
Panoramica della modellazione di regressione lineare
Quando si inizia a conoscere gli algoritmi di Machine Learning, si inizia a conoscere vari modi degli algoritmi ML, ad esempio apprendimento supervisionato, non supervisionato, semi-supervisionato e di rinforzo. In questo articolo, ci occuperemo dell'apprendimento supervisionato e di uno degli algoritmi di base ma potenti: regressione lineare.

Pertanto, l'apprendimento supervisionato è l'apprendimento in cui formiamo la macchina per comprendere la relazione tra i valori di input e output forniti nel set di dati di training e quindi utilizzare lo stesso modello per prevedere i valori di output per il set di dati di test. Quindi, fondamentalmente, se abbiamo l'output o l'etichettatura già forniti nel nostro set di dati di training e siamo sicuri che l'output fornito abbia un senso corrispondente all'input, allora utilizziamo l'apprendimento supervisionato. Gli algoritmi di apprendimento supervisionato sono classificati in Regressione e Classificazione.
Gli algoritmi di regressione vengono utilizzati quando si nota che l'output è una variabile continua mentre gli algoritmi di classificazione vengono utilizzati quando l'output è diviso in sezioni come Pass / Fail, Good / Average / Bad, ecc. Abbiamo vari algoritmi per eseguire la regressione o la classificazione le azioni con l'algoritmo di regressione lineare è l'algoritmo di base in Regressione.
Venendo a questa regressione, prima di entrare nell'algoritmo, lascia che ti dia la base. A scuola, spero che ti ricordi il concetto di equazione di linea. Permettetemi di dare un breve al riguardo. Ti sono stati dati due punti sul piano XY, ad esempio dire (x1, y1) e (x2, y2), dove y1 è l'output di x1 e y2 è l'output di x2, quindi l'equazione della linea che passa attraverso i punti è (y- y1) = m (x-x1) dove m è la pendenza della linea. Ora, dopo aver trovato l'equazione della linea, se ti viene dato un punto dire (x3, y3), allora sarai facilmente in grado di prevedere se il punto si trova sulla linea o la distanza del punto dalla linea. Questa era la regressione di base che avevo fatto a scuola senza nemmeno rendermi conto che avrebbe avuto una così grande importanza nell'apprendimento automatico. Ciò che generalmente facciamo in questo è, provare a identificare la linea o curva dell'equazione che potrebbe adattarsi correttamente all'input e all'output del set di dati del treno e quindi utilizzare la stessa equazione per prevedere il valore di output del set di dati di test. Ciò comporterebbe un valore desiderato continuo.
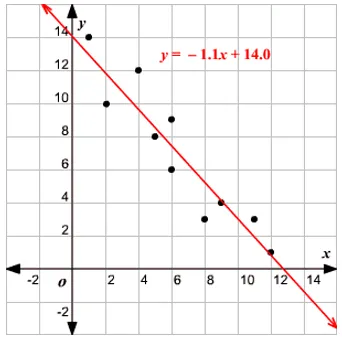
Definizione di regressione lineare
La regressione lineare esiste da molto tempo (circa 200 anni). È un modello lineare, cioè presuppone una relazione lineare tra le variabili di input (x) e una singola variabile di output (y). La y qui viene calcolata dalla combinazione lineare delle variabili di input.
Abbiamo due tipi di regressione lineare
Regressione lineare semplice
Quando esiste una singola variabile di input, ovvero l'equazione di linea è c
considerato come y = mx + c, quindi è Regressione lineare semplice.
Regressione lineare multipla
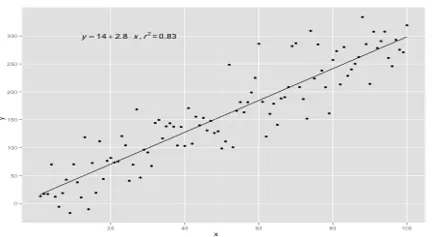
Quando ci sono più variabili di input, cioè l'equazione di linea viene considerata come y = ax 1 + bx 2 +… nx n, allora si tratta della regressione lineare multipla. Varie tecniche sono utilizzate per preparare o addestrare l'equazione di regressione dai dati e la più comune tra loro è chiamata Minimi quadrati ordinari. Il modello creato utilizzando il metodo citato è denominato Regressione lineare dei minimi quadrati ordinari o Regressione dei minimi quadrati. Il modello viene utilizzato quando i valori di input e il valore di output da determinare sono valori numerici. Quando ci sono solo un input e un output, l'equazione formata è un'equazione di linea, ad es
y = B0x+B1
dove i coefficienti della linea devono essere determinati usando metodi statistici.
