
Introduzione al gruppo alveare Di
Raggruppa per come suggerisce il nome raggrupperà il record che soddisfa determinati criteri. In questo articolo, esamineremo il gruppo di HIVE. In RDBMS legacy come MySQL, SQL, ecc., Group by è una delle clausole più vecchie che vengono utilizzate. Ora ha trovato il suo posto in modo simile nell'archiviazione dei dati basata su file nota come HIVE.
Sappiamo che Hive ha superato molti RDBMS legacy nella gestione di enormi dati senza spendere un soldo per i fornitori per mantenere database e server. Dobbiamo solo configurare HDFS per gestire l'hive. Generalmente, passiamo alle tabelle perché l'utente finale può interpretare dalla sua struttura e può interrogare come i file saranno goffi per loro. Ma abbiamo dovuto farlo pagando i fornitori per fornire server e conservare i nostri dati nel formato delle tabelle. Quindi Hive fornisce il meccanismo economico in cui sfrutta i vantaggi dei sistemi basati su file (il modo in cui l'hive salva i suoi dati) nonché le tabelle (struttura della tabella su cui gli utenti finali possono interrogare).
Raggruppare per
Raggruppa per utilizza le colonne definite dalla tabella Hive per raggruppare i dati. Ad esempio, considera di avere una tabella con i dati del censimento di ogni città di tutti gli stati in cui il nome della città e il nome dello stato sono una delle colonne. Ora nella query, se raggruppiamo per stati, tutti i dati provenienti da diverse città di un determinato stato verranno raggruppati insieme e si potranno facilmente visualizzare meglio i dati ora prima dell'applicazione del gruppo.
Sintassi del gruppo Hive Di
La sintassi generale della clausola group by è la seguente:
SELECT (ALL | DISTINCT) select_expr, select_expr, …
FROM table_reference
(WHERE where_condition) (GROUP BY col_list) (HAVING having_condition) (ORDER BY col_list)) (LIMIT number);
o per domande più semplici,
from Group By
Select department, count(*) from the university.college Group By department;
Qui il dipartimento fa riferimento a una delle colonne del tavolo del college che è presente nel database dell'università e il suo valore è vario in dipartimenti come arte, matematica, ingegneria, ecc. Ora vediamo alcuni esempi per dimostrare il gruppo.
Ho creato una tabella di esempio deck_of_cards per dimostrare il gruppo. La sua istruzione create table è la seguente:
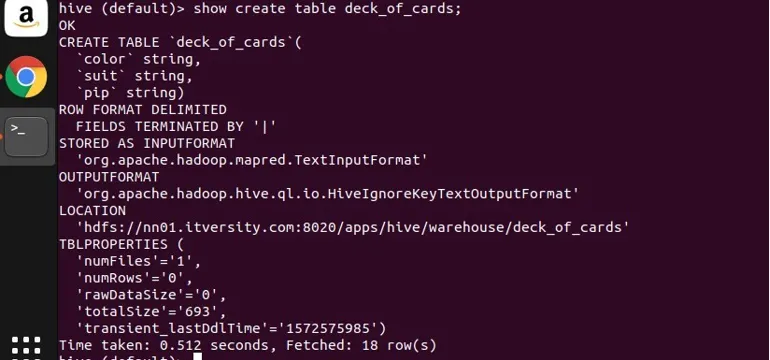
puoi vedere dall'alto che ha tre colonne di stringa di colore, seme e pip. Vorrei scrivere una query per raggruppare i dati in base al colore e ottenere il conteggio.
select color, count(*) from deck_of_cards group by color;
Hive fondamentalmente prende la query sopra per convertirla nel programma di riduzione della mappa generando il codice java e il file jar corrispondenti e quindi esegue. Questo processo può richiedere un po 'di tempo, ma può sicuramente gestire i big data rispetto al tradizionale RDBMS. Vedi lo screenshot seguente con il registro dettagliato per l'esecuzione della query sopra.
