

Introduzione alla macchina Boltzmann limitata
La macchina Boltzmann limitata è un metodo in grado di trovare automaticamente modelli nei dati ricostruendo il nostro input. Geoff Hinton è il fondatore del deep learning. RBM è una rete superficiale a due strati in cui il primo è il visibile e il successivo è il livello nascosto. Ogni singolo nodo nel livello visibile è unito a ogni singolo nodo nel livello nascosto. La macchina Boltzmann soggetta a restrizioni è considerata limitata poiché due nodi dello stesso livello non formano una connessione. Un RBM è l'equivalente numerico del traduttore bidirezionale. Nel percorso forward, un RBM riceve l'input e lo converte in un set di numeri che codifica l'input. Nel percorso all'indietro, prende questo come risultato ed elabora questo insieme di input e li traduce al contrario per formare gli input rintracciati. Una rete super addestrata sarà in grado di eseguire questa transizione inversa con elevata veridicità. In due fasi, peso e valori hanno un ruolo molto importante. Consentono a RBM di decodificare le interrelazioni tra gli input e aiutano inoltre l'RBM a decidere quali valori di input sono più importanti nel rilevare gli output corretti.
Funzionamento della macchina Boltzmann limitata
Ogni singolo nodo visibile riceve un valore di basso livello da un nodo nel set di dati. Nel primo nodo dello strato invisibile, X è formata da un prodotto di peso e aggiunta a una distorsione. Il risultato di questo processo è alimentato dall'attivazione che produce la potenza del segnale di input dato o dell'uscita del nodo.
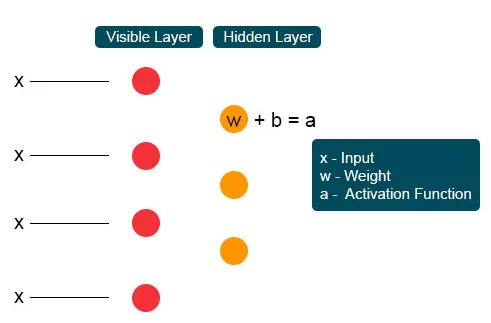
Nel processo successivo, diversi input si unirebbero in un singolo nodo nascosto. Ogni X è combinata dal peso individuale, l'aggiunta del prodotto viene clubbata ai valori e di nuovo il risultato viene passato attraverso l'attivazione per fornire l'output del nodo. In corrispondenza di ciascun nodo invisibile, ogni ingresso X è combinato con il peso individuale W. L'ingresso X ha qui tre pesi, che formano dodici insieme. Il peso formato tra il livello diventa un array in cui le righe sono precise per i nodi di input e le colonne sono soddisfatte per i nodi di output.
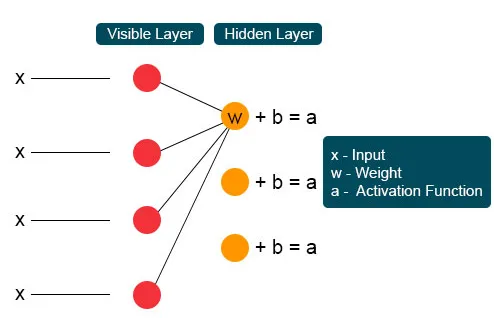
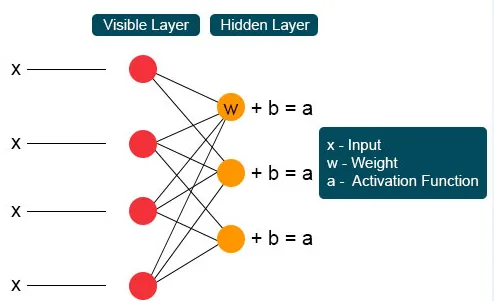
Ogni nodo invisibile ottiene quattro risposte moltiplicate per il loro peso. L'aggiunta di questo effetto viene nuovamente aggiunta al valore. Questo funge da catalizzatore affinché avvenga un processo di attivazione e il risultato viene nuovamente inviato all'algoritmo di attivazione che produce ogni singolo output per ogni singolo input invisibile.
Il primo modello derivato qui è il modello basato sull'energia. Questo modello associa energia scalare ad ogni configurazione della variabile. Questo modello definisce la distribuzione di probabilità attraverso una funzione energetica come segue,
(1) 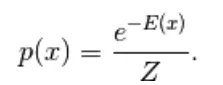
Qui Z è il fattore normalizzante. È la funzione di partizione in termini di sistemi fisici
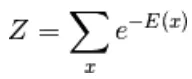
In questa funzione basata sull'energia segue una regressione logistica che il primo passo definirà il log. probabilità e il prossimo definirà la funzione di perdita come una probabilità negativa.
