
"SequenceNumber": "##################"
)
- Ottieni record
Innanzitutto, l'utente deve ottenere l'iteratore del frammento che rappresenta la posizione del flusso per il frammento.
aws kinesis get-shard-iterator --shard-id shardId-########## --shard-iterator-type TRIM_HORIZON --stream-name KStream
Quindi, esegui il comando utilizzando l'iteratore shard ottenuto.
aws kinesis get-records --shard-iterator ###########
Verrà ottenuto un output di esempio come mostrato di seguito.
(
"Records":( (
"Data":"######",
"PartitionKey":"456”,
"ApproximateArrivalTimestamp": 1.441215410867E9,
"SequenceNumber":"##########"
) ),
"MillisBehindLatest":24000,
"NextShardIterator":"#######"
)
- Pulire
Per evitare addebiti, il flusso creato può essere eliminato utilizzando il comando seguente.
aws kinesis delete-stream --stream-name KStream
Conclusione
AWS Kinesis è una piattaforma che raccoglie, elabora e analizza i dati di streaming per diverse applicazioni come l'apprendimento automatico, l'analisi predittiva e così via. I dati di streaming possono essere di qualsiasi formato come audio, video, dati dei sensori, ecc.
Articoli consigliati
Questa è una guida per AWS Kinesis. Qui discutiamo come utilizzare AWS Kinesis e anche il suo servizio con funzionamento e architettura. Puoi anche leggere il seguente articolo per saperne di più -
- Architettura AWS
- Che cos'è AWS Lambda?
- Tecnologie per i Big Data
- Architettura di data mining
- Servizi di archiviazione AWS
- Guida ai concorrenti di AWS con funzionalità