

Domande e risposte sull'intervista di Splunk - Introduzione
Quindi hai finalmente trovato il lavoro dei tuoi sogni su Splunk ma ti stai chiedendo come rompere l'intervista di Splunk e quali potrebbero essere le probabili domande dell'intervista di Splunk per il 2018. Ogni intervista è diversa e anche l'ambito di un lavoro è diverso. Tenendo presente questo, abbiamo progettato le domande e le risposte dell'intervista Splunk più comuni per il 2018 per aiutarti a ottenere il successo nell'intervista.Di seguito sono riportate le domande e le risposte più utili sull'intervista di Splunk. Queste domande principali sono divise in due parti:
Parte 1 - Domande di intervista su Splunk (di base)
Questa prima parte tratta le domande e le risposte di base dell'intervista Splunk.
1. Che cos'è Splunk? Perché viene utilizzato Splunk per analizzare i dati della macchina?
Risposta:
Uno degli strumenti di analisi più utilizzati è Microsoft Excel e lo svantaggio è che Excel può caricare solo fino a 1048576 righe e che i dati della macchina sono generalmente enormi. Splunk è utile per gestire i dati generati dalla macchina (big data), i dati provenienti da server, dispositivi o reti possono essere facilmente caricati in Splunk e possono essere analizzati per verificare la visibilità, la conformità, la sicurezza delle minacce, ecc. Possono anche essere utilizzati per il monitoraggio dell'applicazione.
2. Spiegare come funziona Splunk
Risposta:
Queste sono le domande più frequenti sull'intervista di Splunk poste in un'intervista. I dati vengono caricati in Splunk utilizzando lo spedizioniere che funge da interfaccia tra l'ambiente Splunk e il mondo esterno, quindi questi dati vengono inoltrati a un indicizzatore in cui i dati vengono archiviati localmente o su un cloud. L'indicizzatore indicizza i dati della macchina e li memorizza nel server. Search Head è la GUI fornita da Splunk per la ricerca e l'analisi (ricerca, visualizzazione, analisi ed esecuzione di varie altre funzioni) dei dati.
Il server di distribuzione gestisce tutti i componenti di Splunk come indicizzatore, forwarder e testina di ricerca in ambiente Splunk. 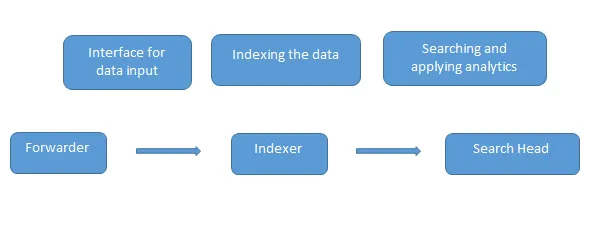
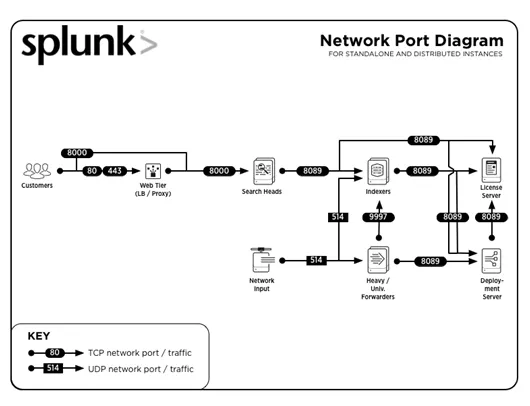
3. Quali sono i numeri di porta comuni utilizzati da Splunk?
Risposta :
I numeri di porte comuni su cui vengono eseguiti i servizi (per impostazione predefinita) sono:
| Servizio | Numero di porta |
| Gestione / API REST | 8089 |
| Testa di ricerca / Indicizzatore | 8000 |
| Testa di ricerca | 8065, 8191 |
| Nodo peer cluster dell'indicizzatore / Membro del cluster head di ricerca | 9887 |
| indicizzatore | 9997 |
| Indicizzatore / spedizioniere | 514 |
Passiamo alle prossime domande dell'intervista su Splunk.
4. Perché usare solo Splunk?
Risposta:
Ci sono molte alternative a Splunk che offrono molta concorrenza ad alcune di esse sono le seguenti:
• ELK / Logstash (open source)
Elasticsearch viene utilizzato per la ricerca è come la testa di ricerca in Splunk, Log stash è per la raccolta di dati che è simile allo spedizioniere utilizzato in Splunk e Kibana viene utilizzato per la visualizzazione dei dati (la testa di ricerca fa lo stesso in Splunk)
• Graylog (open source con versione commerciale)
Graylog è un altro strumento chiamato lo scorso anno con la sua versione 1.0. Simile allo stack ELK, Graylog ha anche diversi componenti che utilizza Elasticsearch come componente principale, ma i dati sono archiviati in Mongo DB e utilizzano Apache Kafka. Ha due versioni una versione core che è disponibile gratuitamente e la versione enterprise che viene fornita con funzioni come l'archiviazione.
• Sumo Logic (servizio cloud)
Quindi, ciò che rende Splunk migliore di tutti è che Splunk viene fornito come un unico pacchetto di raccolta dati, archiviazione e strumento di analisi integrato. Splunk è anche scalabile e fornisce supporto / aiuto professionale per la sua edizione enterprise.
