

Introduzione ad Apache Flume
Apache Flume è Data Ingestion Framework che scrive i dati basati su eventi in Hadoop Distributed File System. È noto che Hadoop elabora i big data, si pone la domanda su come i dati generati da diversi server Web vengono trasmessi al file system Hadoop? La risposta è Apache Flume. Flume è progettato per l'immissione di dati ad alto volume su Hadoop di dati basati su eventi.
Considerare uno scenario in cui il numero di server Web genera file di registro e questi file di registro devono essere trasmessi al file system Hadoop. Flume raccoglie quei file come eventi e li ingerisce su Hadoop. Sebbene Flume sia usato per trasmettere a Hadoop, non esiste una regola rigida secondo cui la destinazione deve essere Hadoop. Flume è in grado di scrivere su altri Frameworks come Hbase o Solr.
Architettura Flume
In generale l'architettura Apache Flume è composta dai seguenti componenti:
- Fonte Flume
- Canale Flume
- Lavello Flume
- Agente Flume
- Evento Flume
Diamo una breve occhiata a ciascun componente Flume
1. Fonte del canale
Una fonte Flume è presente su generatori di dati come Face book o Twitter. Source raccoglie i dati dal generatore e li trasferisce a Flume Channel sotto forma di Flume Events. Flume supporta vari tipi di fonti come Avro Flume Source: si collega alla porta Avro e riceve eventi dal client esterno Avro, Thrift Flume Source: si collega alla porta Thrift e riceve eventi da flussi di client Thrift esterni, Spooling Directory Source e Kafka Flume Source.
2. Canale Flume
Un negozio intermedio che memorizza nel buffer gli eventi inviati da Flume Source fino a quando non vengono consumati da Sink è chiamato Flume Channel. Il canale funge da ponte intermedio tra Source e Sink. I canali Flume sono di natura transazionale.
Flume fornisce supporto per il canale File e il canale Memory. Il canale del file è di natura duratura, ciò significa che una volta che i dati vengono scritti nel canale non andranno persi, anche se l'agente si riavvia. In Memoria, gli eventi del canale sono archiviati in memoria, quindi non è durevole ma molto veloce in natura.
3. Lavandino
Un lavandino Flume è presente su repository di dati come HDFS, HBase. Flume sink consuma gli eventi dal canale e li memorizza nei negozi di destinazione come HDFS. Non esiste una regola in base alla quale il sink debba consegnare eventi allo Store, invece, possiamo configurarlo in modo tale che un sink possa consegnare eventi a un altro agente. Flume supporta vari lavandini come HDFS Sink, Hive Sink, Thrift Sink, Avro Sink.
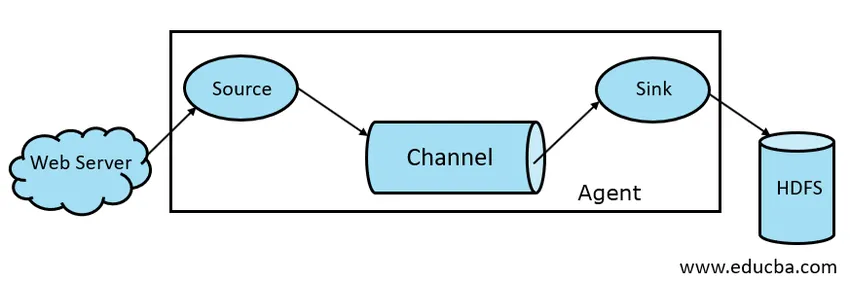
Fig 1.1 Architettura di base del canale
4. Agente dei fumi
Un agente Flume è un processo Java di lunga durata che viene eseguito su Combinazione sorgente - canale - lavandino. Flume può avere più di un agente. Possiamo considerare Flume come una raccolta di agenti Flume collegati che sono distribuiti in natura.
5. Evento Flume
Un evento è l'unità di dati trasportati in Flume . La rappresentazione generale di Data Object in Flume si chiama Event. L'evento è costituito da un payload di un array di byte con intestazioni opzionali.
