

Introduzione alle tecniche di data science
Nel mondo di oggi, dove i dati sono il nuovo oro, ci sono diversi tipi di analisi disponibili per un'azienda. Il risultato di un progetto di data science varia notevolmente a seconda del tipo di dati disponibili e quindi anche l'impatto è variabile. Dato che sono disponibili molti tipi diversi di analisi, diventa indispensabile capire quali tecniche di base devono essere selezionate. L'obiettivo essenziale delle tecniche di scienza dei dati non è solo la ricerca di informazioni pertinenti, ma anche il rilevamento di collegamenti deboli che tendono a far funzionare male il modello.
Che cos'è la scienza dei dati?
La scienza dei dati è un campo che si estende su diverse discipline. Incorpora metodi, processi, algoritmi e sistemi scientifici per raccogliere conoscenze e lavorare sullo stesso. Questo campo include una varietà di generi ed è una piattaforma comune per l'unificazione di concetti di statistica, analisi dei dati e apprendimento automatico. In questo, la conoscenza teorica delle statistiche insieme a dati e tecniche in tempo reale nell'apprendimento automatico lavorano fianco a fianco per ottenere risultati fruttuosi per l'azienda. Utilizzando diverse tecniche impiegate nella scienza dei dati, nel mondo di oggi possiamo implicare un migliore processo decisionale che altrimenti potrebbe mancare dall'occhio e dalla mente umana. Ricorda che la macchina non dimentica mai! Per massimizzare il profitto in un mondo basato sui dati, la magia di Data Science è uno strumento necessario da avere.
Diversi tipi di tecnica di scienza dei dati
Nei seguenti paragrafi esamineremo le comuni tecniche di data science utilizzate in ogni altro progetto. Anche se a volte la tecnica di data science può essere specifica del problema aziendale e potrebbe non rientrare nelle categorie sottostanti, va benissimo definirli come tipi vari. Ad alto livello, dividiamo le tecniche in Supervisionato (conosciamo l'impatto sul target) e Non supervisionato (Non conosciamo la variabile target che stiamo cercando di raggiungere). Nel livello successivo, le tecniche possono essere suddivise in termini di
- L'output che otterremmo o qual è lo scopo del problema aziendale
- Tipo di dati utilizzati.
Diamo prima un'occhiata alla segregazione basata sull'intenzione.
1. Apprendimento senza supervisione
- Anomaly Detection
In questo tipo di tecnica, identifichiamo qualsiasi evento imprevisto nell'intero set di dati. Poiché il comportamento differisce dall'effettivo verificarsi di un dato, le ipotesi sottostanti sono:
- L'occorrenza di questi casi è molto ridotta.
- La differenza di comportamento è significativa.
Vengono spiegati algoritmi di anomalia, come la Foresta di isolamento, che fornisce un punteggio per ogni record in un set di dati. Questo algoritmo è un modello basato su alberi. Usando questo tipo di tecnica di rilevamento e la sua popolarità vengono utilizzati in vari casi aziendali, ad esempio visualizzazioni di pagine Web, frequenza di abbandono, entrate per clic, ecc. Nel grafico seguente possiamo spiegare come si presenta l'anomalia.
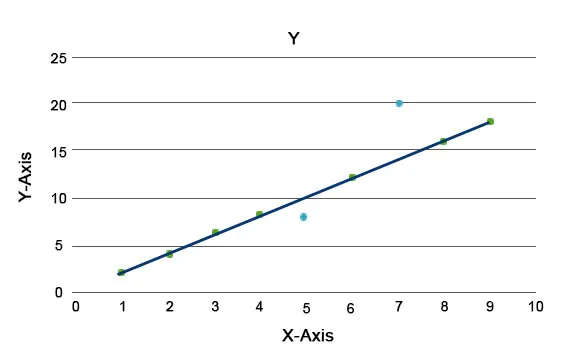
Qui quelli in blu rappresentano un'anomalia nel set di dati. Variano dalla normale linea di tendenza e sono meno frequenti.
- Analisi del clustering
Attraverso questa analisi, il compito principale è quello di separare l'intero set di dati in gruppi in modo che la tendenza o i tratti nei punti di un gruppo siano abbastanza simili tra loro. Nella terminologia della scienza dei dati li chiamiamo cluster. Ad esempio, nel settore del commercio al dettaglio, esiste un piano per ridimensionare il business e diventa indispensabile sapere come si comporterebbero i nuovi clienti in una nuova regione in base ai dati passati di cui disponiamo. Diventa impossibile elaborare una strategia per ogni individuo in una popolazione, ma sarà utile raggruppare la popolazione in gruppi in modo che la strategia sia efficace in un gruppo ed è scalabile.
