
Differenza tra HBase e Cassandra
HBase è un database che utilizza il file system distribuito Hadoop per la sua memorizzazione. HBase è una parte importante di HDFS e funziona su Hadoop Cluster. HBase non è un database relazionale tradizionale, richiede un diverso approccio alla modellazione dei dati. Cassandra lavora sul modello di replica dei dati, quindi in caso di indisponibilità di qualsiasi nodo non si verificherà alcuna perdita di dati. Cassandra è un database distribuito che consente ai client di accedere ai dati da qualsiasi cluster e da qualsiasi nodo
1.1) Cassandra:
È stato avviato da Facebook perché è sempre necessario per l'applicazione. Cassandra è stato avviato nel 2005 e reso disponibile al pubblico nel 2008. Cassandra è stato sviluppato per applicazioni sempre attive come social network come Facebook e Twitter.
Cassandra lavora su un'architettura “sempre attiva” e ha un modello di nodo Active-Active quindi non c'è SPoF (Single point of failure). CQL (Cassandra Query Language) è il linguaggio di query di Cassandra ma con la stessa sintassi di SQL. Supporta tutti i principali sistemi operativi come Linux, Unix, OSX e Windows.
Sempre acceso:
Cassandra è un database con un modello di distribuzione e tutti i nodi sono uguali all'interno del cluster. I dati vengono replicati su nodi configurabili, quindi in caso di errore di alcuni no. dei nodi non comporterà la perdita dei dati.
(Sempre sul modello)
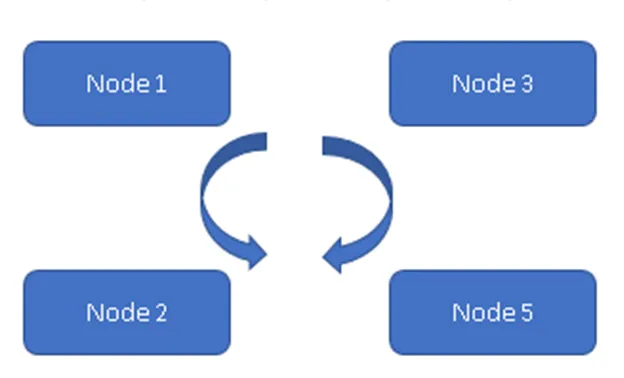
Nella figura 1, tutti e quattro i nodi sono sincronizzati tra loro e replicano i dati all'interno del cluster. Tutti stanno lavorando sul modello Active-Active, quindi in caso di guasti al nodo non si avrà una perdita di dati. Un client può leggere i dati dal resto del nodo / nodi disponibili.
1.2) HBase:
HBase è un database NoSQL e progettato per l'elaborazione di query in tabelle di grandi dimensioni con miliardi di righe con milioni di colonne e eseguito su un cluster di hardware normale / di base. Offre funzionalità di query in tempo reale con la velocità di un " archivio chiave / valore " .
HBase attualmente si basa / lavora su un modello di dati a quattro dimensioni.
- ID riga / Chiave riga
- Famiglia di colonne.
- Coppie chiave-valore.
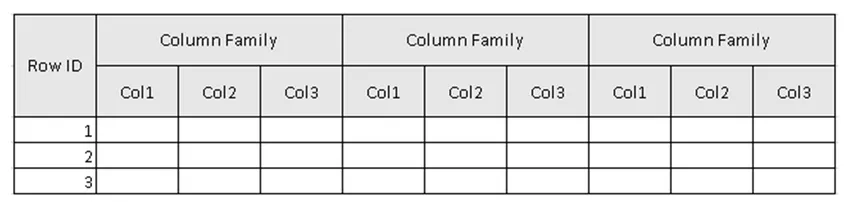
(Figura 2, Esempio di schema della tabella in HBase.)
Nella figura 2, Tabella è la raccolta di colonne Famiglia e colonna è la raccolta di colonne. Le colonne sono la raccolta di coppie chiave-valore
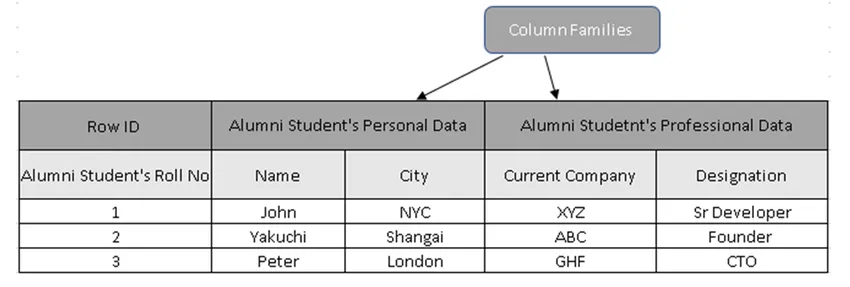
(Figura 3, Tabella di esempio in HBase)
Nella Figura 3, le famiglie di colonne sono la raccolta di dati degli studenti Alumni e gli ID di riga (Row Keys) contengono il numero dello studente.