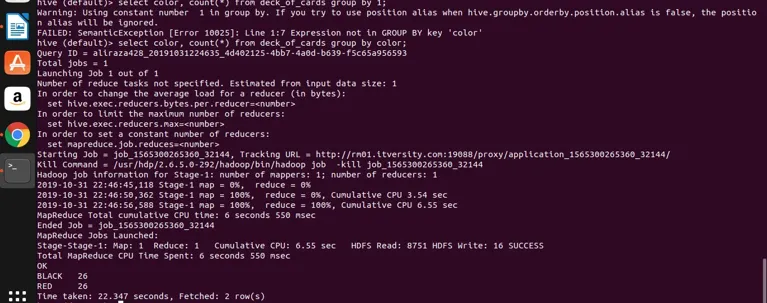
puoi vedere che NERO è 26 e ROSSO è 26.
ora applichiamo il raggruppamento su due colonne (colore e seme e otteniamo il conteggio dei gruppi) e vediamo il risultato di seguito.
Select color, suit, count(*) from deck_of_cards group by color, suit
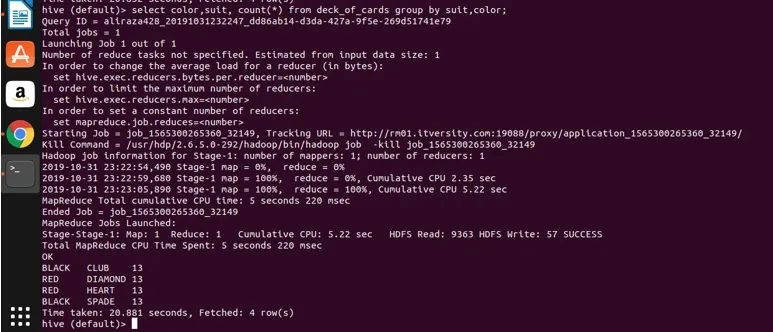
Fondamentalmente, ci sono quattro gruppi distinti sopra Club, Spade che hanno il colore nero e Diamante e il cuore che sono di colore rosso.
Memorizzazione del risultato dal gruppo per causa in un'altra tabella
Hive, come qualsiasi altro RDBMS, offre la funzione di inserire i dati con istruzioni table create. Vediamo come memorizzare il risultato da un'espressione selezionata usando un gruppo in un'altra tabella. Consentitemi di utilizzare la query precedente in cui ho usato due colonne nel gruppo.
create table cards_group_by
as
select color, suit, count(*) from deck_of_cards
group by color, suit;
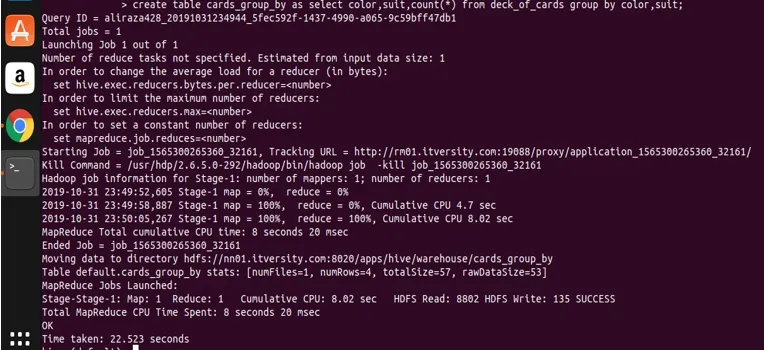
ora cerchiamo di interrogare sulla tabella creata per vedere e validare i dati.

Ora limitiamo il risultato del gruppo usando la clausola have. Come mostrato nella sintassi generica, possiamo applicare una restrizione sul gruppo, usando have. Qui sto usando la tabella ordser_items e la sua struttura è la seguente dalla dichiarazione di descrizione.
