
Introduzione ai modelli di apprendimento automatico
Una panoramica di vari modelli di apprendimento automatico utilizzati nella pratica. Seguendo la definizione, un modello di apprendimento automatico è una configurazione matematica ottenuta dopo l'applicazione di metodologie di apprendimento automatico specifiche. Utilizzando l'ampia gamma di API, la creazione di un modello di apprendimento automatico è praticamente semplice al giorno d'oggi con il minor numero di righe di codici. Ma la vera abilità di un professionista della scienza dei dati applicata sta nella scelta del modello corretto basato sull'affermazione del problema e sulla convalida incrociata invece di lanciare i dati su algoritmi elaborati in modo casuale. In questo articolo, discuteremo di vari modelli di apprendimento automatico e di come usarli in modo efficace in base al tipo di problemi che affrontano.
Tipi di modelli di apprendimento automatico
In base al tipo di attività possiamo classificare i modelli di apprendimento automatico nei seguenti tipi:
- Modelli di classificazione
- Modelli di regressione
- Clustering
- Riduzione dimensionale
- Deep Learning ecc.
1) Classificazione
Per quanto riguarda l'apprendimento automatico, la classificazione è il compito di prevedere il tipo o la classe di un oggetto all'interno di un numero finito di opzioni. La variabile di output per la classificazione è sempre una variabile categoriale. Ad esempio, prevedere un'e-mail è spam o meno è un'attività di classificazione binaria standard. Ora annotiamo alcuni importanti modelli per problemi di classificazione.
- Algoritmo dei vicini più vicini a K: semplice ma completo dal punto di vista computazionale.
- Naive Bayes - Basato sul teorema di Bayes.
- Regressione logistica - Modello lineare per la classificazione binaria.
- SVM - può essere utilizzato per classificazioni binarie / multiclasse.
- Albero decisionale - classificatore basato su " Se altro ", più robusto per i valori anomali.
- Ensemble: combinazione di più modelli di apprendimento automatico raggruppati per ottenere risultati migliori.
2) Regressione
Nella macchina, la regressione dell'apprendimento è un insieme di problemi in cui la variabile di output può assumere valori continui. Ad esempio, la previsione del prezzo della compagnia aerea può essere considerata un'attività di regressione standard. Annotiamo alcuni importanti modelli di regressione utilizzati nella pratica.
- Regressione lineare: modello di base più semplice per l'attività di regressione, funziona bene solo quando i dati sono separabili linearmente e se è presente una multicollinearità molto ridotta o assente.
- Regressione lazo - regressione lineare con regolarizzazione L2.
- Regressione della cresta - regressione lineare con regolarizzazione L1.
- Regressione SVM
- Regressione dell'albero decisionale ecc.
3) Clustering
In parole semplici, il clustering è il compito di raggruppare oggetti simili insieme. I modelli di apprendimento automatico aiutano a identificare automaticamente oggetti simili senza intervento manuale. Non possiamo costruire modelli di apprendimento automatico supervisionato efficaci (modelli che devono essere addestrati con dati curati o etichettati manualmente) senza dati omogenei. Il clustering ci aiuta a raggiungere questo obiettivo in modo più intelligente. Di seguito sono riportati alcuni dei modelli di clustering ampiamente utilizzati:
- K significa - Semplice ma soffre di varianza elevata.
- K significa ++ - La versione modificata di K significa.
- K medoidi.
- Cluster agglomerativo: un modello di clustering gerarchico.
- DBSCAN - Algoritmo di clustering basato sulla densità ecc.
4) Riduzione dimensionale
La dimensionalità è il numero di variabili predittive utilizzate per prevedere la variabile indipendente o target. Spesso nei set di dati del mondo reale il numero di variabili è troppo elevato. Troppe variabili portano anche la maledizione del sovradimensionamento dei modelli. In pratica tra questi grandi numeri di variabili, non tutte le variabili contribuiscono ugualmente all'obiettivo e in un gran numero di casi, possiamo effettivamente preservare le variazioni con un numero minore di variabili. Elenchiamo alcuni modelli comunemente usati per la riduzione della dimensionalità.
