
Introduzione al ciclo di vita della scienza dei dati
Il ciclo di vita della scienza dei dati ruota attorno all'uso dell'apprendimento automatico e ad altri metodi analitici per produrre approfondimenti e previsioni dai dati al fine di raggiungere un obiettivo aziendale. L'intero processo prevede diversi passaggi come pulizia dei dati, preparazione, modellazione, valutazione del modello, ecc. È un processo lungo e può richiedere diversi mesi per essere completato. Quindi, è molto importante avere una struttura generale da seguire per ogni problema a portata di mano. La struttura riconosciuta a livello globale nella risoluzione di qualsiasi problema analitico viene definita come processo standard intersettoriale per data mining o framework CRISP-DM.
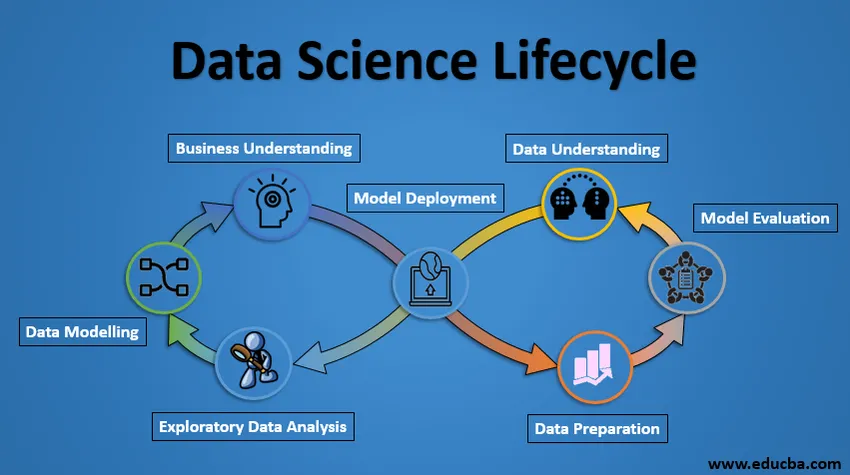
Ciclo di vita della scienza dei dati
Di seguito sono riportati il progetto Lifecycle of Data Science.
1. Comprensione aziendale
L'intero ciclo ruota attorno all'obiettivo aziendale. Cosa risolverai se non hai un problema preciso? È estremamente importante comprendere chiaramente l'obiettivo aziendale perché quello sarà il tuo obiettivo finale dell'analisi. Solo dopo un'adeguata comprensione possiamo stabilire l'obiettivo specifico dell'analisi che è in sintonia con l'obiettivo aziendale. Devi sapere se il cliente vuole ridurre la perdita di credito o se vuole prevedere il prezzo di una merce, ecc.
2. Comprensione dei dati
Dopo la comprensione aziendale, il passaggio successivo è la comprensione dei dati. Ciò comporta la raccolta di tutti i dati disponibili. Qui devi lavorare a stretto contatto con il team aziendale in quanto sono effettivamente a conoscenza di quali dati sono presenti, quali dati potrebbero essere utilizzati per questo problema aziendale e altre informazioni. Questo passaggio prevede la descrizione dei dati, la loro struttura, la loro rilevanza, il loro tipo di dati. Esplora i dati utilizzando grafici. Fondamentalmente, estrarre qualsiasi informazione che è possibile ottenere sui dati semplicemente esplorando i dati.
3. Preparazione dei dati
Segue la fase di preparazione dei dati. Ciò include passaggi come la selezione dei dati rilevanti, l'integrazione dei dati unendo i set di dati, pulendoli, trattando i valori mancanti rimuovendoli o imputandoli, trattando i dati errati rimuovendoli, verificando anche i valori anomali utilizzando grafici a scatole e gestendoli . Costruire nuovi dati, derivare nuove funzionalità da quelle esistenti. Formatta i dati nella struttura desiderata, rimuovi colonne e caratteristiche indesiderate. La preparazione dei dati è il passo più lungo e probabilmente il più importante dell'intero ciclo di vita. Il tuo modello sarà buono come i tuoi dati.
4. Analisi dei dati esplorativi
Questo passaggio implica avere un'idea della soluzione e dei fattori che la influenzano, prima di costruire il modello reale. La distribuzione dei dati all'interno di diverse variabili di una funzione viene esplorata graficamente mediante grafici a barre. Le relazioni tra le diverse funzioni vengono acquisite tramite rappresentazioni grafiche come grafici a dispersione e mappe di calore. Molte altre tecniche di visualizzazione dei dati sono ampiamente utilizzate per esplorare ogni funzionalità individualmente e combinandole con altre funzionalità.
5. Modellazione dei dati
La modellazione dei dati è il cuore dell'analisi dei dati. Un modello accetta i dati preparati come input e fornisce l'output desiderato. Questo passaggio include la scelta del tipo di modello appropriato, se il problema è un problema di classificazione o un problema di regressione o di clustering. Dopo aver scelto la famiglia di modelli, tra i vari algoritmi all'interno di quella famiglia, dobbiamo scegliere con cura gli algoritmi per implementarli e implementarli. Dobbiamo mettere a punto gli iperparametri di ciascun modello per ottenere le prestazioni desiderate. Dobbiamo anche assicurarci che ci sia un corretto equilibrio tra prestazioni e generalizzabilità. Non vogliamo che il modello apprenda i dati e abbia prestazioni scarse sui nuovi dati.
6. Valutazione del modello
Qui il modello viene valutato per verificare se è pronto per essere distribuito. Il modello viene testato su dati invisibili, valutati su una serie di metriche di valutazione attentamente studiate. Dobbiamo anche assicurarci che il modello sia conforme alla realtà. Se non otteniamo un risultato soddisfacente nella valutazione, dobbiamo reiterare l'intero processo di modellazione fino a raggiungere il livello desiderato di metriche. Qualsiasi soluzione per la scienza dei dati, un modello di apprendimento automatico, proprio come un essere umano, dovrebbe evolversi, dovrebbe essere in grado di migliorarsi con nuovi dati, adattarsi a una nuova metrica di valutazione. Possiamo costruire più modelli per un certo fenomeno, ma molti di essi possono essere imperfetti. La valutazione del modello ci aiuta a scegliere e costruire un modello perfetto.
7. Modello di distribuzione
Il modello dopo una rigorosa valutazione viene finalmente distribuito nel formato e nel canale desiderati. Questo è l'ultimo passo del ciclo di vita della scienza dei dati. Ogni fase del ciclo di vita della scienza dei dati spiegata sopra dovrebbe essere attentamente studiata. Se un passaggio viene eseguito in modo errato, ciò influirà di conseguenza sul passaggio successivo e l'intero sforzo andrà sprecato. Ad esempio, se i dati non vengono raccolti correttamente, perderai informazioni e non costruirai un modello perfetto. Se i dati non vengono puliti correttamente, il modello non funzionerà. Se il modello non viene valutato correttamente, fallirà nel mondo reale. Dalla comprensione del business alla distribuzione del modello, ogni passaggio dovrebbe ricevere adeguata attenzione, tempo e impegno.
Articoli consigliati
Questa è una guida al ciclo di vita di Data Science. Qui discutiamo una panoramica del ciclo di vita della scienza dei dati e i passaggi che compongono un ciclo di vita della scienza dei dati. Puoi anche consultare i nostri articoli correlati per saperne di più -
- Introduzione agli algoritmi di data science
- Data Science vs Ingegneria del software | I 8 migliori confronti utili
- Tipi di differenza di tecniche di scienza dei dati
- Competenze di data science con tipi