

Introduzione ai comandi Spark
Apache Spark è un framework basato su Hadoop per calcoli veloci. Estende il concetto di MapReduce nello scenario basato su cluster per eseguire in modo efficiente un'attività. Spark Command è scritto in Scala.
Spark può essere utilizzato da Spark nei seguenti modi (vedi sotto):
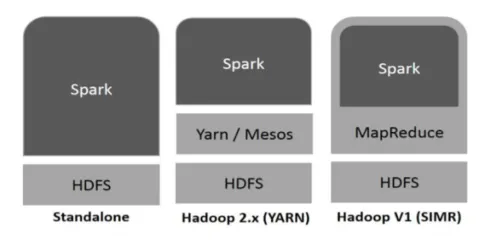
Fig. 1
https://www.tutorialspoint.com/
- Autonomo: Spark distribuito direttamente su Hadoop. I lavori Spark vengono eseguiti in parallelo su Hadoop e Spark.
- Hadoop YARN: Spark gira su Yarn senza la necessità di alcuna preinstallazione.
- Spark in MapReduce (SIMR): Spark in MapReduce viene utilizzato per avviare il processo spark, oltre alla distribuzione autonoma. Con SIMR è possibile avviare Spark e utilizzare la sua shell senza alcun accesso amministrativo.
Componenti di Spark:
- Apache Spark Core
- Spark SQL
- Spark Streaming
- MLIB
- Graphx
Resilient Distributed Dataset (RDD) è considerata la struttura dati fondamentale dei comandi Spark. RDD è immutabile e di sola lettura in natura. Tutti i tipi di calcoli nei comandi spark vengono eseguiti tramite trasformazioni e azioni su RDD.
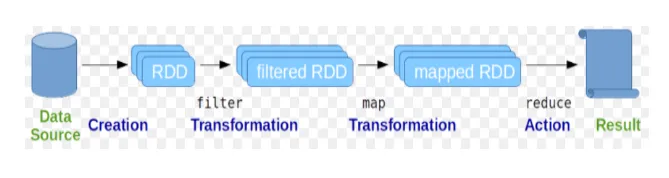
Fig 2
Immagine google
Spark shell fornisce agli utenti un mezzo per interagire con le sue funzionalità. I comandi Spark hanno molti comandi diversi che possono essere utilizzati per elaborare i dati sulla shell interattiva.
Comandi spark di base
Diamo un'occhiata ad alcuni dei comandi Basic Spark che sono riportati di seguito: -
-
Per avviare la shell Spark:

Fig 3
-
Leggi il file dal sistema locale:

Qui "sc" è il contesto della scintilla. Considerando che "data.txt" si trova nella home directory, viene letto in questo modo, altrimenti è necessario specificare il percorso completo.
-
Crea RDD attraverso la parallelizzazione

NewData è RDD ora.
-
Conta articoli in RDD

-
Raccogliere
Questa funzione restituisce tutto il contenuto di RDD al programma del driver. Ciò è utile per il debug in vari passaggi del programma di scrittura.
-
Leggi i primi 3 articoli da RDD

-
Salva i dati di output / elaborati nel file di testo

Qui la cartella "output" è il percorso corrente.
Comandi di accensione intermedi
1. Filtro su RDD
Creiamo un nuovo RDD per gli elementi che contengono "sì".

Il filtro di trasformazione deve essere chiamato sul RDD esistente per filtrare sulla parola "sì", che creerà un nuovo RDD con il nuovo elenco di elementi.
2. Funzionamento a catena

Qui la trasformazione del filtro e l'azione di conteggio agiscono insieme. Questo si chiama operazione a catena.
3. Leggi il primo elemento da RDD

4. Contare le partizioni RDD
Come sappiamo, RDD è composto da più partizioni, si verifica la necessità di contare il no. di partizioni. Come aiuta nell'ottimizzazione e nella risoluzione dei problemi mentre si lavora con i comandi Spark.

Per impostazione predefinita, minimo n. la partizione pf è 2.
5. unisciti
Questa funzione unisce due tabelle (l'elemento table è a coppie) in base alla chiave comune. In RDD a coppie, il primo elemento è la chiave e il secondo elemento è il valore.
6. Memorizzare nella cache un file
La memorizzazione nella cache è una tecnica di ottimizzazione. La memorizzazione nella cache di RDD significa che RDD risiederà in memoria e tutto il calcolo futuro verrà eseguito su quei RDD in memoria. Risparmia il tempo di lettura del disco e migliora le prestazioni. In breve, riduce il tempo di accesso ai dati.

