

Panoramica dell'architettura di data mining
Il data mining è il modo di trovare ed esplorare i modelli di base o di livello avanzato in un insieme complicato di grandi set di dati che coinvolge i metodi posti all'intersezione di statistiche, apprendimento automatico e anche sistemi di database. Si può dire che sia un campo interdisciplinare di statistica e informatica dove l'obiettivo è quello di estrarre le informazioni usando metodi e tecniche intelligenti da una particolare serie di dati mediante estrazione e trasformando così i dati. Vengono prese in considerazione anche le attività di gestione dei dati e le attività di preelaborazione dei dati insieme a considerazioni di inferenza. In questo articolo, approfondiremo l'architettura del data mining.
Architettura di data mining
Il data mining è la tecnica per estrarre conoscenze interessanti da una serie di enormi quantità di dati che vengono poi archiviati in molte fonti di dati come file system, data warehouse, database. I componenti principali dell'architettura di data mining riguardano:
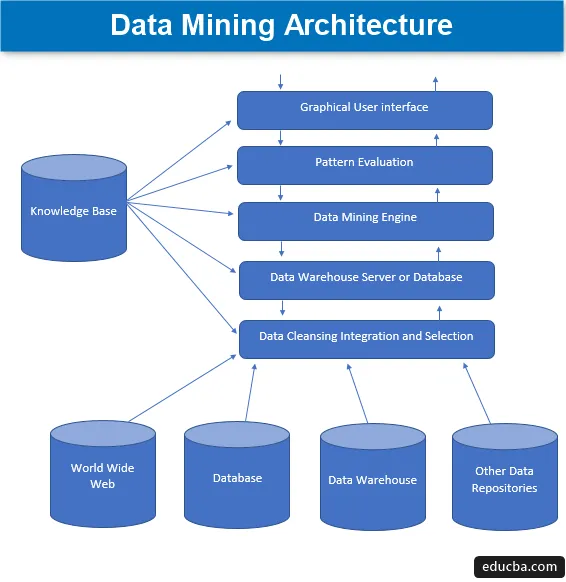
1. Fonti di dati
Un'enorme varietà di documenti attuali come data warehouse, database, www o popolarmente chiamati World Wide Web che diventano le attuali fonti di dati. Il più delle volte, può anche accadere che i dati non siano presenti in nessuna di queste fonti d'oro, ma solo sotto forma di file di testo, file semplici o file di sequenza o fogli di calcolo e quindi i dati devono essere elaborati in modo molto modo simile al trattamento sarebbe effettuato sui dati ricevuti da fonti d'oro. La maggior parte della maggior parte dei dati oggi viene ricevuta da Internet o dal World Wide Web in quanto tutto ciò che è presente su Internet oggi è costituito da dati in un modo o nell'altro che formano una qualche forma di unità di deposito di informazioni.
Prima che i dati vengano elaborati in anticipo, i diversi processi attraverso i quali passa comportano la pulizia, l'integrazione e la selezione dei dati prima che i dati vengano infine trasferiti sul database o su uno qualsiasi dei server EDW (enterprise data warehouse). La principale sfida che si presenta a volte con questo insieme di dati è costituita da diversi livelli di fonti e una vasta gamma di formati di dati che formano i componenti dei dati. Pertanto i dati non possono essere utilizzati direttamente per l'elaborazione nel loro stato ingenuo ma elaborati, trasformati e realizzati in un modo molto più utilizzabile. In questo modo, sono garantite anche l'affidabilità e la completezza dei dati. Pertanto, il passaggio principale prevede la raccolta, la pulizia e l'integrazione dei dati e postare che vengano trasmessi solo i dati rilevanti. Tutta questa attività fa parte di un insieme separato di strumenti e tecniche.