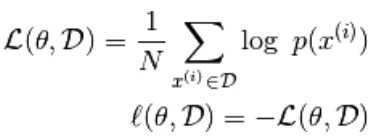
usando il gradiente stocastico, 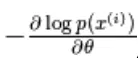 dove
dove 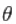 sono i parametri,
sono i parametri,
il modello basato sull'energia con un'unità nascosta è definito come 'h'
La parte osservata è indicata come 'x'
Dall'equazione (1), l'equazione dell'energia libera F (x) è definita come segue
(2) 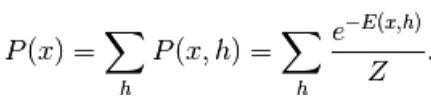
(3) 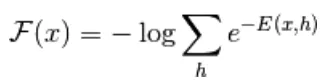
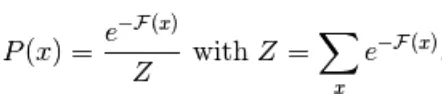
Il gradiente negativo ha la forma seguente,
(4) 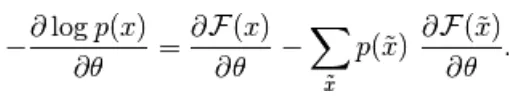
L'equazione sopra ha due forme, la forma positiva e negativa. Il termine positivo e negativo non è rappresentato dai segni delle equazioni. Mostrano l'effetto della densità di probabilità. La prima parte mostra la probabilità di ridurre l'energia libera corrispondente. La seconda parte mostra la riduzione della probabilità di campioni generati. Quindi il gradiente viene determinato come segue,
(5) 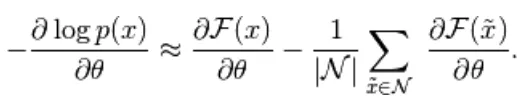
Qui N sono particelle negative. In questo modello basato sull'energia, è difficile identificare analiticamente il gradiente, in quanto include il calcolo di 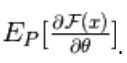
Quindi in questo modello EBM, abbiamo un'osservazione lineare che non è in grado di rappresentare i dati in modo accurato. Quindi, nel prossimo modello Restricted Boltzmann Machine, il livello nascosto ha più precisione e prevenzione della perdita di dati. La funzione energetica RBM è definita come,
(6) 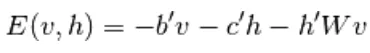
Qui, W è il peso che si collega tra strati visibili e nascosti. b è offset del layer visibile.c è offset del layer nascosto. convertendosi in energia libera,
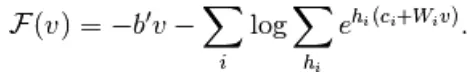
In RBM, le unità del livello visibile e nascosto sono completamente indipendenti che possono essere scritte come segue,
Dall'equazione 6 e 2, una versione probabilistica della funzione di attivazione dei neuroni,
(7) 
(8) 
È ulteriormente semplificato in
(9) 
Combinando l'equazione 5 e 9,
(10) 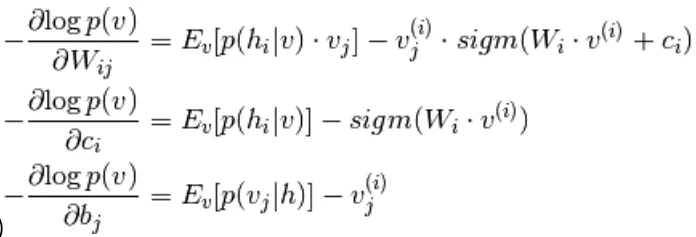
Campionamento in macchina Boltzmann limitata
Campionamento di Gibbs dell'articolazione di N variabili aleatorie 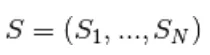 viene eseguito attraverso una sequenza di N passaggi secondari di campionamento del modulo
viene eseguito attraverso una sequenza di N passaggi secondari di campionamento del modulo 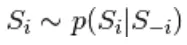 dove
dove
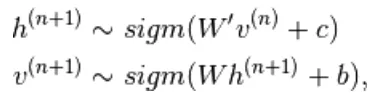
contiene 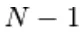 le altre variabili casuali in
le altre variabili casuali in 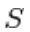 escluse.