hive (retail_db_ali)> describe order_items;
OK
order_item_id int
order_item_order_id int
order_item_product_id int
order_item_quantity tinyint
order_item_subtotal float
order_item_product_price float
Time taken: 0.387 seconds, Fetched: 6 row(s)
select order_item_id, order_item_order_id from order_items group by order_item_id, order_item_order_id having order_item_order_id=5;
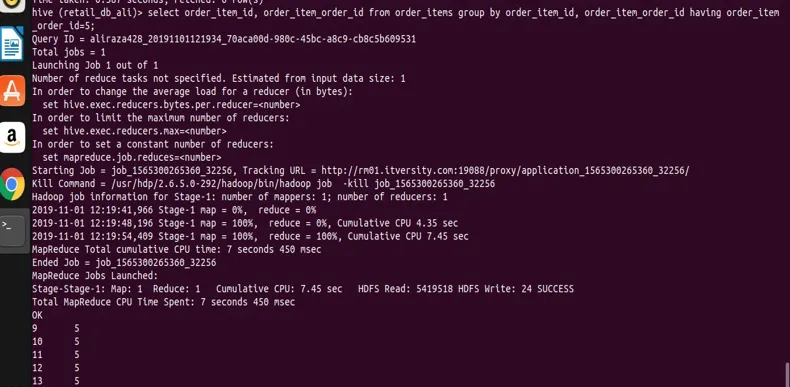
puoi vedere dal risultato lo screenshot che abbiamo registrato solo con il valore order_item_order_id 5.
Raggruppa insieme a Case Statement
Ora diamo un'occhiata a query un po 'complesse che coinvolgono le istruzioni CASE con il gruppo. Lo applicheremo alla tabella order_items. Vedremo di seguito che possiamo classificare le colonne non aggregate sulle quali non possiamo applicare direttamente il gruppo per clausola.
Select
case
when order_item_subtotal <=200 then "less_profit"
when order_item_subtotal <=300 then "avg_prof"
when order_item_subtotal<=500 then "good_prof"
when order_item_subtotal<=550 then "max_profit"
else 'corsed_treshold'
end
as order_profits,
count(*) from order_items
group by
case
when order_item_subtotal <=200 then "less_profit"
when order_item_subtotal <=300 then "avg_prof"
when order_item_subtotal<=500 then "good_prof"
when order_item_subtotal<=550 then "max_profit"
else 'corsed_treshold'
end;
eseguiamolo nell'alveare per risultati
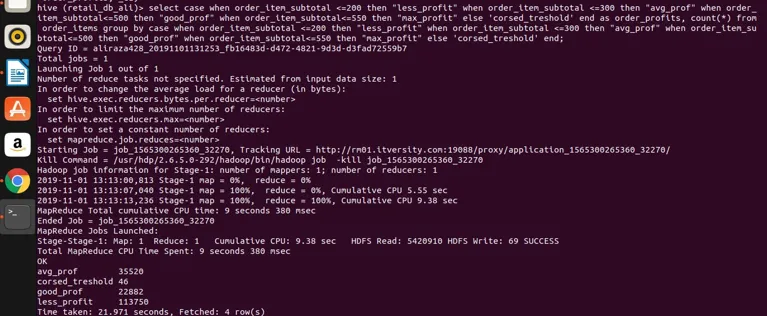
Conclusione - Hive Group Di
quindi possiamo vedere che abbiamo raggruppato order_item_subtotal in quattro diverse categorie (se noti che order_item_subtotal è una colonna non aggregante e non è possibile applicare il gruppo diretto su di esso) e li abbiamo raggruppati insieme e ottenuto anche i loro conteggi per i valori che soddisfano l'intervallo definito nell'espressione select. Qui la semplice regola se la colonna non è aggregata e la nostra espressione select è complessa, qualunque cosa ci sia nell'espressione select che dovrebbe anche essere presente nel gruppo per espressione della clausola. Quindi abbiamo visto come un famoso gruppo di clausole RDBMS può essere applicato anche sull'Hive senza alcuna restrizione. Può essere applicato a semplici espressioni selezionate. Espressioni aggregate e filtranti, espressioni di join e espressioni CASE complesse.
Articoli consigliati
Questa è una guida di Hive Group di. Qui discutiamo il gruppo per, sintassi, esempi del gruppo hive con condizioni e implementazione diverse. Puoi anche consultare i seguenti articoli per saperne di più -
- Si unisce a Hive
- Che cos'è un alveare?
- Hive Architecture
- Funzione alveare
- Hive Order di
- Installazione alveare
- I 6 migliori tipi di join in MySQL con esempi