

Che cos'è Big Data e Hadoop?
I dati crescono in modo esponenziale ogni giorno e con tali dati in crescita arriva la necessità di utilizzare tali dati. Come nei vecchi tempi, avevamo unità floppy per archiviare i dati e anche il trasferimento dei dati era lento, ma al giorno d'oggi questi sono insufficienti e l'archiviazione cloud viene utilizzata in quanto abbiamo terabyte di dati. Nel mondo di oggi, abbiamo i social media che contribuiscono maggiormente alla crescita dei dati. Consiste nel comportamento, nella mentalità e in molti altri aspetti delle persone. Si dice che in ogni minuto 300 ore di video vengano caricate su YouTube, oltre 20 milioni di foto vengono caricate su Facebook e molte altre. Inoltre, non esiste una struttura adeguata dei dati caricati che rappresenta la sfida maggiore per l'elaborazione di tali dati.
Dato che enormi dati vengono generati ad alta velocità, i sistemi RDBMS tradizionali non sono stati in grado di gestire una crescita così rapida. Inoltre, non sono in grado di gestire dati non strutturati. È diventato molto difficile gestire un'enorme quantità di dati eterogenei in rapida crescita e elaborarli con un'elevata velocità di elaborazione. Pertanto, è emersa la necessità di un sistema di questo tipo in grado di gestire in modo efficiente grandi serie di dati. Quindi, per risolvere lo scenario Hadoop è nato. HDFS è il componente di Hadoop che ha affrontato il problema di archiviazione del set di dati di grandi dimensioni utilizzando l'archiviazione distribuita mentre YARN è il componente che ha risolto il problema di elaborazione riducendo drasticamente i tempi di elaborazione.
Hadoop è un framework software open source per l'archiviazione e l'elaborazione di set di dati di grandi dimensioni utilizzando un cluster distribuito di hardware di largo consumo. È stato sviluppato da Doug Cutting e Michael J. Cafarella e concesso in licenza con Apache. È stato scritto utilizzando Java ed è stato sviluppato sulla base del documento scritto da Google sul sistema MapReduce e applica concetti di programmazione funzionale. È affidabile, economico, flessibile e scalabile.
I componenti principali di Hadoop
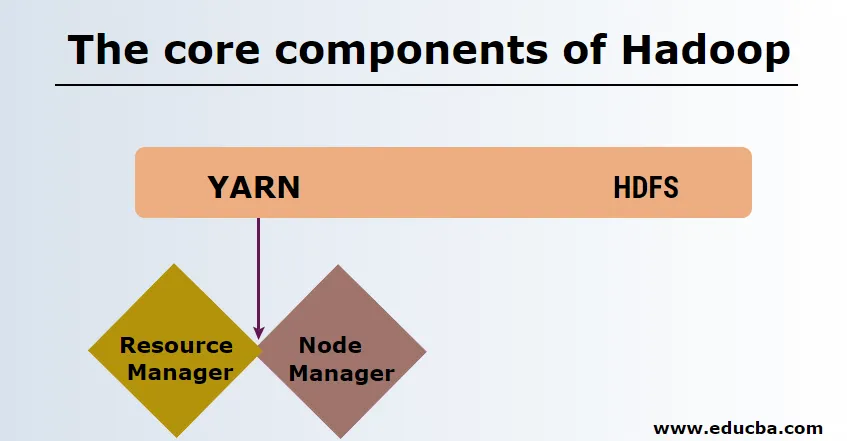
I componenti principali di Hadoop sono i seguenti
-
HDFS
HDFS o Hadoop Distributed File System hanno Namenode e nodo dati. Namenode è il nodo principale che esegue il demone principale e gestisce i nodi di dati e tiene traccia di tutte le operazioni. I datanodes sono gli slave in cui i dati sono effettivamente memorizzati.
-
FILATO
FILATO è costituito da due componenti principali:
1. ResourceManager: funziona sul nodo principale e gestisce tutte le risorse e pianifica tutte le applicazioni. Ha Scheduler e ApplicationManager.
2. NodeManager: funziona su ciascun nodo slave ed è responsabile della gestione dei contenitori e del monitoraggio dell'utilizzo delle risorse.
Diversi componenti di Hadoop
Esistono diversi componenti di Hadoop come il maiale, l'alveare, lo squalo, il canale, il mahout, l'oozie, il guardiano dello zoo, l'HBase, ecc.
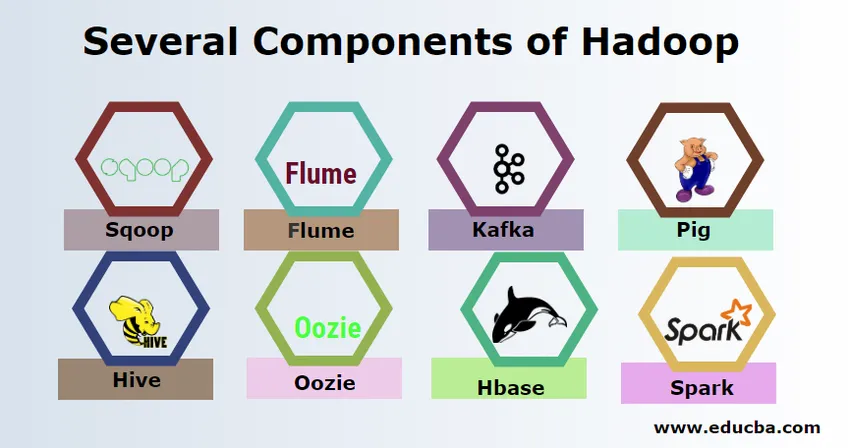
- Sqoop: viene utilizzato per importare ed esportare dati da RDBMS a Hadoop e viceversa.
