

Introduzione all'architettura di Hadoop
Hadoop Architecture è un framework open source che aiuta a elaborare facilmente grandi set di dati. Aiuta a creare applicazioni che elaborano enormi quantità di dati con maggiore velocità. Si avvale dei concetti di calcolo distribuito in cui i dati sono distribuiti su diversi nodi di un cluster. Le applicazioni costruite con Hadoop fanno uso di computer di largo consumo. Questi computer sono facilmente disponibili sul mercato a tariffe economiche. Questo risultato sta ottenendo una maggiore potenza computazionale a basso costo. Tutti i dati presenti in Hadoop risiedono su HDFS anziché su un file system locale. HDFS è un file system distribuito Hadoop. Questo modello si basa sulla posizione dei dati in cui la logica computazionale viene inviata ai nodi presenti in un cluster che contiene i dati. Questa logica non è altro che una logica che compila il programma.
Architettura di Hadoop
L'idea di base di questa architettura è che l'intera memorizzazione ed elaborazione è fatta in due fasi e in due modi. Il primo passo è l'elaborazione che viene eseguita da Map per ridurre la programmazione e il secondo passaggio è la memorizzazione dei dati che viene eseguita su HDFS. Ha un'architettura master-slave per l'archiviazione e l'elaborazione dei dati. Il nodo principale per l'archiviazione dei dati in Hadoop è il nodo del nome. C'è anche un nodo principale che svolge il compito di monitorare e parallelizzare l'elaborazione dei dati utilizzando Hadoop Map Reduce. Gli slave sono altre macchine nel cluster Hadoop che aiutano a memorizzare i dati ed eseguono anche calcoli complessi. A ciascun nodo slave è stato assegnato un tracker attività e un nodo dati ha un tracker lavoro che aiuta a eseguire i processi e sincronizzarli in modo efficace. Questo tipo di sistema può essere impostato su cloud o on-premise. Il nodo Nome è un singolo punto di errore quando non è in esecuzione in modalità ad alta disponibilità. L'architettura di Hadoop prevede inoltre il mantenimento di un nodo Nome di stand-by al fine di salvaguardare il sistema da guasti. In precedenza c'erano nodi di nomi secondari che fungevano da backup quando il nodo del nome principale era inattivo.
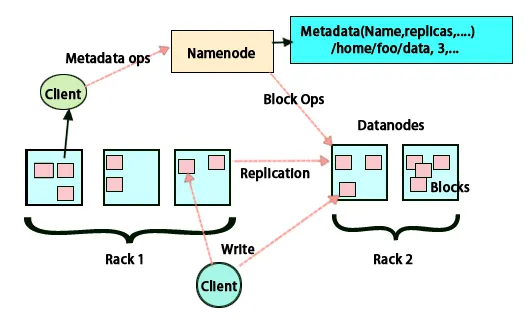
FSimage e modifica registro
FSimage e Edit Log assicurano la persistenza dei metadati del file system per tenere il passo con tutte le informazioni e il nodo nome archivia i metadati in due file. Questi file sono FSimage e il registro di modifica. Il compito di FSimage è di mantenere un'istantanea completa del file system in un determinato momento. Le modifiche che vengono costantemente apportate in un sistema devono essere registrate. Queste modifiche incrementali come la ridenominazione o l'aggiunta di dettagli al file sono memorizzate nel registro delle modifiche. Il framework offre un'opzione migliore anziché creare ogni volta un nuovo FSimage, un'opzione migliore essendo in grado di archiviare i dati mentre un nuovo file per FSimage. FSimage crea una nuova istantanea ogni volta che vengono apportate modifiche Se il nodo Nome fallisce, può ripristinare il suo stato precedente. Il nodo del nome secondario può anche aggiornare la sua copia ogni volta che ci sono cambiamenti in FSimage e registri di modifica. Pertanto, assicura che anche se il nodo del nome è inattivo, in presenza del nodo del nome secondario non si verificherà alcuna perdita di dati. Il nodo del nome non richiede che queste immagini debbano essere ricaricate sul nodo del nome secondario.
