

Panoramica dei tipi di clustering
Prima di apprendere i tipi di clustering, comprendiamo cos'è il clustering e perché è così importante nel settore dell'apprendimento automatico in questo momento.
Che cos'è il clustering? Il clustering è un processo in cui l'algoritmo divide i punti di dati in un determinato numero di gruppi in base al principio che punti di dati simili rimangono vicini tra loro e rientrano nello stesso gruppo.
Perché è così importante ora? Cerchiamo di capire che, ad esempio, ad esempio, esiste un negozio di abbigliamento online e vogliono capire meglio i loro clienti in modo da poter rendere più efficace la loro strategia pubblicitaria. Non è possibile per loro avere un tipo unico di strategia per ogni cliente, invece di ciò che possono fare è dividere i clienti in un certo numero di gruppi (in base ai loro acquisti precedenti) e avere una strategia separata di gruppi separati. Questo rende il business più efficace, questo è il motivo per cui il clustering è importante nel settore ora.
Tipi di clustering
In generale i metodi di tecniche di clustering sono classificati in due tipi: metodi hard e metodi soft. Nel metodo di clustering duro, ogni punto dati o osservazione appartiene a un solo cluster. Nel metodo del soft clustering, ciascun punto dati non apparterrà completamente a un cluster, ma può essere un membro di più di un cluster e ha un insieme di coefficienti di appartenenza corrispondenti alla probabilità di trovarsi in un determinato cluster.
Attualmente, ci sono diversi tipi di metodi di clustering in uso, qui in questo articolo vediamo alcuni di quelli importanti come il clustering gerarchico, il clustering di partizionamento, il cluster fuzzy, il clustering basato sulla densità e il clustering basato sul modello di distribuzione. Ora discutiamo ciascuno di questi con un esempio:
1. Partizionamento del clustering
Il partizionamento del clustering è un tipo di tecnica di clustering, che divide il set di dati in un determinato numero di gruppi. (Ad esempio, il valore di K in KNN e verrà deciso prima di addestrare il modello). Può anche essere chiamato come metodo basato sul centroide. In questo approccio il centro del cluster (centroide) è formato in modo tale che la distanza dei punti dati in quel cluster sia minima quando calcolata con altri centroidi del cluster. Un esempio più popolare di questo algoritmo è l'algoritmo KNN. Ecco come appare un algoritmo di clustering di partizionamento
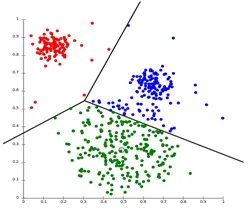
2. Clustering gerarchico
Il clustering gerarchico è un tipo di tecnica di clustering, che divide tale set di dati in un numero di cluster, in cui l'utente non specifica il numero di cluster da generare prima di addestrare il modello. Questo tipo di tecnica di clustering è anche noto come metodi basati sulla connettività. In questo metodo, il semplice partizionamento del set di dati non verrà eseguito, mentre ci fornisce la gerarchia dei cluster che si uniscono tra loro dopo una certa distanza. Dopo aver eseguito il clustering gerarchico sul set di dati, il risultato sarà una rappresentazione ad albero dei punti di dati (Dendogramma), che sono divisi in cluster. Ecco come appare un cluster gerarchico dopo l'allenamento
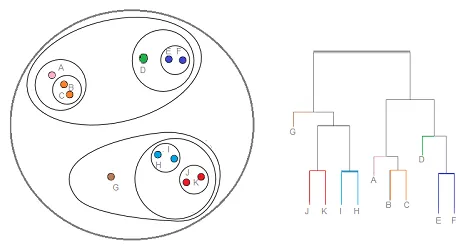
Link alla fonte: Clustering gerarchico
Nel clustering di partizionamento e nel clustering gerarchico, una delle principali differenze che possiamo notare è nel clustering di partizionamento che pre-specificheremo il valore di quanti cluster vogliamo dividere il set di dati e non pre-specificiamo questo valore nel clustering gerarchico .