Lavorazione di Flume
Un agente Flume è un processo Java che consiste di Source - Channel - Sink nella sua forma più semplice. La fonte raccoglie i dati dal generatore di dati sotto forma di eventi e li consegna al canale. Una fonte può consegnare a più canali secondo il requisito. Fan out è il processo in cui una singola fonte scriverà su più canali in modo che possano consegnare a più lavandini.
Un evento è l'unità base dei dati trasmessi in Flume. Il canale memorizza nel buffer i dati fino a quando non vengono inseriti da Sink. Sink raccoglie i dati dal canale e li consegna all'archivio dati centralizzato come HDFS o Sink può inoltrare tali eventi a un altro agente Flume secondo i requisiti.
Flume supporta Transazioni. Al fine di raggiungere l'affidabilità, Flume utilizza Transazioni separate dalla sorgente al canale e dal canale al lavandino. Se gli eventi non vengono consegnati, la transazione viene ripristinata e successivamente riconsegnata.
Per comprendere il funzionamento di Flume, prendiamo un esempio di configurazione di Flume in cui source sta eseguendo lo spooling della directory e sink è Hdfs. In questo esempio, l'agente Flume è nella forma più semplice, ad esempio la topologia single source - channel - sink configurata utilizzando un file delle proprietà java.
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1
agent1.sources.source1.type = spooldir
agent1.sources.source1.spoolDir = /tmp/spooldir
agent1.sinks.sink1.type = hdfs
agent1.sinks.sink1.hdfs.path = /tmp/flume
agent1.channels.channel1.type = file
Nell'esempio di configurazione sopra, l'agente è la base con cui definiamo altre proprietà. source1 e sink1 e channel1 sono rispettivamente i nomi di source, sink e channel e anche i loro tipi e posizioni sono menzionati di conseguenza.
Vantaggi di Apache Flume
- Flume è scalabile, affidabile e tollerante ai guasti. Queste proprietà sono discusse in dettaglio di seguito
- Scalabile: Flume è scalabile in senso orizzontale, ovvero possiamo aggiungere nuovi nodi secondo le nostre esigenze
- Affidabile: Apache Flume supporta le transazioni e garantisce che non vengano persi dati nel processo di trasmissione dei dati. Ha transazioni diverse da sorgente a canale e da canale a sorgente.
- Flume è personalizzabile e fornisce supporto per varie fonti e lavandini come Kafka, Avro, directory di spooling, parsimonia ecc.
- In Flume, la singola fonte può trasmettere dati a più canali e questi canali a loro volta trasmettono i dati a più lavandini, quindi la singola fonte può trasmettere dati a più lavandini. Questo meccanismo si chiama Fan out. Flume supporta anche Fan out.
- Flume fornisce il flusso costante della trasmissione dei dati, ad esempio se aumenta la velocità di lettura dei dati e aumenta anche la velocità di scrittura dei dati.
- Sebbene Flume generalmente scriva i dati su uno storage centralizzato come HDFS o Hbase, possiamo configurare Flume secondo i nostri requisiti in modo tale che Sink possa scrivere i dati su un altro agente. Ciò dimostra la flessibilità di Flume
- Apache Flume è di natura open source.
Conclusione
In questo articolo Flume, i componenti di Flume e il funzionamento di Flume sono discussi in dettaglio. Flume è una piattaforma flessibile, affidabile e scalabile per trasmettere dati a un negozio centralizzato come HDFS. La sua capacità di integrarsi con varie applicazioni come Kafka, Hdfs, Thrift lo rende un'opzione praticabile per l'inserimento di dati.
Articoli consigliati
Questa è stata una guida ad Apache Flume. Qui discutiamo di architettura, funzionamento e vantaggi di Apache Flume. Puoi anche dare un'occhiata ai seguenti articoli per saperne di più -
- Che cos'è Apache Flink?
- Differenza tra Apache Kafka vs Flume
- Architettura dei big data
- Strumenti di Hadoop
- Scopri i diversi eventi JavaScript