

Che cos'è Kafka?
Per capire Kafka, è meglio capire cos'è la tecnologia di "Stream processing". 'L'elaborazione del flusso è una tecnologia che utilizza un utente per interrogare un flusso di dati continuo in un micro intervallo di tempo per comprendere meglio le condizioni sottostanti responsabili.
Uno scenario in tempo reale: immagina se il tuo sensore di temperatura invia dati che puoi interrogare e ricevere un avviso dopo aver ricevuto un punto di congelamento. Questa query di dati può essere eseguita in microsecondi.
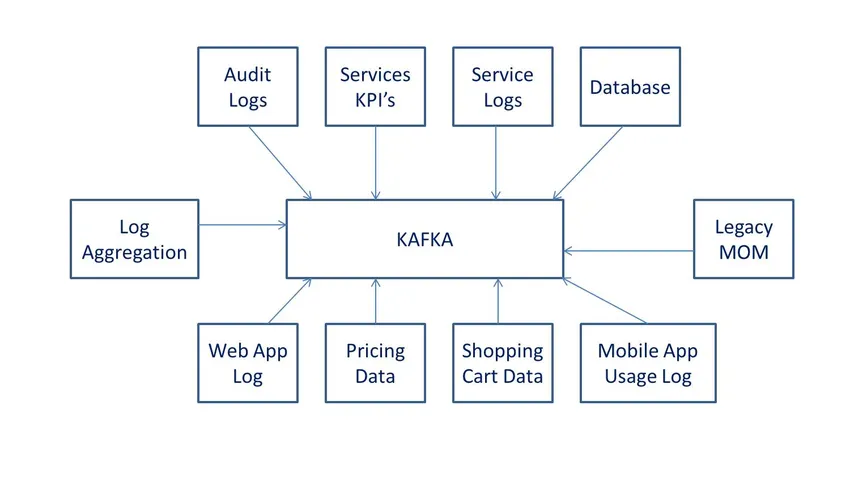
definizioni
secondo Wiki, è un software di elaborazione dati open source. È stato sviluppato da LinkedIn e successivamente donato al software Apache.
Capire Kafka
La sua crescita sta esplodendo in modo esponenziale. Vediamo alcuni fatti e statistiche per sottolineare meglio il nostro pensiero. Gode della preferenza principale di oltre un terzo della Fortune 500 in tutto il mondo. Questa distribuzione è condivisa da compagnie di viaggio, giganti delle telecomunicazioni, banche e molti altri. LinkedIn, Microsoft e Netflix elaborano messaggi a quattro virgole al giorno con Kafka (quasi equivalgono a 1.000.000.000.000).
Viene utilizzato per flussi di dati in tempo reale, per raccogliere dati di grandi dimensioni o per eseguire analisi in tempo reale (o entrambi). Kafka viene utilizzato con microservizi in memoria per garantire durata e può essere utilizzato per alimentare eventi in sistemi di automazione in stile CEP (eventi complessi) e IoT / IFTTT.
Come funziona Kafka così facilmente?
Spinto dalla semplicità sarebbe il modo giusto per definire le prestazioni. È facile capire come Kafka funzioni con tale facilità dalla sua configurazione e utilizzo. Questa maggiore prestazione nel comportamento è dedicata alla sua stabilità, alla sua affidabilità e durata, con la sua capacità integrata flessibile di pubblicare o abbonarsi o fare la coda di manutenzione. Questo è molto cruciale se hai bisogno di trattare con un numero N di gruppi di clienti, se devi mostrare una solida replica sul mercato, mirata a fornire ai tuoi clienti un approccio coerente (ad esempio la partizione di argomenti Kafka). Un comportamento cruciale di Kafka che lo distingue dai suoi concorrenti è la sua compatibilità con i sistemi con flussi di dati - il suo processo e abilita questi sistemi al fine di aggregare, trasformare e caricare altri negozi per comodità di lavoro. "Tutti i fatti sopra menzionati non sarebbero possibili se Kafka fosse lento". Le sue eccezionali prestazioni lo rendono possibile.
Con un'ulteriore aggiunta per facilitare il funzionamento di Kafka, dobbiamo passare a "Livello OS". Scopriamo come funzionano le cose per Kafka a livello di sistema operativo -
- Si basa sui kernel del sistema operativo per spostare i dati più rapidamente e funziona secondo il principio della copia zero.
- Consente ai record di dati di essere raggruppati in blocchi che possono essere visualizzati dal file system (alias log degli argomenti di Kafka) per i consumatori.
- La possibilità di raggruppare i dati offre una compressione efficiente dei dati con riduzione della latenza I / O.
- Ha la capacità di ridimensionare orizzontalmente tramite sharding. Può suddividere un registro titoli in centinaia di partizioni a migliaia. Ciò gli consente di gestire facilmente l'enorme carico di lavoro.