In realtà, le chiavi di riga mantengono il valore univoco rispetto ai dati della famiglia di colonne. Utilizzando la chiave di riga, è possibile estrarre tutti i dettagli, motivi per cui i database orientati alla colonna sono molto più veloci dei database tradizionali.
Apache HBase può essere utilizzato per l'accesso in lettura / scrittura casuale e fornisce supporto per gli errori. Supporta inoltre la replica e il lavoro sul modello di database di distribuzione.
Confronto diretto tra HBase e Cassandra (infografica)
Di seguito è la differenza 9 principale tra HBase vs Cassandra
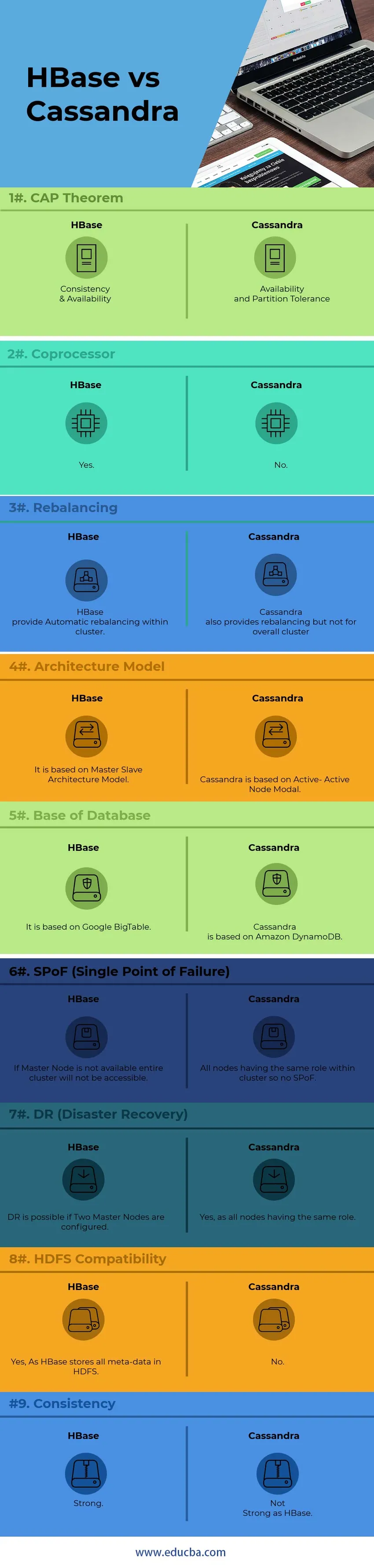 Differenze chiave tra HBase e Cassandra
Differenze chiave tra HBase e Cassandra
Di seguito sono riportati gli elenchi di punti, descrivono le principali differenze tra HBase e Cassandra:
1) Per la comunicazione interna dei nodi, Cassandra utilizza il protocollo GOSSIP mentre HBase si basa su Zookeeper. I servizi del protocollo GOSSIP sono integrati con l'altro lato Cassandra Zookeeper è un'applicazione di distribuzione completamente separata.
2) Nell'architettura Cassandra, Tutti i nodi funzionano come Nodo attivo mentre l'architetto HBase segue il modello Nodo Master-Slave. Nel modello Nodo attivo-attivo, non esiste alcun SPoF (punto singolo di errore). In HBase, se il nodo Master scende, l'intero cluster non sarà accessibile.
3) Supporto HBase Modello di ricerca dell'albero binario mentre Cassandra non supporta il modello B-Tree Senza B-Tree, non puoi cercare la famiglia di colonne dell'utente per tutti con un anniversario ad aprile mentre puoi cercare tutti coloro che vivono a Pechino con un Anniversario ad aprile.
4) HBase, supporta i linguaggi di scripting C, C ++, Java, Python, Scala mentre Cassandra supporta anche JavaScript e Ruby.
5) HBase sta avendo una funzione chiamata come coprocessori mentre Cassandra non ha tale funzione al momento. I coprocessori forniscono una libreria e un ambiente di runtime per l'esecuzione del codice utente all'interno del server della regione HBase e dei processi master.
