
Introduzione alle tecniche di ensemble
L'apprendimento di ensemble è una tecnica di apprendimento automatico che richiede l'aiuto di numerosi modelli di base e combina i loro risultati per produrre un modello ottimizzato. Questo tipo di algoritmo di apprendimento automatico aiuta a migliorare le prestazioni complessive del modello. Qui il modello di base più comunemente usato è il classificatore dell'albero decisionale. Un albero decisionale funziona fondamentalmente su diverse regole e fornisce un risultato predittivo, in cui le regole sono i nodi e le loro decisioni saranno i loro figli e i nodi foglia costituiranno la decisione finale. Come mostrato nell'esempio di un albero decisionale.
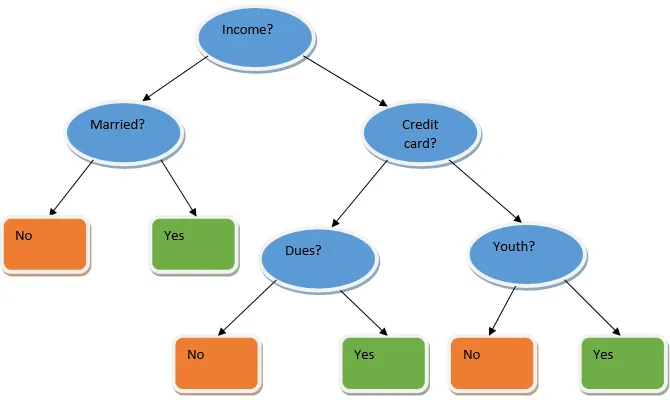
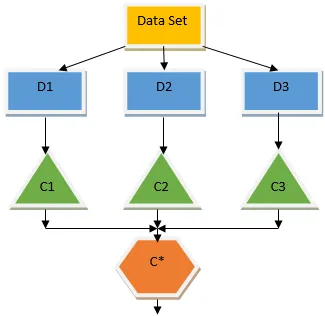
L'albero decisionale di cui sopra sostanzialmente parla se a una persona / cliente può essere concesso un prestito o meno. Una delle regole per l'ammissibilità del prestito sì è che if (reddito = Sì && Sposato = No) Quindi Prestito = Sì, ecco come funziona un classificatore dell'albero decisionale. Incorporeremo questi classificatori come modello a base multipla e combineremo il loro output per creare un modello predittivo ottimale. La Figura 1.b mostra il quadro generale di un algoritmo di apprendimento dell'ensemble.
Tipi di tecniche di ensemble
Diversi tipi di ensemble, ma il nostro focus principale sarà sui due seguenti tipi:
- insacco
- Aumentare
Questi metodi aiutano a ridurre la varianza e la distorsione in un modello di apprendimento automatico. Ora proviamo a capire cos'è bias e varianza. La distorsione è un errore che si verifica a causa di ipotesi errate nel nostro algoritmo; una tendenza eccessiva indica che il nostro modello è troppo semplice / inadatto. La varianza è l'errore causato dalla sensibilità del modello a fluttuazioni molto piccole nel set di dati; una varianza elevata indica che il nostro modello è altamente complesso / sovradimensionato. Un modello ML ideale dovrebbe avere un giusto equilibrio tra distorsione e varianza.
Bootstrap Aggregating / Bagging
Il bagging è una tecnica di ensemble che aiuta a ridurre la varianza nel nostro modello e quindi a evitare un eccesso di adattamento. Il bagging è un esempio dell'algoritmo di apprendimento parallelo. Il confezionamento funziona in base a due principi.
- Bootstrap: dal set di dati originale, vengono prese in considerazione diverse popolazioni campione con sostituzione.
- Aggregazione: calcolare la media dei risultati di tutti i classificatori e fornire un output singolo, per questo utilizza il voto a maggioranza in caso di classificazione e la media in caso di problema di regressione. Uno dei famosi algoritmi di apprendimento automatico che utilizzano il concetto di insaccamento è una foresta casuale.
Foresta casuale
Nella foresta casuale dal campione casuale ritirato dalla popolazione con sostituzione e viene selezionato un sottoinsieme di caratteristiche dall'insieme di tutte le caratteristiche che viene creato un albero decisionale. Da questi sottoinsiemi di funzionalità, qualunque sia la funzione che offre la migliore divisione è selezionata come radice per l'albero decisionale. Il sottoinsieme di funzionalità deve essere scelto in modo casuale a qualsiasi costo, altrimenti finiremo per produrre solo tress correlati e la varianza del modello non verrà migliorata.