escluse. 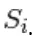
In RBM, S è un insieme di unità visibili e nascoste. Le due parti sono indipendenti che possono eseguire o bloccare il campionamento di Gibbs. Qui l'unità visibile esegue il campionamento e fornisce un valore fisso alle unità nascoste, mentre le unità nascoste simultaneamente forniscono valori fissi all'unità visibile tramite campionamento
Qui, 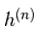 è un insieme di tutte le unità nascoste. Un esempio
è un insieme di tutte le unità nascoste. Un esempio 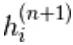 viene scelto casualmente come 1 (rispetto a 0) con probabilità,
viene scelto casualmente come 1 (rispetto a 0) con probabilità, 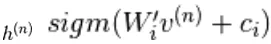 e similmente,
e similmente, 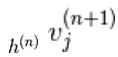 viene scelto casualmente per essere 1 (contro 0) con probabilità
viene scelto casualmente per essere 1 (contro 0) con probabilità 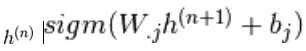
Divergenza contrastiva
È usato come catalizzatore per accelerare il processo di campionamento
Dal momento che ci aspettiamo di essere veri, ci aspettiamo 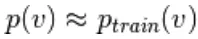 il valore di distribuzione deve essere vicino a P in modo da formare una convergenza con la distribuzione finale di P
il valore di distribuzione deve essere vicino a P in modo da formare una convergenza con la distribuzione finale di P
Ma la divergenza contrastiva non attende la convergenza della catena. Il campione viene ottenuto solo dopo il processo di Gibb, quindi impostiamo qui k = 1 dove funziona sorprendentemente bene.
Divergenza contrastiva persistente
Questo è un altro metodo per il modulo di campionamento approssimativo. È uno stato persistente per ogni metodo di campionamento che estrae nuovi campioni semplicemente modificando i parametri di K.
Strati della macchina Boltzmann limitata
La macchina Boltzmann limitata ha due strati, reti neurali poco profonde che si combinano per formare un blocco di reti di credenze profonde. Il primo livello è il livello visibile e l'altro livello è il livello nascosto. Ogni unità si riferisce a un cerchio simile a un neurone chiamato nodo. I nodi dal livello nascosto sono collegati ai nodi dal livello visibile. Ma due nodi dello stesso livello non sono collegati. Qui il termine Restricted si riferisce a nessuna comunicazione intralayer. Ogni nodo elabora l'input e prende la decisione stocastica se trasmettere l'input o meno.
Esempi
Il ruolo importante di RBM è una distribuzione di probabilità. Le lingue sono uniche nelle loro lettere e suoni. La distribuzione di probabilità della lettera può essere alta o bassa. In inglese, le lettere T, E e A sono ampiamente utilizzate. Ma in islandese, le lettere comuni sono A e N. non possiamo provare a ricostruire islandese con un peso basato sull'inglese. Porterà alla divergenza.
Il prossimo esempio sono le immagini. La distribuzione di probabilità del loro valore in pixel differisce per ogni tipo di immagine. Possiamo considerare che ci sono due immagini Elephant and Dog per i nodi di input di rimorchio, il passaggio in avanti di RBM genererà una domanda come se dovessi generare un nodo pixel forte per il nodo elefante o il nodo cane ?. Quindi il passaggio all'indietro genererà domande come per elefante, come devo aspettarmi una distribuzione di pixel? Quindi, con probabilità congiunta e attivazione prodotta dai nodi, costruiranno una rete con co-occorrenza congiunta come grandi orecchie, tubo grigio non lineare, orecchie floscio, rughe sono l'elefante. Quindi RBM è il processo di apprendimento profondo e visualizzazione che formano due principali pregiudizi e agiscono sul loro senso di attivazione e ricostruzione.
Vantaggi della macchina Boltzmann limitata
- La macchina Boltzmann limitata è un algoritmo applicato utilizzato per classificazione, regressione, modellazione di argomenti, filtro collaborativo e apprendimento delle funzionalità.
- La macchina Boltzmann limitata è utilizzata per la neuroimaging, la ricostruzione di immagini sparse nella pianificazione delle mine e anche nel riconoscimento del bersaglio radar
- RBM in grado di risolvere il problema dei dati sbilanciati con la procedura SMOTE
- RBM trova i valori mancanti nel campionamento di Gibb che viene applicato per coprire i valori sconosciuti
- RBM risolve il problema delle etichette rumorose con i dati non corretti delle etichette e i suoi errori di ricostruzione
- Il problema dei dati non strutturati viene corretto dall'estrattore di funzionalità che trasforma i dati grezzi in unità nascoste.
Conclusione
L'apprendimento profondo è molto potente, che è l'arte di risolvere problemi complessi, è ancora una stanza da migliorare e complessa da implementare. Le variabili libere devono essere configurate con cura. Le idee alla base della rete neurale erano difficili in precedenza, ma oggi il deep learning è il piede dell'apprendimento automatico e dell'intelligenza artificiale. Quindi RBM offre uno sguardo agli enormi algoritmi di deep learning. Si occupa dell'unità base di composizione che progressivamente si è trasformata in molte architetture popolari e ampiamente utilizzata in molti settori su larga scala.
Articolo raccomandato
Questa è stata una guida alla macchina Boltzmann riservata. Qui discutiamo del suo funzionamento, campionamento, vantaggi e livelli della macchina Boltzmann limitata. Puoi anche consultare i nostri altri articoli suggeriti per saperne di più _
- Algoritmi di apprendimento automatico
- Architettura di apprendimento automatico
- Tipi di apprendimento automatico
- Strumenti di apprendimento automatico
- Implementazione di reti neurali