- Flume - Viene utilizzato per estrarre dati in tempo reale in Hadoop.
- Kafka - È un sistema di messaggistica utilizzato per instradare i dati in tempo reale su Hadoop.
- Maiale : viene utilizzato come linguaggio di scripting per l'elaborazione dei dati.
- Hive : è un framework di data warehousing basato su HDFS in modo che gli utenti che hanno familiarità con SQL possano eseguire query per ottenere i dati. Queste query sono chiamate HiveQL.
- Oozie : viene utilizzato per pianificare il flusso di lavoro dei lavori da eseguire su eventi o orari specifici.
- Hbase - È il database senza SQL fornito come parte di Apache Hadoop.
- Spark - Viene utilizzato per eseguire l'elaborazione in memoria che è molto più veloce della riduzione della mappa di Hadoop.
Fornitori di Hadoop
Ci sono molte aziende che offrono distribuzioni Hadoop. Di seguito sono riportati alcuni dei migliori fornitori di Hadoop:
- Cloudera
- Hortonworks
- MAPR
Ci sono alcuni prerequisiti per l'apprendimento di Hadoop. È necessaria una precedente esperienza in Java e nel linguaggio di scripting. Sebbene Hadoop abbia già i suoi linguaggi di programmazione di alto livello come pig e hive che generano il codice di backend per ulteriori elaborazioni, è comunque possibile creare il proprio programma di riduzione delle mappe con qualsiasi linguaggio di programmazione come Ruby, Python, Perl e persino la programmazione C.
Bigdata e Hadoop sono molto richiesti nel mercato di oggi. Questo aumenterà di più nei prossimi giorni. Molta organizzazione si è già trasferita in Hadoop e coloro che non si sono trasferiti presto. C'è un rapporto attuale che afferma che le grandi aziende hanno iniziato a investire nell'analisi dei big data. Le previsioni del big data marketing sono sempre in aumento e non sono affatto di breve durata. A parte tutto ciò, i lavori in Hadoop e i big data offrono sempre alti salari rispetto ad altre tecnologie.
Principali aziende di Big Data e Hadoop
Di seguito sono elencate alcune delle migliori aziende che impiegano il maggior numero di risorse Hadoop.
- Yahoo
- Amazon
- Royal Bank of Scotland
- British Airways
- Expedia
- Walmart
Ci sono molte aziende che usano applicazioni per big data. Questi sono:
-
Nokia
Utilizza i componenti Cloudera e Hadoop come HDFS, HBase, Sqoop, Scribe per l'applicazione. Ha usato efficacemente i dati dell'utente per comprendere e migliorare l'esperienza dell'utente. Utilizza l'elaborazione dei dati e analisi complesse per la costruzione della mappa con traffico predittivo e modelli di elevazione a livelli.
-
SAS
Ha collaborato con Hadoop per aiutare i data scientist a ottenere una migliore comprensione fornendo un ambiente che offre esperienza visiva e interattiva, aiutando così a esplorare nuove tendenze. I programmi analitici estraggono approfondimenti significativi dai dati e la tecnologia in-memory consente un accesso più rapido ai dati.
Ci sono anche molte altre aziende che utilizzano piattaforme di big data per varie analisi. Si tratta dell'analisi dei dati di volo della scatola nera nel settore dell'aviazione, delle diverse analisi nel mercato azionario, ecc.
Vantaggi di Haddop
Di seguito sono riportati alcuni dei vantaggi di Hadoop
- Scalabile - A differenza del tradizionale RDBMS, è una piattaforma altamente scalabile in quanto può archiviare set di dati di grandi dimensioni in cluster distribuiti su hardware di prodotti che operano in parallelo.
- Conveniente - Il costo era troppo elevato per RDBMS per archiviare i dati che sono stati rilevati in Hadoop.
- Veloce e flessibile : offre l'accesso ai dati in modo rapido sul suo file system distribuito. Offre inoltre di ricavare spunti di business da dati semi-strutturati e non strutturati.
- Tolleranza agli errori : ogni volta che vengono inviati dati a un nodo, gli stessi dati vengono replicati in altri nodi a cui è possibile accedere in caso di errore del primo nodo.
Conclusione: cos'è Big Data e Hadoop
I dati sono in continua crescita e quindi ci sarà sempre bisogno di big data e Hadoop avrà senso da quei dati. Per questo motivo, i professionisti con competenze Hadoop troveranno sempre ampie opportunità nei prossimi giorni e possono essere una risorsa vitale per un'organizzazione che promuove il business e la loro carriera.
Articoli consigliati
Questa è stata una guida su ciò che è Big Data e Hadoop. Qui abbiamo discusso i concetti di base e i componenti di Big Data e Hadoop. Puoi anche leggere il seguente articolo per saperne di più -
- Esempi di Big Data Analytics
- Usi di Hadoop
- Guida alla visualizzazione dei dati
- Che cos'è l'analisi dei big data?