Tuttavia, i dati non verranno memorizzati nella cache se si esegue la funzione sopra. Questo può essere dimostrato visitando la pagina Web:
http: // localhost: 4040 / storage
RDD verrà memorizzato nella cache, una volta completata l'azione. Per esempio:

Un'altra funzione che funziona in modo simile a cache () è persist (). Persist offre agli utenti la flessibilità di fornire l'argomento, il che può aiutare i dati a essere memorizzati nella memoria, disco o memoria off-heap. Persistere senza alcun argomento funziona come cache ().
Comandi spark avanzati
Diamo un'occhiata ad alcuni dei comandi Spark avanzati che sono riportati di seguito: -
-
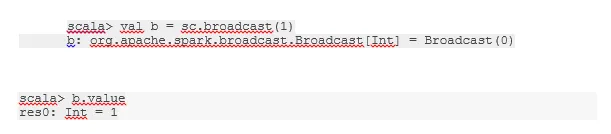
Trasmetti una variabile
La variabile Broadcast aiuta il programmatore a continuare a leggere l'unica variabile memorizzata nella cache su ogni macchina nel cluster, piuttosto che spedire una copia di quella variabile con le attività. Questo aiuta a ridurre i costi di comunicazione.
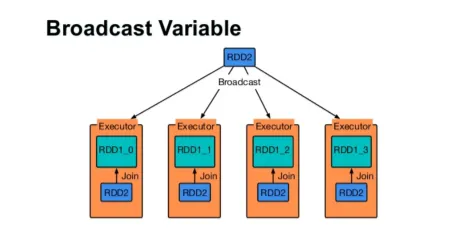
Fig 4
Immagine google
In breve, ci sono tre caratteristiche principali della variabile Broadcasted:
- Immutabile
- Adatta alla memoria
- Distribuito su cluster
-
accumulatori
Gli accumulatori sono le variabili che vengono aggiunte alle operazioni associate. Ci sono molti usi per accumulatori come contatori, somme ecc.

Il nome dell'accumulatore nel codice potrebbe essere visualizzato anche nell'interfaccia utente di Spark.
-
Carta geografica
La funzione Mappa aiuta a scorrere su ogni linea in RDD. La funzione utilizzata nella mappa viene applicata a tutti gli elementi in RDD.
Ad esempio, in RDD (1, 2, 3, 4, 6) se applichiamo "rdd.map (x => x + 2)" otterremo il risultato come (3, 4, 5, 6, 8).
-
Flatmap
Flatmap funziona in modo simile alla mappa, ma map restituisce solo un elemento mentre flatmap può restituire l'elenco di elementi. Quindi, dividere le frasi in parole avrà bisogno di una mappa piatta.
-
Coalesce
Questa funzione aiuta a evitare il mescolamento dei dati. Questo viene applicato nella partizione esistente in modo che venga mischiato meno dati. In questo modo, possiamo limitare l'utilizzo dei nodi nel cluster.
Suggerimenti e trucchi per utilizzare i comandi spark
Di seguito sono riportati i diversi suggerimenti e trucchi dei comandi Spark: -
- I principianti di Spark possono usare Spark-shell. Dato che i comandi Spark sono basati su Scala, sicuramente usare Scala Spark Shell è fantastico. Tuttavia, è disponibile anche Spark Python Spark, quindi anche qualcosa che si può usare, che è esperto di Python.
- Spark shell ha molte opzioni per gestire le risorse del cluster. Sotto il comando puoi aiutarti in questo:

- In Spark, lavorare con set di dati lunghi è la solita cosa. Ma le cose vanno male quando viene preso un input errato. È sempre una buona idea eliminare le righe errate usando la funzione filtro di Spark. Il buon set di input sarà un grande passo avanti.
- Spark sceglie una buona partizione per i tuoi dati. Ma è sempre una buona pratica tenere d'occhio le partizioni prima di iniziare il lavoro. Provare diverse partizioni ti aiuterà con il parallelismo del tuo lavoro.
Conclusione - Comandi Spark:
Il comando Spark è un motore rivoluzionario e versatile per i big data, che può funzionare per l'elaborazione batch, l'elaborazione in tempo reale, la memorizzazione nella cache dei dati, ecc. Spark ha un ricco set di librerie di Machine Learning che possono consentire ai data scientist e alle organizzazioni analitiche di costruire potenti, interattivi e applicazioni veloci.
Articoli consigliati
Questa è stata una guida ai comandi Spark. Qui abbiamo discusso i comandi Spark base e avanzata e alcuni comandi Spark immediati. Puoi anche leggere il seguente articolo per saperne di più -
- Comandi Adobe Photoshop
- Comandi VBA importanti
- Comandi del tableau
- Cheat sheet SQL (comandi, suggerimenti gratuiti e trucchi)
- Tipi di join in Spark SQL (esempi)
- Componenti Spark | Panoramica e primi 6 componenti