Cosa puoi fare con Kafka?
Se la tua azienda gioca regolarmente con enormi quantità di dati, hai bisogno di Kafka. C'è un lungo elenco di aziende che lo utilizzano.
- LinkedIn utilizza per tenere traccia dei dati e delle metriche operative.
- Twitter per fornire infrastrutture di elaborazione del flusso.
C'è una lunga lista di aziende da Uber a Spotify e Goldman Sachs a Cisco.
vantaggi
- Alta produttività: può facilmente gestire un grande volume di dati quando la generazione ad alta velocità è un vantaggio eccezionale a favore di Kafka. Questa applicazione manca di hardware enorme. Con la capacità di supportare la velocità di trasmissione dei messaggi con una frequenza di migliaia di messaggi al secondo.
- Bassa latenza: bassa latenza che gestisce questa generazione di messaggi ad alto volume.
- Tolleranza agli errori: questa funzione è molto utile, ha una capacità intrinseca di essere limitata dal nodo incorporato in un cluster.
- Durevole: è molto resistente nel suo funzionamento ed è per questo che molti MNC preferiscono usare Kafka. Parlando di durabilità nelle operazioni, i messaggi non possono perdersi a lungo termine.
Competenze richieste
Non esiste un requisito speciale per essere un professionista di Kafka. Ma abbiamo sottolineato alcuni flussi e professionisti -
- Gli sviluppatori che vogliono fare volontariamente una carriera nel flusso di Big Data e vogliono accelerare la loro carriera.
- I test professionali hanno una buona portata in Kafka in termini di sistemi di accodamento e messaggistica
- Architetti - poiché tutto ha bisogno di un framework e questo framework può essere aggiornato di volta in volta. Gli architetti di Big Data troverebbero Kafka come un buon investimento professionale.
- Il Project Manager è necessario se il professionista di cui sopra è lì per una migliore gestione delle risorse. Pertanto, sono disponibili anche posizioni più elevate per i professionisti della gestione nel campo di Kafka.
Perché usare Kafka?
Ai fini del tracciamento e della manipolazione dei dati secondo le esigenze aziendali, Kafka è preferito in tutto il mondo. Offre la possibilità di trasmettere i dati in tempo reale con analisi in tempo reale. È veloce, scalabile e durevole e progettato come tolleranza ai guasti. Esistono più casi d'uso presenti sul Web in cui è possibile capire perché JMS, RabbitMQ e AMQP non sono nemmeno considerati compatibili con la necessità di operare con volumi e reattività enormi.
Ha un throughput elevato, un'installazione affidabile con caratteristiche di replica che lo rende una scelta preferibile per lavorare sui sensori IoT.
La compatibilità è un altro motivo per usarlo e renderlo accettabile in tutto il mondo. Può essere facilmente configurato per funzionare con l'applicazione elencata di seguito. Questa combinazione è molto vitale per molte aziende per far crescere gli affari e sopravvivere (in quanto consente di risparmiare tempo e denaro).
- canale artificiale
- Spark Streaming
- HBase
- Spark per l'ingestione, l'elaborazione e l'analisi dei dati in tempo reale.
- È usato per alimentare Hadoop BigData
Scopo
Sta andando alla grande in tutto il mondo. Bene, non stiamo dicendo questo piuttosto di statistiche. Diamo un'occhiata -
Statistiche salariali per i professionisti di Kafka - PayScale
- Ingegnere del software - $ 109, 825
- Ingegnere di dati - $ 109.580
- Sviluppatori - $ 81.182
- Ingegnere senior dei dati - $ 127, 836
Conclusione
Al momento Kafka è diventato lo standard di fatto quando si tratta di analisi dei dati in tempo reale con la massima precisione in microsecondi. Abbiamo presentato le nostre intuizioni in termini di dati e dettagli a supporto delle tecnologie Kafka. Ci sono diverse grandi aziende che sfruttano i dati su base giornaliera, per fare ciò hanno bisogno di professionisti per sfruttare questi enormi set di dati. Con Kafka, si può essere certi di condurre la propria carriera nell'analisi dei BigData
Articoli consigliati
Questa è stata una guida a What is Kafka. Qui abbiamo discusso di funzionamento, portata, crescita della carriera e vantaggi di Kafka. Puoi anche consultare i nostri altri articoli suggeriti per saperne di più -
- Che cos'è Apache?
- Che cos'è Big Data e Hadoop?
- Che cos'è Azure?
- Che cos'è la tecnologia dei Big Data?
- Kafka vs Spark | Le 5 differenze principali
- Panoramica e principali applicazioni di Kafka
- Kafka vs Kinesis | 5 differenze con l'infografica