6) HBase è progettato per supportare il data warehouse mentre Cassandra sarà perfetto per le applicazioni sempre attive come Web e applicazioni mobili.
7) Il linguaggio di query HBase è un linguaggio personalizzato che deve essere appreso mentre Cassandra utilizza il proprio CQL (Cassandra Query Language) sviluppato che è un linguaggio simile a SQL
8) Gestire Cassandra è molto più semplice di HBase. In Cassandra, è necessario eseguire un singolo processo Java per nodo mentre per HBase sono necessari HDFS completamente operativi, diversi processi HBase e un sistema Zookeeper.
9) HBase completa i checksum e il riequilibrio automatico mentre Cassandra non supporta il riequilibrio del cluster in generale.
10) Basato sul " Teorema del CAP", Cassandra lavora sul modello AP mentre HBase è il modello CP.
Teorema della PAC
Questo teorema è usato per sistemi distribuiti. C sta per coerenza, A significa disponibilità e P è tolleranza di partizione. Teorema della CAP spiegato di seguito:
C (Coerenza): coerenza significa che se qualcuno ha scritto un valore in un database, altri possono leggere immediatamente lo stesso valore.
A (Disponibilità) : disponibilità significa che alcuni nodi non sono disponibili nel cluster (i nodi sono stati disattivati / non vivono nel cluster a causa di un problema) non influiranno sull'intero cluster e il sistema distribuito / database sarà disponibile per accedere ai dati. Il cluster sarà accessibile per tutti i tipi di attività.
P (Tolleranza partizione): Tolleranza partizione indica se un Data Center scende, ciò non dovrebbe influire sui dati presenti sui nodi e tutti i dati dovrebbero essere accessibili in qualsiasi momento. Significa che la tolleranza della partizione consente una migliore replica dei dati su altri Data Center e all'interno dell'ambiente cluster.
Tabella comparativa HBase vs Cassandra
| Punti | HBase | cassandra |
| Teorema della PAC | Coerenza e disponibilità | Tolleranza su disponibilità e partizioni |
| Coprocessore | sì | No |
| riequilibrio | HBase fornisce il ribilanciamento automatico all'interno di un cluster. | Cassandra fornisce anche il riequilibrio, ma non per il cluster complessivo |
| Modello di architettura | Si basa sul modello di architettura Master-Slave | Cassandra si basa su Modale nodo attivo-attivo |
| Base del database | Si basa su Google BigTable | Cassandra si basa su Amazon DynamoDB |
| SPoF (Single Point of Failure) | Se il nodo principale non è disponibile, l'intero cluster non sarà accessibile | Tutti i nodi hanno lo stesso ruolo all'interno del cluster, quindi non SPoF |
| DR (Disaster Recovery) | DR è possibile se sono configurati due nodi master. | Sì, poiché tutti i nodi hanno lo stesso ruolo |
| Compatibilità HDFS | Sì, poiché HBase memorizza tutti i metadati in HDFS | No |
| Consistenza | Forte | Non forte come HBase |
Conclusione - HBase vs Cassandra
Facebook e un altro lato del social network preferirebbero HBase (in precedenza entrambi utilizzavano Cassandra, fare riferimento a post di Facebook) a causa della sua disponibilità, l'altro settore del dominio bancario laterale cerca sicurezza per ogni sua transazione finanziaria, quindi selezionerebbero Cassandra su HBase.
Le caratteristiche chiave di Cassandra comprendono Alta Disponibilità, Amministrazione minima e Nessun SPoF (Single Point of Failure). L'altro lato HBase è buono per leggere e scrivere più velocemente i dati con scalabilità lineare.
Aziende come Verizon, Bloomberg, Bank of America e molte altre utilizzano HBase e Cassandra viene utilizzata dai principali siti di social network come Twitter, Facebook ecc …
Non possiamo concludere quale sia il migliore, sia HBase che Cassandra stanno avendo i loro vantaggi e svantaggi. Le prestazioni effettive dei database HBase e Cassandra sono visibili nell'ambiente di produzione.
Articoli consigliati:
Questa è stata una guida per HBase vs Cassandra, il loro significato, confronto testa a testa, differenze chiave, tabella di confronto e conclusioni. Puoi anche consultare i seguenti articoli per saperne di più -
- Hadoop vs Apache Spark - Cose interessanti che devi sapere
- Come rompere l'intervista allo sviluppatore di Hadoop?
- Le 5 principali tendenze dei Big Data
- 5 sfide di Big Data Analytics