I modelli di regressione lineare semplice sono molto rari in ML perché generalmente avremo vari fattori di input per determinare il risultato. Quando sono presenti più valori di input e un valore di output, l'equazione formata è quella di un piano o di un iperpiano.
y = ax 1 +bx 2 +…nx n
L'idea principale nel modello di regressione è quella di ottenere un'equazione di linea che si adatti meglio ai dati. La linea più adatta è quella in cui l'errore di previsione totale per tutti i punti dati è considerato il più piccolo possibile. L'errore è la distanza tra il punto sul piano e la linea di regressione.
Esempio
Cominciamo con un esempio di regressione lineare semplice.

La relazione tra altezza e peso di una persona è direttamente proporzionale. È stato condotto uno studio sui volontari per determinare l'altezza e il peso ideale della persona e sono stati registrati i valori. Questo sarà considerato come il nostro set di dati di addestramento. Utilizzando i dati di allenamento, viene calcolata un'equazione della linea di regressione che darà un errore minimo. Questa equazione lineare viene quindi utilizzata per fare previsioni su nuovi dati. Cioè, se diamo l'altezza della persona, allora il peso corrispondente dovrebbe essere previsto dal modello sviluppato da noi con errore minimo o zero.
Y(pred) = b0 + b1*x
I valori b0 e b1 devono essere scelti in modo da minimizzare l'errore. Se la somma dell'errore al quadrato viene presa come metrica per valutare il modello, l'obiettivo è ottenere una linea che riduca al meglio l'errore.
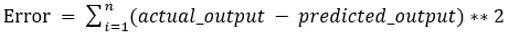
Stiamo eliminando l'errore in modo che i valori positivi e negativi non si annullino a vicenda. Per il modello con un predittore:
Il calcolo dell'intercetta (b0) nell'equazione di linea viene effettuato da:
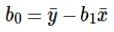
Il calcolo del coefficiente per il valore di input x viene eseguito da:
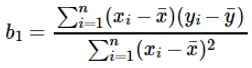
Comprensione del coefficiente b 1 :
- Se b 1 > 0, allora x (input) e y (output) sono direttamente proporzionali. Questo è un aumento di x aumenterà y come aumenti di altezza, aumenti di peso.
- Se b 1 <0, allora x (predittore) e y (target) sono inversamente proporzionali. Cioè un aumento di x diminuirà y come la velocità di un aumento del veicolo, il tempo impiegato diminuisce.
Comprensione del coefficiente b 0 :
- B 0 assume il valore residuo per il modello e garantisce che la previsione non sia distorta. Se non abbiamo un termine B 0, l'equazione di linea (y = B 1 x) viene forzata a passare attraverso l'origine, ovvero i valori di input e output inseriti nel modello risultano in 0. Ma questo non sarà mai il caso, se abbiamo 0 in input, allora B 0 sarà la media di tutti i valori previsti quando x = 0. L'impostazione di tutti i valori del predittore su 0 nel caso di x = 0 comporterà la perdita di dati ed è spesso impossibile.
Oltre ai coefficienti sopra menzionati, questo modello può anche essere calcolato usando equazioni normali. Discuterò ulteriormente l'uso delle equazioni normali e la progettazione di un modello di regressione semplice / multilineare nel mio prossimo articolo.
Articoli consigliati
Questa è una guida alla modellazione della regressione lineare. Qui discutiamo la definizione, i tipi di regressione lineare che include la regressione lineare semplice e multipla insieme ad alcuni esempi. Puoi anche consultare i seguenti articoli per saperne di più–
- Regressione lineare in R
- Regressione lineare in Excel
- Modellazione predittiva
- Come creare GLM in R?
- Confronto tra regressione lineare e regressione logistica