

Introduzione all'albero decisionale nel data mining
Nel mondo odierno di "Big Data" il termine "Data Mining" significa che dobbiamo esaminare grandi set di dati ed eseguire il "mining" sui dati e far emergere il succo o l'essenza importante di ciò che i dati vogliono dire. Una situazione molto analoga è quella dell'estrazione del carbone in cui sono necessari diversi strumenti per estrarre il carbone sepolto in profondità nel terreno. Tra gli strumenti del data mining "Decision Tree" è uno di questi. Pertanto, il data mining in sé è un vasto campo in cui nei prossimi paragrafi approfondiremo lo “strumento” dell'albero decisionale in Data Mining.
Algoritmo dell'albero decisionale nel data mining
Un albero decisionale è un approccio di apprendimento supervisionato in cui formiamo i dati presenti già sapendo quale sia effettivamente la variabile target. Come suggerisce il nome, questo algoritmo ha un tipo di struttura ad albero. Esaminiamo prima l'aspetto teorico dell'albero decisionale e poi esaminiamo lo stesso in un approccio grafico. Nell'albero decisionale, l'algoritmo suddivide il set di dati in sottoinsiemi sulla base dell'attributo più importante o significativo. L'attributo più significativo è designato nel nodo radice ed è qui che avviene la divisione dell'intero set di dati presente nel nodo radice. Questa suddivisione è nota come nodi di decisione. Nel caso in cui non sia più possibile dividere quel nodo viene definito nodo foglia.
Al fine di fermare l'algoritmo per raggiungere uno stadio travolgente, viene utilizzato un criterio di arresto. Uno dei criteri di arresto è il numero minimo di osservazioni nel nodo prima che si verifichi la divisione. Durante l'applicazione dell'albero decisionale nella suddivisione del set di dati, è necessario fare attenzione che molti nodi potrebbero avere solo dati disturbati. Per far fronte a problemi di dati anomali o rumorosi, utilizziamo tecniche note come eliminazione dei dati. La potatura dei dati non è altro che un algoritmo per classificare i dati dal sottoinsieme che rende difficile l'apprendimento da un determinato modello.
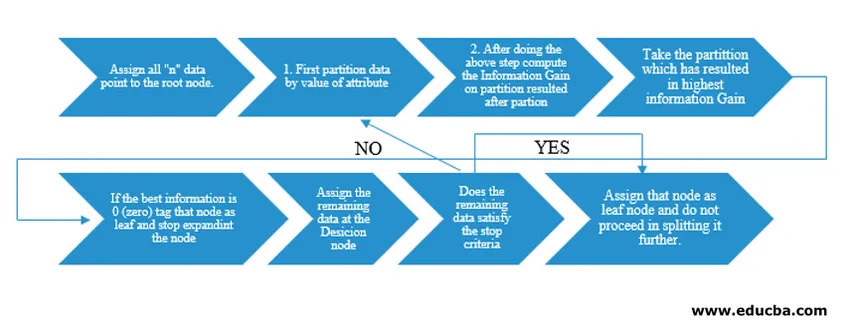
L'algoritmo di Decision Tree è stato rilasciato come ID3 (Iterative Dichotomiser) dal ricercatore di macchine J. Ross Quinlan. Successivamente C4.5 fu rilasciato come successore di ID3. Sia ID3 che C4.5 sono un approccio avido. Vediamo ora un diagramma di flusso dell'algoritmo dell'albero decisionale.
Per la nostra comprensione dello pseudocodice, prenderemmo "n" punti dati ciascuno con attributi "k". Il diagramma di flusso di seguito viene creato tenendo presente "Guadagno informazioni" come condizione per una divisione.
IG (on individual split) = Entropy before the split – Entropy after a split (On individual split)
Invece di Information Gain (IG), possiamo anche utilizzare l'indice Gini come criterio per una divisione. Per comprendere la differenza tra questi due criteri in termini di profani possiamo pensare a questo guadagno di informazioni come differenza di entropia prima della divisione e dopo la divisione (suddivisione in base a tutte le funzionalità disponibili).