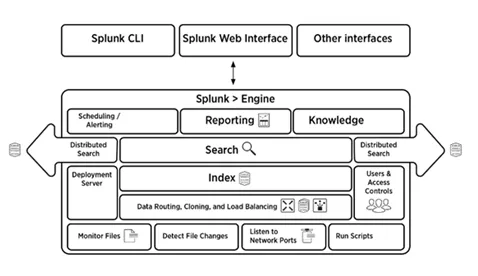
5. Spiegare brevemente l'architettura Splunk
Risposta:
L'immagine seguente offre una breve panoramica dell'architettura Splunk e dei suoi componenti.
Parte 2 - Domande per l'intervista a Splunk (Avanzate)
Diamo ora un'occhiata alle domande avanzate dell'intervista su Splunk.
6. Quali sono i componenti dell'architettura Splunk?
Risposta:
Ci sono quattro componenti nell'architettura Splunk. Loro sono:
- Indicizzatore : indicizza i dati macchina
- Forwarder: inoltra i registri per indicizzarli
- Testa di ricerca: fornisce la GUI per la ricerca
- Server di distribuzione: gestisce i componenti Splunk (indicizzatore, forwarder e testa di ricerca) in un ambiente distribuito
7. Fornisci alcuni casi d'uso di oggetti della conoscenza.
Risposta :
Queste sono le domande frequenti sull'intervista di Splunk in un'intervista. Gli oggetti della conoscenza possono essere utilizzati in molti domini. Alcuni esempi sono:
Monitoraggio delle applicazioni: può essere utilizzato per monitorare le applicazioni in tempo reale con avvisi configurati che avviseranno gli amministratori / utenti in caso di arresto anomalo di un'applicazione.
Sicurezza fisica: in caso di alluvione / vulcanica, ecc., I dati possono essere utilizzati per ricavare spunti se l'organizzazione ha a che fare con tali dati.
Sicurezza di rete: è possibile creare un ambiente sicuro inserendo nella lista nera l'IP di dispositivi sconosciuti, riducendo così le perdite di dati in qualsiasi organizzazione.
Gestione dei dipendenti: l' attrito dei dipendenti è una delle sfide che deve affrontare qualsiasi organizzazione e durante il periodo di preavviso l'attività del dipendente può essere monitorata al fine di proteggere i dati dell'organizzazione monitorando così la loro attività e limitando qualsiasi altro dipendente nel periodo di preavviso a non fare lo stesso .
8. Spiegare il fattore di ricerca (SF) e il fattore di replica (RF)
Risposta:
Queste sono le terminologie utilizzate nelle tecniche di clustering Splunk. Il cluster di indicizzatori è un gruppo appositamente configurato di indicizzatori Splunk Enterprise che replica i dati esterni e viene utilizzato per il ripristino di emergenza.
In termini di ricerca della documentazione Splunk, il fattore può essere descritto come "Il numero di copie ricercabili di dati gestite da un cluster di indicizzatori. Il valore predefinito del fattore di ricerca è 2 ", mentre il fattore di replica è definito come il numero di copie dei dati gestite dal cluster.
Il cluster dell'indicizzatore ha sia un fattore di ricerca che un fattore di replica, mentre il cluster principale di ricerca ha solo un fattore di ricerca
Passiamo alle prossime domande dell'intervista su Splunk.
9. Cosa sono i secchi Splunk? Spiegare il ciclo di vita della benna.
Risposta:
Le directory in cui sono archiviati i dati indicizzati sono note come bucket Splunk e queste contengono eventi di un determinato periodo. Il ciclo di vita del secchio Splunk comprende quattro fasi calde, calde, fredde, congelate e scongelate.
- Caldo : questo bucket contiene i dati indicizzati di recente ed è aperto per la scrittura.
- Caldo : dopo che i dati rientrano nella hot bucket in base alle politiche dei dati, vengono spostati in bucket caldi
- Freddo : la fase successiva dopo il riscaldamento è la fase fredda in cui i dati non possono essere modificati.
- Congelato : per impostazione predefinita l'indicizzatore elimina i dati dai bucket congelati, ma questi possono anche essere archiviati.
- Scongelato : il recupero delle informazioni dai file archiviati (bucket congelato) è noto come scongelamento.
10. Perché dovremmo usare Splunk Alert? Quali sono le diverse opzioni durante l'impostazione degli avvisi?
Risposta:
Lo stato di attenzione per ogni possibile errore è noto come avviso e in Splunk possono verificarsi avvisi di ambiente a causa di errori di connessione o violazioni della sicurezza o violazione di qualsiasi regola creata dall'utente.
Ad esempio, l'invio di notifiche o un rapporto degli utenti che non sono riusciti ad accedere dopo aver utilizzato i loro tre tentativi in un portale all'amministratore dell'applicazione.
Diverse opzioni disponibili durante l'impostazione degli avvisi sono:
- È possibile creare un webhook per scrivere gli avvisi su hipchat o GitHub.
- Aggiungi risultati, .csv o pdf o in linea con il corpo del messaggio in modo che sia possibile identificare la causa principale dell'avviso.
- I biglietti possono essere creati e gli avvisi possono essere limitati da una macchina o un IP.
Articolo raccomandato
Questa è stata una guida all'elenco delle domande e risposte dell'intervista Splunk, in modo che il candidato possa reprimere facilmente queste domande e risposte sull'intervista Splunk. Puoi anche leggere i seguenti articoli per saperne di più -
- Domande sul colloquio di sistema SAS - Le 10 domande più utili
- 10 domande di intervista eccellenti sul tableau che devi conoscere
- 15 domande e risposte sull'intervista Oracle più riuscite
- Domande sul colloquio sulla sicurezza della rete - Principali e più frequenti
- Splunk vs Nagios