2. Server o database Data Warehouse
Il server di database è lo spazio effettivo in cui sono contenuti i dati una volta ricevuti dal diverso numero di origini dati. Il server contiene l'effettivo set di dati che diventa pronto per l'elaborazione e quindi il server gestisce il recupero dei dati. Tutta questa attività si basa sulla richiesta di data mining della persona.
3. Motore di data mining
Nel caso del data mining, il motore costituisce il componente principale ed è la parte più vitale, o per dire la forza motrice che gestisce tutte le richieste e le gestisce e viene utilizzata per contenere un numero di moduli. Il numero di moduli presenti include attività di mining come tecnica di classificazione, tecnica di associazione, tecnica di regressione, caratterizzazione, previsione e raggruppamento, analisi di serie temporali, Bayes ingenui, macchine vettoriali di supporto, metodi di ensemble, tecniche di potenziamento e insacco, foreste casuali, alberi decisionali, eccetera.
4. Moduli di valutazione dei modelli
Questa tecnica di valutazione dei moduli è principalmente responsabile della misurazione dell'interesse di tutti quei modelli che vengono utilizzati per calcolare il livello di base del valore di soglia e viene anche utilizzato per interagire con il motore di data mining per coordinarsi nella valutazione di altri moduli. Tutto sommato, lo scopo principale di questo componente è quello di cercare e cercare tutti i modelli interessanti e utilizzabili che potrebbero rendere i dati di qualità relativamente migliore.
5. Interfaccia utente grafica
Quando i dati vengono comunicati con i motori e tra i vari modelli di valutazione dei moduli, diventa una necessità interagire con i vari componenti presenti e renderli più user friendly in modo da poter fare un uso efficiente ed efficace di tutti i componenti presenti e quindi sorge la necessità di un'interfaccia utente grafica popolarmente conosciuta come GUI.
Questo viene utilizzato per stabilire un senso di contatto tra l'utente e il sistema di data mining, aiutando così gli utenti ad accedere e utilizzare il sistema in modo efficiente e semplice per tenerli privi di qualsiasi complessità che si è verificata nel processo. Questa è una forma di astrazione in cui solo i componenti rilevanti vengono visualizzati agli utenti e tutte le complessità e le funzionalità responsabili della costruzione del sistema sono nascoste per motivi di semplicità. Ogni volta che l'utente invia una query, il modulo interagisce con l'insieme complessivo di un sistema di data mining per produrre un output rilevante che potrebbe essere facilmente mostrato all'utente in un modo molto più comprensibile.
6. Base di conoscenza
Questo è il componente che costituisce la base dell'intero processo di data mining in quanto aiuta a guidare la ricerca o la valutazione dell'interesse dei modelli formati. Questa base di conoscenza comprende credenze dell'utente e anche i dati ottenuti dalle esperienze dell'utente che sono a loro volta utili nel processo di data mining. Il motore potrebbe ottenere il suo set di input dalla knowledge base creata e quindi fornire risultati più efficienti, accurati e affidabili.
Il data mining è oggi una delle tecniche più importanti che si occupa della gestione e dell'elaborazione dei dati che costituisce la spina dorsale di qualsiasi organizzazione. L'analisi dei dati in qualsiasi organizzazione porterà risultati fruttuosi. Ogni componente della tecnica e dell'architettura di data mining ha il suo modo di eseguire le responsabilità e anche di completare in modo efficiente il data mining. I diversi moduli sono necessari per interagire correttamente in modo da produrre un risultato prezioso e completare con successo la complessa procedura di data mining fornendo il giusto set di informazioni all'azienda.
Articoli consigliati
Questa è stata una guida all'architettura di data mining. Qui discutiamo i componenti principali dell'architettura di data mining. Puoi anche consultare i nostri altri articoli suggeriti per saperne di più -
- Strumento di data mining
- Vantaggi del data mining
- Che cos'è il clustering nel data mining?
- Domande e risposte sull'intervista HTML5
- Tecniche più utilizzate per l'apprendimento degli ensemble
- Algoritmi di modelli nel data mining