- PCA: crea un numero minore di nuove variabili da un gran numero di predittori. Le nuove variabili sono indipendenti l'una dall'altra ma meno interpretabili.
- TSNE: fornisce l'incorporamento di dimensioni inferiori di punti dati di dimensioni superiori.
- SVD - La decomposizione del valore singolare viene utilizzata per scomporre la matrice in parti più piccole al fine di un calcolo efficiente.
5) Apprendimento profondo
Il deep learning è un sottoinsieme dell'apprendimento automatico che si occupa di reti neurali. Basandoci sull'architettura delle reti neurali, elenchiamo importanti modelli di deep learning:
- Percezione multistrato
- Reti neurali di convoluzione
- Reti neurali ricorrenti
- Macchina Boltzmann
- Autoencoder ecc.
Quale modello è il migliore?
Sopra abbiamo preso idee su molti modelli di apprendimento automatico. Ora ci viene in mente una domanda ovvia "Qual è il miglior modello tra loro?" Dipende dal problema attuale e da altri attributi associati come valori anomali, volume di dati disponibili, qualità dei dati, ingegneria delle caratteristiche, ecc. In pratica, è sempre preferibile iniziare con il modello più semplice applicabile al problema e aumentare la complessità gradualmente tramite un'adeguata regolazione dei parametri e cross-validation. Esiste un proverbio nel mondo della scienza dei dati: "La convalida incrociata è più affidabile della conoscenza del dominio".
Come costruire un modello?
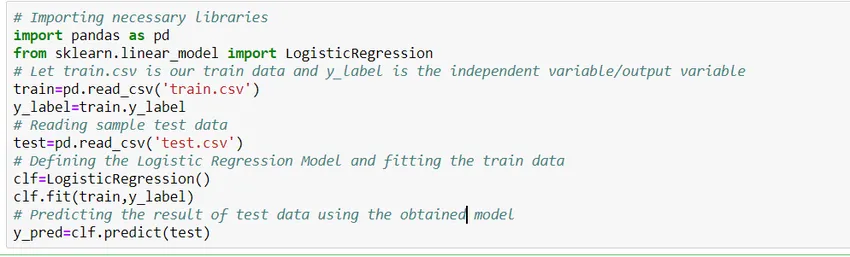
Vediamo come costruire un semplice modello di regressione logistica usando la libreria di Python di Scikit Learn. Per semplicità, supponiamo che il problema sia un modello di classificazione standard e "train.csv" è il treno e "test.csv" rispettivamente i dati di treno e test.
Conclusione
In questo articolo, abbiamo discusso degli importanti modelli di apprendimento automatico utilizzati a scopi pratici e di come creare un semplice modello di apprendimento automatico in Python. La scelta di un modello adeguato per un particolare caso d'uso è molto importante per ottenere il risultato corretto di un'attività di apprendimento automatico. Per confrontare le prestazioni tra vari modelli, vengono definite metriche di valutazione o KPI per particolari problemi aziendali e viene scelto il modello migliore per la produzione dopo aver applicato il controllo statistico delle prestazioni.
Articoli consigliati
Questa è una guida ai modelli di apprendimento automatico. Qui discutiamo i primi 5 tipi di modelli di apprendimento automatico con la sua definizione. Puoi anche consultare i nostri altri articoli suggeriti per saperne di più -
- Metodi di apprendimento automatico
- Tipi di apprendimento automatico
- Algoritmi di apprendimento automatico
- Che cos'è l'apprendimento automatico?
- Apprendimento automatico iperparametro
- KPI in Power BI
- Algoritmo di clustering gerarchico
- Clustering gerarchico Clustering agglomerativo e divisivo