Ora abbiamo costruito il nostro modello con i campioni prelevati dalla popolazione, la domanda è: come possiamo validare il modello? Dal momento che stiamo prendendo in considerazione i campioni con sostituzione, quindi tutti i campioni non verranno presi in considerazione e alcuni di essi non saranno inclusi in nessun sacchetto, questi vengono chiamati campioni fuori borsa. Possiamo validare il nostro modello con questi campioni OOB (out of bag). I parametri importanti da considerare in una foresta casuale sono il numero di campioni e il numero di alberi. Consideriamo 'm' come sottoinsieme di funzionalità e 'p' è il set completo di funzionalità, ora come regola del pollice, è sempre l'ideale per scegliere
- m as√ e una dimensione minima del nodo come 1 per un problema di classificazione.
- m come P / 3 e la dimensione minima del nodo deve essere 5 per un problema di regressione.
M e P dovrebbero essere trattati come parametri di ottimizzazione quando affrontiamo un problema pratico. La formazione può essere terminata una volta stabilizzato l'errore OOB. Uno svantaggio della foresta casuale è che quando abbiamo 100 funzionalità nel nostro set di dati e solo un paio di funzionalità sono importanti, questo algoritmo funzionerà male.
Aumentare
Il potenziamento è un algoritmo di apprendimento sequenziale che aiuta a ridurre la distorsione nel nostro modello e la varianza in alcuni casi di apprendimento supervisionato. Aiuta anche a convertire gli studenti deboli in studenti forti. Il potenziamento funziona secondo il principio del posizionamento sequenziale degli studenti deboli e assegna un peso a ciascun punto dati dopo ogni round; più peso viene assegnato al punto dati classificato erroneamente nel round precedente. Questo metodo sequenziale ponderato di formazione del nostro set di dati è la differenza fondamentale rispetto a quello del bagging.
Fig3.a mostra l'approccio generale nel potenziamento
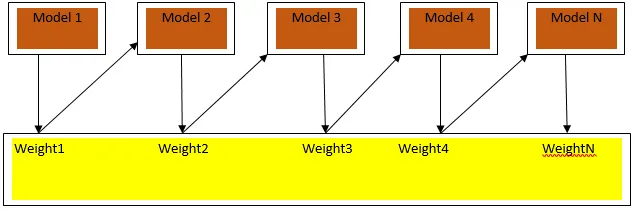
Le previsioni finali sono combinate in base al voto a maggioranza ponderata in caso di classificazione e alla somma ponderata in caso di regressione. L'algoritmo di boosting più utilizzato è il boost adattivo (Adaboost).
Potenziamento adattivo
I passaggi coinvolti nell'algoritmo Adaboost sono i seguenti:
- Per i n punti dati dati definiamo il target di classe e inizializziamo tutti i pesi a 1 / n.
- Adattiamo i classificatori al set di dati e scegliamo la classificazione con l'errore di classificazione meno ponderato
- Assegniamo pesi per il classificatore mediante una regola del pollice basata sull'accuratezza, se l'accuratezza è superiore al 50%, il peso è positivo e viceversa.
- Aggiorniamo i pesi dei classificatori al termine dell'iterazione; aggiorniamo più peso per il punto classificato erroneamente in modo che nella prossima iterazione lo classifichiamo correttamente.
- Dopo tutta l'iterazione otteniamo il risultato della previsione finale in base alla maggioranza votata / media ponderata.
L'adaboosting funziona in modo efficiente con studenti deboli (meno complessi) e con classificatori con distorsioni elevate. I principali vantaggi di Adaboosting sono la sua rapidità, non esistono parametri di ottimizzazione simili al caso del bagging e non facciamo ipotesi su studenti deboli. Questa tecnica non fornisce un risultato accurato quando
- Ci sono più valori anomali nei nostri dati.
- Il set di dati è insufficiente.
- Gli studenti deboli sono molto complessi.
Sono anche sensibili al rumore. Gli alberi decisionali prodotti a seguito del potenziamento avranno profondità e precisione elevate limitate.
Conclusione
Le tecniche di apprendimento degli ensemble sono ampiamente utilizzate per migliorare l'accuratezza del modello; dobbiamo decidere quale tecnica usare in base al nostro set di dati. Ma queste tecniche non sono preferite in alcuni casi in cui l'interpretazione è importante, poiché perdiamo l'interpretazione a scapito del miglioramento delle prestazioni. Questi hanno un enorme significato nel settore sanitario dove un piccolo miglioramento delle prestazioni è molto prezioso.
Articoli consigliati
Questa è una guida alle tecniche di ensemble. Qui discutiamo l'introduzione e due tipi principali di tecniche di ensemble. Puoi anche consultare i nostri altri articoli correlati per saperne di più-
- Tecniche di steganografia
- Tecniche di apprendimento automatico
- Tecniche di team building
- Algoritmi di scienza dei dati
- Tecniche più utilizzate per l'apprendimento degli ensemble