

Introduzione ai comandi suini
Apache Pig è uno strumento / piattaforma utilizzato per analizzare set di dati di grandi dimensioni ed eseguire lunghe serie di operazioni sui dati. Il maiale è usato con Hadoop. Tutti gli script di maiale vengono convertiti internamente in attività di riduzione della mappa e quindi eseguiti. Può gestire dati strutturati, semi-strutturati e non strutturati. Negozi di maiale, il suo risultato in HDFS. In questo articolo, impariamo più tipi di comandi suini.
Ecco alcune caratteristiche di Maiale:
- Auto-ottimizzazione: il maiale può ottimizzare i lavori di esecuzione, l'utente ha la libertà di concentrarsi sulla semantica.
- Facilità di programmazione: Pig fornisce un linguaggio / dialetto di alto livello noto come Pig Latin, che è facile da scrivere. Pig Latin fornisce molti operatori, che il programmatore può utilizzare per elaborare i dati. Il programmatore ha la flessibilità di scrivere anche le proprie funzioni.
- Estensibile: Pig facilita la creazione di funzioni personalizzate chiamate UDF (funzioni definite dall'utente), che rendono i programmatori in grado di soddisfare qualsiasi esigenza di elaborazione in modo facile e veloce. Lo script di maiale viene eseguito su una shell nota come grugnito.
Perché i comandi suini?
I programmatori che non sono bravi con Java, di solito hanno difficoltà a scrivere programmi in Hadoop, cioè a scrivere attività di riduzione delle mappe. Per loro, Pig Latin, che è abbastanza simile al linguaggio SQL, è un vantaggio. Il suo approccio multi-query riduce la lunghezza del codice.
Quindi nel complesso il suo modo conciso ed efficace di programmazione. I comandi di maiale possono invocare il codice in molte lingue come JRuby, Jython e Java.
L'architettura dei comandi suini
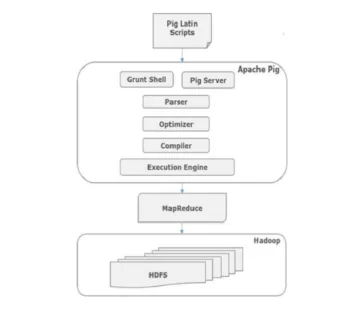
Tutti gli script scritti in Pig-Latin su grunt shell vanno al parser per controllare la sintassi e si verificano anche altri controlli vari. L'output del parser è un DAG. Questo DAG viene quindi passato all'ottimizzatore, che quindi esegue l'ottimizzazione logica come la proiezione e lo spinge verso il basso. Quindi il compilatore soddisfa il piano logico per i lavori MapReduce. Infine, questi lavori MapReduce vengono inviati a Hadoop in ordine ordinato. Questi lavori vengono eseguiti e producono i risultati desiderati.
Il modello di dati maiale-latino è completamente nidificato e consente tipi di dati complessi come mappa e tupla.
Qualsiasi singolo valore della lingua latina di maiale (indipendentemente dal tipo di dati) è noto come Atom.
Comandi di base del maiale
Diamo un'occhiata ad alcuni dei comandi Basic Pig che sono riportati di seguito: -
1. Fs: questo elencherà tutti i file nell'HDFS
grugnito> fs –ls
2. Cancella: questo cancellerà la shell Grunt interattiva.
grugnito> chiaro
3. Storia:
Questo comando mostra i comandi eseguiti finora.
grugnito> storia
4. Lettura dei dati: supponendo che i dati risiedano in HDFS e che dobbiamo leggere i dati su Pig.
grunt> college_students = LOAD 'hdfs: // localhost: 9000 / pig_data / college_data.txt'
USANDO PigStorage (', ')
as (id: int, nome: chararray, cognome: chararray, telefono: chararray,
città: chararray);
PigStorage () è la funzione che carica e archivia i dati come file di testo strutturati.
5. Memorizzazione dei dati: l'operatore di memorizzazione viene utilizzato per archiviare i dati elaborati / caricati.
grunt> STORE college_students INTO 'hdfs: // localhost: 9000 / pig_Output /' USING PigStorage (', ');
Qui, "/ pig_Output /" è la directory in cui è necessario memorizzare la relazione.