3. Clustering basato sulla densità
In questo raggruppamento, i cluster di tecniche saranno formati dalla segregazione di varie regioni di densità in base alle diverse densità nel diagramma dei dati. Il clustering spaziale basato sulla densità e l'applicazione con rumore (DBSCAN) è l'algoritmo più utilizzato in questo tipo di tecnica. L'idea principale alla base di questo algoritmo è che dovrebbe esserci un numero minimo di punti che contengano nelle vicinanze di un dato raggio per ciascun punto nel cluster. Finora nelle tecniche di clustering sopra discusse, se osservi attentamente possiamo notare una cosa comune in tutte le tecniche che hanno la forma dei grappoli formati sono sferiche o ovali o concave. DBSCAN può formare cluster in forme diverse, questo tipo di algoritmo è più adatto quando il set di dati contiene rumore o valori anomali. Ecco come appare un algoritmo di clustering spaziale basato sulla densità dopo l'allenamento.
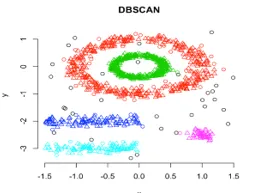
Collegamento di origine: clustering basato sulla densità
4. Clustering basato sul modello di distribuzione
In questo tipo di clustering, i cluster di tecniche vengono formati identificando la probabilità che tutti i punti dati nel cluster provengano dalla stessa distribuzione (normale, gaussiana). L'algoritmo più popolare in questo tipo di tecnica è il clustering Expectation-Maximization (EM) che utilizza Gaussian Mixture Models (GMM).
Le normali tecniche di clustering come il clustering gerarchico e il clustering di partizionamento non si basano su modelli formali, KNN nel clustering di partizionamento produce risultati diversi con valori K diversi. Poiché KNN e KMN considerano la media per il centro del cluster, in alcuni casi non è più adatto con i modelli di miscela gaussiana presumiamo che i punti dati siano distribuiti gaussiani, in questo modo abbiamo due parametri per descrivere la forma della media dei cluster e la deviazione standard. In questo modo a ciascun cluster viene assegnata una distribuzione gaussiana, per ottenere i valori ottimali di questi parametri (media e deviazione standard) viene utilizzato un algoritmo di ottimizzazione chiamato Expectation Maximization. Ecco come si presenta EM - GMM dopo l'allenamento.
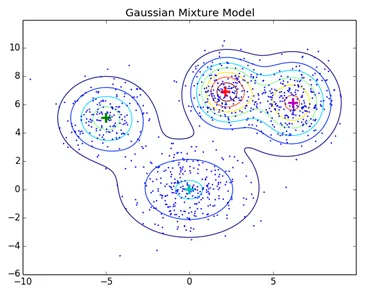
Collegamento di origine: clustering basato sul modello di distribuzione
5. Clustering fuzzy
Appartiene a un ramo di tecniche di clustering dei metodi soft, mentre tutte le tecniche di clustering sopra menzionate appartengono a tecniche di clustering dei metodi rigidi. In questo tipo di tecnica di clustering punti vicini al centro, forse una parte dell'altro cluster in misura maggiore rispetto ai punti ai margini dello stesso cluster. La probabilità di un punto appartenente a un dato cluster è un valore compreso tra 0 e 1. L'algoritmo più popolare in questo tipo di tecnica è FCM (Fuzzy C-significa algoritmo) Qui, il centroide di un cluster viene calcolato come media di tutti i punti, ponderato per la loro probabilità di appartenere al cluster.
Conclusione - Tipi di clustering
Queste sono alcune delle diverse tecniche di clustering attualmente in uso e in questo articolo abbiamo trattato un algoritmo popolare in ciascuna tecnica di clustering. Dobbiamo scegliere il tipo di tecnologia che utilizziamo, in base al nostro set di dati e ai requisiti che dobbiamo soddisfare.
Articoli consigliati
Questa è stata una guida ai tipi di clustering. Qui discutiamo diversi tipi di clustering con i loro esempi. Puoi anche dare un'occhiata ai seguenti articoli per saperne di più -
- Algoritmo di clustering gerarchico
- Clustering in Machine Learning
- Tipi di algoritmi di apprendimento automatico
- Tipi di tecniche di analisi dei dati
- Come utilizzare e rimuovere la gerarchia in Tableau?
- Guida completa ai tipi di analisi dei dati