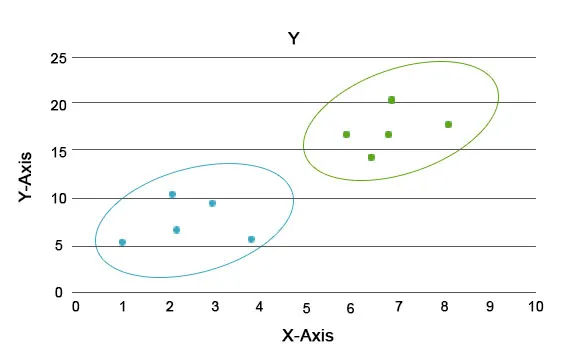
Qui i colori blu e arancione sono diversi gruppi che hanno tratti unici al loro interno.
- Analisi dell'associazione
Questa analisi ci aiuta a costruire relazioni interessanti tra gli elementi in un set di dati. Questa analisi rivela relazioni nascoste e aiuta a rappresentare gli elementi del set di dati sotto forma di regole di associazione o insiemi di elementi frequenti. La regola di associazione è suddivisa in 2 passaggi:
- Generazione di set di articoli frequenti: in questo viene generato un set in cui vengono impostati insieme gli articoli che si verificano di frequente.
- Generazione di regole: l'insieme creato sopra viene passato attraverso diversi livelli di formazione delle regole per costruire una relazione nascosta tra loro. Ad esempio, il set può cadere in problemi concettuali o di implementazione o problemi di applicazione. Questi vengono quindi ramificati nei rispettivi alberi per creare le regole di associazione.
Ad esempio, APRIORI è un algoritmo di creazione di regole di associazione.
2. Apprendimento supervisionato
- Analisi di regressione
Nell'analisi di regressione, definiamo la variabile dipendente / target e le variabili rimanenti come variabili indipendenti e infine ipotizziamo come una / più variabili indipendenti influenzano la variabile target. La regressione con una variabile indipendente è chiamata univariata e con più di una è nota come multivariata. Cerchiamo di capire usando univariato e quindi ridimensionare per multivariato.
Ad esempio, y è la variabile target e x 1 è la variabile indipendente. Quindi, dalla conoscenza della retta, possiamo scrivere l'equazione come y = mx 1 + c. Qui "m" determina quanto fortemente y è influenzato da x 1 . Se "m" è molto vicino allo zero, significa che con una modifica in x 1, y non è influenzato fortemente. Con un numero maggiore di 1, l'impatto diventa più forte e il piccolo cambiamento in x 1 porta a una grande variazione in y. Simile a univariato, in multivariato può essere scritto come y = m 1 x 1 + m 2 x 2 + m 3 x 3 ………., Qui l'impatto di ciascuna variabile indipendente è determinato dalla corrispondente “m”.
- Analisi di classificazione
Simile all'analisi del clustering, gli algoritmi di classificazione sono costruiti con la variabile target sotto forma di classi. La differenza tra clustering e classificazione risiede nel fatto che nel clustering non sappiamo in quale gruppo rientrano i punti dati, mentre nella classificazione sappiamo a quale gruppo appartiene. E differisce dalla regressione dalla prospettiva che il numero di gruppi dovrebbe essere un numero fisso a differenza della regressione, è continuo. Esistono numerosi algoritmi nell'analisi della classificazione, ad esempio Macchine di supporto vettoriale, Regressione logistica, Alberi decisionali, ecc.
Conclusione
In conclusione, comprendiamo che ogni tipo di analisi è vasta di per sé, ma qui possiamo fornire un piccolo sapore a tecniche diverse. Nelle prossime note, prenderemmo ciascuno di essi separatamente e andremo nei dettagli sulle diverse sub-tecniche impiegate in ciascuna tecnica genitore.
Articolo raccomandato
Questa è una guida alle tecniche di data science. Qui discutiamo dell'introduzione e dei diversi tipi di tecniche nella scienza dei dati. Puoi anche consultare i nostri altri articoli suggeriti per saperne di più -
- Strumenti per la scienza dei dati | I 12 migliori strumenti
- Algoritmi di data science con tipi
- Introduzione alla carriera di data science
- Data Science vs Data Visualization
- Esempi di regressione multivariata
- Crea albero decisionale con vantaggi
- Breve panoramica del ciclo di vita di Data Science