6. Operatore di dump: questo comando viene utilizzato per visualizzare i risultati sullo schermo. Di solito aiuta nel debug.
grugnito> Dump college_students;
7. Descrivi l'operatore: aiuta il programmatore a visualizzare lo schema della relazione.
grugnito> descrivi college_students;
8. Spiegazione: questo comando aiuta a rivedere i piani di esecuzione logici, fisici e di riduzione delle mappe.
grugnito> spiega college_students;
9. Illustratore dell'operatore: fornisce un'esecuzione dettagliata delle istruzioni nei comandi suino.
grugnito> illustrare college_students;
Comandi di maiale intermedi
1. Raggruppa: questo comando Pig consente di raggruppare i dati con la stessa chiave.
grunt> group_data = GROUP college_students per nome;
2. COGROUP: funziona in modo simile all'operatore del gruppo. La principale differenza tra l'operatore del gruppo e del gruppo di appartenenza è che l'operatore del gruppo viene generalmente utilizzato con una relazione, mentre il gruppo di appartenenza viene utilizzato con più di una relazione.
3. Partecipa: viene utilizzato per combinare due o più relazioni.
Esempio: per eseguire l'auto-join, diciamo che la relazione "cliente" viene caricata dai comandi HDFS tp pig in due relazioni clienti1 e clienti2.
grunt> customers3 = UNISCITI ai clienti1 PER ID, clienti2 PER ID;
Join potrebbe essere self-join, Inner-join, Outer-join.
4. Incrocio: questo comando suino calcola il prodotto incrociato di due o più relazioni.
grunt> cross_data = CROSS clienti, ordini;
5. Unione: unisce due relazioni. La condizione per l'unione è che sia le colonne che i domini della relazione devono essere identici.
grugnito> studente = UNIONE studente1, studente2;
Comandi avanzati suino
Diamo un'occhiata ad alcuni dei comandi avanzati di Pig che sono riportati di seguito:
1. Filtro: aiuta a filtrare le tuple fuori relazione, in base a determinate condizioni.
filter_data = FILTER college_students PER città == 'Chennai';
2. Distinto: aiuta a rimuovere le tuple ridondanti dalla relazione.
grunt> distinct_data = DISTINCT college_students;
Questo filtro creerà un nuovo nome di relazione "distinto_data"
3. Foreach: aiuta a generare la trasformazione dei dati in base ai dati delle colonne.
grunt> foreach_data = FOREACH student_details ID GENERALE, età, città;
Ciò otterrà i valori id, età e città di ogni studente dalla relazione student_details e quindi lo memorizzerà in un'altra relazione chiamata foreach_data.
4. Ordina per: questo comando visualizza il risultato in un ordine ordinato basato su uno o più campi.
grunt> order_by_data = ORDINA college_students per età DESC;
Questo ordinerà la relazione "college_students" in ordine decrescente per età.
5. Limite: questo comando viene limitato n. di tuple dalla relazione.
grunt> limit_data = LIMIT student_details 4;
Suggerimenti e trucchi
Di seguito sono riportati i diversi suggerimenti e trucchi dei comandi Pig: -
1. Abilita la compressione su input e output:
impostare input.compression.enabled vero;
impostare output.compression.enabled vero;
Le righe di codice sopra menzionate devono essere all'inizio dello Script, in modo che i comandi Pig possano leggere i file compressi o generare file compressi come output.
2. Unisci più relazioni:
Per eseguire il join sinistro su diciamo tre relazioni (input1, input2, input3), è necessario optare per SQL. È perché il join esterno non è supportato da Pig su più di due tabelle.
Piuttosto ti esibisci a sinistra per unirti in due passaggi come:
data1 = JOIN input1 Tasto BY SINISTRA, input2 Tasto BY ;
data2 = JOIN data1 BY input1 :: chiave LEFT, input3 chiave BY ;
Ciò significa due lavori di riduzione della mappa.
Per eseguire l'attività sopra descritta in modo più efficace, si può optare per "Cogroup". Il cogroup può unire più relazioni. Il cogroup per impostazione predefinita fa il join esterno.
Conclusione
Il maiale è un linguaggio procedurale, generalmente utilizzato dai data scientist per eseguire elaborazioni ad hoc e prototipazione rapida. È un ottimo ETL e un grande strumento di elaborazione dei dati. Gli script di maiale possono essere invocati da altre lingue e viceversa. Quindi i comandi di maiale possono essere utilizzati per creare applicazioni più grandi e complesse.
Articoli consigliati
Questa è stata una guida ai comandi di Pig. Qui abbiamo discusso i comandi Pig di base e avanzati e alcuni comandi Pig immediati. Puoi anche leggere il seguente articolo per saperne di più -
- Comandi Adobe Photoshop
- Comandi del tableau
- Cheat sheet SQL (comandi, suggerimenti gratuiti e trucchi)
- Comandi VBA-Tocchi finali
- Diverse operazioni relative alle tuple