L'entropia è come la casualità e raggiungeremo un punto dopo la divisione per avere il minimo stato di casualità. Pertanto, Information Gain deve essere il massimo per la funzionalità che vogliamo suddividere. Altrimenti, se vogliamo scegliere di dividere sulla base dell'indice Gini, troveremmo l'indice Gini per attributi diversi e usando lo stesso scopriremmo l'indice Gini ponderato per una divisione diversa e utilizzeremo quello con indice Gini più alto per dividere il set di dati.
Termini importanti dell'albero decisionale nel data mining
Ecco alcuni dei termini importanti di un albero decisionale nel data mining di seguito:
- Nodo radice: questo è il primo nodo in cui ha luogo la divisione.
- Nodo foglia: questo è il nodo dopo il quale non ci sono più ramificazioni.
- Nodo decisionale: il nodo formato dopo la divisione dei dati da un nodo precedente è noto come nodo decisionale.
- Branch: sottosezione di un albero contenente informazioni sulle conseguenze della divisione nel nodo decisionale.
- Potatura: quando si verifica la rimozione di sottonodi di un nodo decisionale per soddisfare i dati anomali o rumorosi, si parla di potatura. Si pensa anche che sia l'opposto della scissione.
Applicazione dell'albero decisionale nel data mining
Decision Tree ha un tipo di diagramma di flusso di architettura integrato con il tipo di algoritmo. Ha essenzialmente un tipo di pattern “If X then Y else Z” mentre viene effettuata la divisione. Questo tipo di modello viene utilizzato per comprendere l'intuizione umana nel campo programmatico. Quindi, si può ampiamente utilizzare questo in vari problemi di categorizzazione.
- Questo algoritmo può essere ampiamente utilizzato nel campo in cui la funzione obiettivo è correlata rispetto all'analisi effettuata.
- Quando sono disponibili numerosi corsi di azione.
- Analisi anomale.
- Comprendere il set significativo di funzionalità per l'intero set di dati e "estrarre" le poche funzionalità da un elenco di centinaia di funzionalità nei big data.
- Selezione del volo migliore per viaggiare verso una destinazione.
- Processo decisionale basato su diverse situazioni circostanziali.
- Analisi di Churn.
- Analisi del sentimento.
Vantaggi dell'albero decisionale
Ecco alcuni vantaggi dell'albero decisionale spiegato di seguito:
- Facilità di comprensione: il modo in cui l'albero delle decisioni viene rappresentato nelle sue forme grafiche lo rende facile da capire per una persona con un background non analitico. Soprattutto per le persone in comando che vogliono vedere quali caratteristiche sono importanti solo dando un'occhiata all'albero decisionale possono far emergere le loro ipotesi.
- Esplorazione dei dati: come discusso, l'ottenimento di variabili significative è una funzionalità fondamentale dell'albero decisionale e, usando lo stesso, si può capire durante l'esplorazione dei dati decidere quale variabile avrebbe bisogno di un'attenzione speciale nel corso della fase di data mining e modellazione.
- Vi è un intervento umano molto limitato durante la fase di preparazione dei dati e, a causa del tempo impiegato durante i dati, la pulizia viene ridotta.
- Decision Tree è in grado di gestire variabili sia categoriche che numeriche e anche di gestire problemi di classificazione multi-classe.
- Come parte dell'assunto, gli alberi decisionali non hanno alcuna ipotesi da una struttura spaziale di distribuzione e classificazione.
Conclusione
Infine, per concludere che gli alberi decisionali introducono una classe completamente diversa di non linearità e soddisfano i problemi di non linearità. Questo algoritmo è la scelta migliore per imitare un livello decisionale pensando agli umani e rappresentarlo in una forma matematico-grafica. Adotta un approccio top-down nel determinare i risultati da nuovi dati invisibili e segue il principio di divisione e conquista.
Articoli consigliati
Questa è una guida all'albero decisionale nel data mining. Qui discutiamo l'algoritmo, l'importanza e l'applicazione dell'albero decisionale nel data mining insieme ai suoi vantaggi. Puoi anche consultare i seguenti articoli per saperne di più -
- Apprendimento automatico di data science
- Tipi di tecniche di analisi dei dati
- Albero decisionale in R
- Che cos'è il data mining?
- Guida a varie metodologie di analisi dei dati