

Introduzione a Joins in Hive
I join vengono utilizzati per recuperare vari output utilizzando più tabelle, combinandoli in base a colonne particolari. Ora, affinché le tabelle siano in Hive, ci viene richiesto di creare le tabelle e caricare i dati in ciascuna tabella. Useremo due tabelle (cliente e prodotto) qui per capire lo scopo.
Comandi diversi
Di seguito sono riportati i comandi per la creazione e il caricamento dei dati in queste tabelle:
Per la tabella dei clienti : 6 righe
Crea comando
Crea tabella esterna se non esiste cliente (stringa id, stringa nome, stringa città)
formato riga delimitato
campi terminati da ''
posizione '/user/hive/warehouse/test.db/customer'
tblproperties (“skip.header.line.count” = ”1”);
Carica comando
Carica dati locali nel percorso '/home/cloudera/Customer_Neha.txt' nel cliente della tabella;
Dati della tabella dei clienti

Per la tabella dei prodotti : 6 righe
Crea comando
Crea tabella esterna se non esiste prodotto (stringa Cust_Id,
Stringa di prodotto, stringa di prezzo)
formato riga delimitato
campi terminati da ''
posizione '/user/hive/warehouse/test.db/product'
tblproperties (“skip.header.line.count” = ”1”);
Carica comando
Carica il percorso locale dei dati '/home/cloudera/Product_Neha.txt' nel prodotto tabella;
Dati della tabella dei prodotti
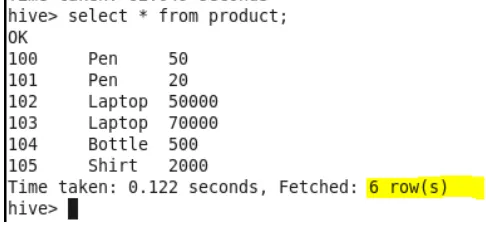
Per controllare lo schema della tabella, utilizzare il comando "desc table name;"
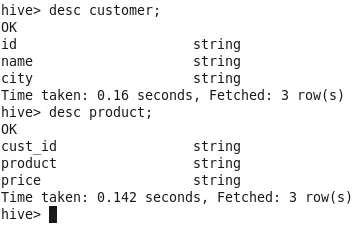
Ora, abbiamo dati nelle tabelle, giochiamo con esso ????
Tipi di join in Hive
Unisci: questo fornirà il prodotto incrociato di entrambi i dati della tabella come output. Come puoi vedere, abbiamo 6 righe in ogni tabella. Quindi l'output per Join sarà di 36 righe. Il numero di mapper-1. Tuttavia, non viene utilizzato alcun riduttore per l'operatore.
Comando

Produzione:
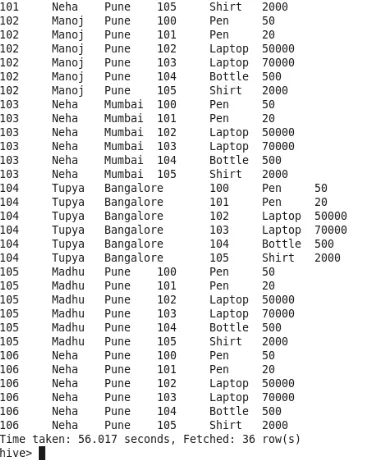
1. Partecipazione completa
L'unione completa senza condizioni di corrispondenza darà il prodotto incrociato di entrambe le tabelle.
Numero di mappatori-2
Numero di riduttori-1
Ciò può essere ottenuto anche usando "Unisci" ma con un numero inferiore di mappatore e riduttore.
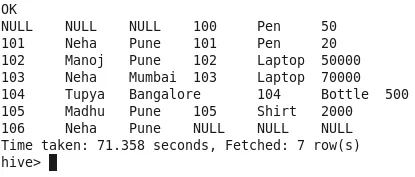
Partecipazione completa con condizioni di partita
Tutte le righe verranno unite da entrambe le tabelle. Se le righe non corrispondono in un'altra tabella, NULL verrà popolato nell'output (Observe Id-100.106). Nessuna riga viene ignorata.
Numero di mappatori-2
Numero di riduttori-1
Comando

Produzione:
2. Join interno
Se il join interno viene utilizzato senza la clausola "on", fornirà il prodotto incrociato come output. Tuttavia, ci viene richiesto di utilizzare le colonne specifiche su cui è possibile eseguire il join. La colonna Id dalla tabella cliente e la colonna Cust_id dalla tabella prodotto sono le mie colonne specifiche. L'output contiene le righe in cui Id e Cust_Id corrispondono. È possibile osservare che le righe con Id-106 e Cust_Id-100 vengono ignorate nell'output perché non sono presenti in un'altra tabella.
Comando

Produzione:

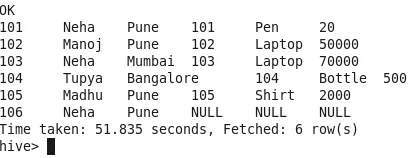
3. Join sinistro
Tutte le righe della tabella di sinistra sono unite con le righe corrispondenti della tabella di destra. Se la tabella di destra ha righe con ID che non sono presenti nella tabella di sinistra, tali righe verranno ignorate (Osservare Cust_Id-100 nell'output). Se la tabella di destra non ha righe con ID presenti nella tabella di sinistra, NULL verrà popolato in output (Osserva Id-106 in output).
Numero di Mapper-1
Numero di riduttore-0
Comando

Produzione:
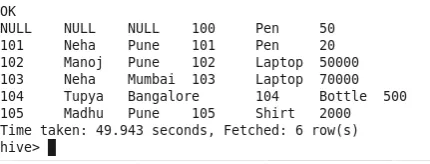
4. Partecipa a destra
Tutte le righe dalla tabella destra sono abbinate alle righe della tabella sinistra. Se la tabella di sinistra non ha alcuna riga, verrà popolato NULL (Observe Id 100). Le righe della tabella di sinistra verranno ignorate se tale corrispondenza non viene trovata nella tabella di destra (Osservare ID 106).
Numero di Mapper-1
Numero di riduttore-0
Comando

Produzione:
Conclusione - Partecipa a Hive
"Partecipa" come suggerisce la parola, può unire due o più tabelle nel database. È simile ai join in SQL. I join vengono utilizzati per recuperare vari output utilizzando più tabelle, combinandoli in base a colonne particolari. In base al requisito si può decidere quale join funzionerà per te. Ad esempio, se si desidera verificare quali sono gli ID presenti nella tabella di sinistra ma non nella tabella di destra, è possibile utilizzare semplicemente il join sinistro. Varie ottimizzazioni possono essere eseguite nei join hive a seconda della complessità. Alcuni degli esempi sono join di ripartizione, join di replica e semi-join.
Articoli consigliati
Questa è una guida per Joins in Hive. Qui discutiamo i tipi di join come full join, inner join, left join e right join in hive insieme al suo comando e output. Puoi anche consultare i seguenti articoli per saperne di più-
- Che cos'è un alveare?
- Comandi alveare
- Hive Training (2 corsi, 5+ progetti)
- Apache Pig vs Apache Hive - Le 12 principali differenze utili
- Caratteristiche di Hive Alternatives
- Utilizzo della funzione ORDER BY in Hive
- I 6 migliori tipi di join in MySQL con esempi