Replica dei dati
HDFS è progettato per elaborare rapidamente i dati e fornire dati affidabili. Memorizza i dati su macchine e in cluster di grandi dimensioni. Tutti i file sono memorizzati in una serie di blocchi. Questi blocchi vengono replicati per la tolleranza agli errori. La dimensione del blocco e il fattore di replica possono essere decisi dagli utenti e configurati secondo i requisiti dell'utente. Per impostazione predefinita, il fattore di replica è 3. Il fattore di replica può essere specificato al momento della creazione del file e può essere modificato in un secondo momento. Tutte le decisioni relative a queste repliche sono prese dal nodo nome. Il nodo del nome continua a inviare heartbeat e blocca il report a intervalli regolari per tutti i nodi di dati nel cluster. La ricezione del battito cardiaco implica che il nodo dati funzioni correttamente. Il rapporto sui blocchi specifica l'elenco di tutti i blocchi presenti sul nodo dati.
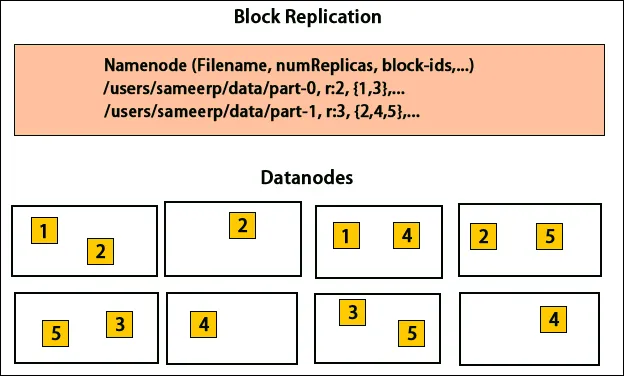
Collocazione di repliche
Il posizionamento delle repliche è un compito molto importante in Hadoop per affidabilità e prestazioni. Tutti i diversi blocchi di dati vengono posizionati su rack diversi. L'implementazione del posizionamento delle repliche può essere eseguita in base a affidabilità, disponibilità e utilizzo della larghezza di banda della rete. Il cluster di computer può essere distribuito su rack diversi. Non più di due nodi possono essere posizionati sullo stesso rack. La terza replica deve essere posizionata su un rack diverso per garantire una maggiore affidabilità dei dati. I due nodi sul rack comunicano attraverso diversi switch. Il nodo nome ha l'ID rack per ciascun nodo dati. Posizionare tutti i nodi su rack diversi impedisce la perdita di dati e consente l'utilizzo della larghezza di banda da più rack. Inoltre, riduce il traffico tra rack e migliora le prestazioni. Inoltre, la possibilità di errore del rack è molto inferiore rispetto a quella del nodo. Riduce la larghezza di banda aggregata della rete quando i dati vengono letti da due rack univoci anziché tre.
Riduci mappa
Map Reduce viene utilizzato per l'elaborazione dei dati archiviati su HDFS. Scrive dati distribuiti su applicazioni distribuite, garantendo un trattamento efficiente di grandi quantità di dati. Elaborano su cluster di grandi dimensioni e richiedono prodotti affidabili e resistenti ai guasti. Il nucleo di Map-ridurre può essere costituito da tre operazioni come la mappatura, la raccolta di coppie e il mescolamento dei dati risultanti.
Conclusione - Hadoop Architecture
Hadoop è un framework open source che aiuta in un sistema a tolleranza d'errore. Può archiviare grandi quantità di dati e aiuta a memorizzare dati affidabili. Le due parti della memorizzazione dei dati in HDFS e dell'elaborazione tramite map-riducono aiutano a lavorare in modo corretto ed efficiente. Ha un'architettura che aiuta a gestire tutti i blocchi di dati e ad avere anche la copia più recente memorizzandola in FSimage e modifica i log. Il fattore di replica aiuta anche ad avere copie dei dati e recuperarli ogni volta che si verifica un errore. HDFS sposta anche i file rimossi nella directory cestino per un utilizzo ottimale dello spazio.
Articoli consigliati
Questa è stata una guida all'architettura di Hadoop. Qui abbiamo discusso di architettura, riduzione delle mappe, posizionamento delle repliche, replica dei dati. Puoi anche consultare i nostri altri articoli suggeriti per saperne di più -
- Diventa uno sviluppatore Hadoop
- Introduzione ad Android
- Che cos'è il tableau? | Una panoramica
- Che cos'è MapReduce in Hadoop?